苹果手机实况照片怎么关闭_苹果手机相机Live Photo关闭设置一键搞定
2026-06-25 3367116
2024-10-09 0
11月16日消息,正在举行的微软Iginte全球技术大会上,微软发布一系列AI相关的全新优化模型、开发工具资源,帮助开发者更深入地释放硬件性能,拓展AI场景。
尤是对于当下在AI领域占据绝对主导地位的NVIDIA来说,微软这次送上了一份大礼包,无论是面向OpenAI Chat API的TensorRT-LLM封装接口,还是RTX驱动的性能改进DirectML for Llama 2,以及其他热门大语言模型(LLM),都可以在NVIDIA硬件上获得更好的加速和应用。
其中,TensorRT-LLM是一款用于加速LLM推理的库,可大大提升AI推理性能,还在不断更以支持越来越多的语言模型,而且它还是开源的。
就在10月份,NVIDIA也发布了面向Windows平台的TensorRT-LLM,在配备RTX 30/40系列GPU显卡的台式机、笔记本上,只要显存不少于8GB,就可以更轻松地完成要求严苛的AI工作负载。
现在,Tensor RT-LLM for Windows可以通过全新的封装接口,与 OpenAI 广受欢迎的聊天 API 兼容,因此可以在本地直接运行各种相关应用,而不需要连接云端,有利于在 PC 上保留私人和专有数据,防范隐私泄露。
只要是针对TensorRT-LLM优化过的大语言模型,都可以与这一封装接口配合使用,包括Llama 2、Mistral、NV LLM,等等。
对于开发者来说,无需繁琐的代码重写和移植,只需修改一两行代码,就可以让AI应用在本地快速执行。
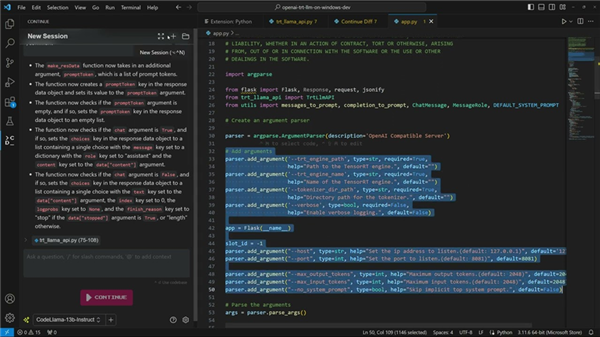 ↑↑↑基于TensorRT-LLM的微软Visual Studio代码插件——Continue.dev编码助手
↑↑↑基于TensorRT-LLM的微软Visual Studio代码插件——Continue.dev编码助手
本月底还会有TensorRT-LLM v0.6.0版本更新,将会在RTX GPU上带来最多达5倍的推理性能提升,并支持更多热门的 LLM,包括全新的70亿参数Mistral、80亿参数Nemotron-3,让台式机和笔记本也能随时、快速、准确地本地运行LLM。
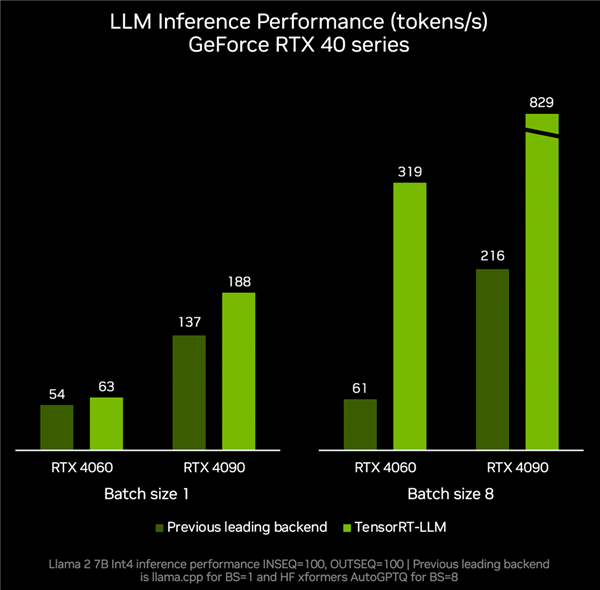
根据实测数据,RTX 4060显卡搭配TenroRT-LLM,推理性能可以跑到每秒319 tokens,相比其他后端的每秒61 tokens提速足足4.2倍。
RTX 4090则可以从每秒tokens加速到每秒829 tokens,提升幅度达2.8倍。
基于强大的硬件性能、丰富的开发生态、广阔的应用场景,NVIDIA RTX正成为本地端侧AI不可或缺的得力助手,而越来越丰富的优化、模型和资源,也在加速AI功能、应用在上亿台RTX PC上的普及。
目前已经有400多个合作伙伴发布了支持RTX GPU加速的AI应用、游戏,而随着模型易用性的不断提高,相信会有越来越多的AIGC功能出现在Windows PC平台上。
苹果手机实况照片怎么关闭_苹果手机相机Live Photo关闭设置一键搞定
2026-06-25 3367116
苹果大幅拓展iPhone产品线:2027年秋季前规划推出至少7款
2026-06-25 3367094
果粉情何以堪!苹果计划对iPhone 18外形大调整:弃药丸状挖孔 改用左上角单打孔
2026-06-25 3367093
iPhone17Pro如何开启勿扰模式_iPhone17Pro勿扰模式设置与定时开启方法说明
2026-06-25 3367092
iPhone11怎么查高铁WiFi覆盖情况_iPhone11查高铁WiFi覆盖情况【功能】
2026-06-25 3367090