Claude Code 并发编程、多线程开发全教程:一键规避死锁、竞态:线上高并发稳定运行
2026-06-29 3372435
2026-05-21 0
来自清华大学、无问芯穹、上海交通大学等机构的研究团队提出Think-at-Hard(TaH):一种面向小模型的选择性潜空间迭代方法,让 Looped Transformer 只在真正困难的 token 上多想一步,在跳过 93% 的额外迭代的同时,于 9 个数学、问答、代码基准上取得 3.0%–6.8% 的稳定提升。
本文的共同第一作者为清华大学电子系 NICS-EFC 实验室四年级直博生傅天予和大四本科生尤忆晨,并与无问芯穹合作完成。
随着 o1/R1 等推理模型的发展[1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。
但一个问题很少被认真讨论:模型真的有必要在每个 token 上都多想吗?
对于参数受限的小模型来说[4][5],这个问题尤其关键。小模型成本低、速度快、适合边缘部署,但在数学、代码和问答任务中,往往会因为少数关键 token 预测错误,让整条推理路径偏离正确方向。已有的 Looped Transformer[6][7][8]试图缓解这一问题:他们在生成每个 token 前,把最后一层的隐藏状态送回模型做额外的潜空间迭代,相当于在不增加参数的情况下为每个 token 增加计算深度。
来自清华大学、无问芯穹、上海交通大学等机构的研究团队在论文中发现,事情没这么简单:相当一部分 token 在第一次前向时已经预测正确,后续的潜空间迭代反而可能把正确的预测改错。论文将这一现象命名为latent overthinking,也就是「潜空间过度思考」。
基于这一观察,作者提出Think-at-Hard(TaH):一种选择性潜空间迭代的 Looped Transformer。通过后训练,让标准模型变为 Looped Transformer,且只在真正困难的 token 上增加算力。本工作入选 ICLR LIT Workshop Best Paper Shortlist,并被 ICML 2026 接收。

潜空间迭代可以把错误预测改对,也会把正确预测改错
论文的核心贡献在于:
揭示并量化了 Looped Transformer 中的潜空间过度思考 (latent overthinking) 现象,指出统一深度的潜空间迭代会同时带来「改对」和「改错」。提出 TaH,通过轻量级 iteration decider、duo-causal attention 与 depth-aware LoRA,实现 token 级动态思考。在 9 个数学、问答、代码基准测试上稳定取得提升;TaH 平均只让约 7% 的 token 进入第二轮迭代,相比所有 token 均二次迭代,其基准测试精度反而提升 3.8-4.4%。
本工作现已开源,欢迎交流讨论。

论文标题:Think-at-Hard: Selective Latent Iterations to Improve Reasoning Language Models代码链接:https://github.com/thu-nics/TaH主页链接:https://fuvty.github.io/TaH_project_page论文链接:https://arxiv.org/pdf/2511.08577
核心洞见
迭代计算简单 token 反而损害模型性能
R2R 等前序工作指出,在语言模型的推理过程中,并不是所有 token 都同等重要[10][11]。真正决定推理路径的,往往是少数关键位置:转折、因果连接、中间结论等。
为了量化这种选择性迭代的潜力,作者构造了一个oracle 策略:仅当模型第一次预测某个 token 出错时,才让它继续在潜空间迭代;如果第一次已经预测正确,就直接输出。实验显示,仅靠这个 oracle,模型在下游任务上最多就能换来 7.3% 的性能提升,而且只需要让大约11–19%的 token 二次迭代;如果再换上为选择性迭代优化的 TaH 架构,oracle 带来的提升甚至超过25%。
这意味着推理时的计算动态分配应该细化到 token 级别:难题里也有简单 token,简单题里同样可能出现关键 token。更关键的是,对简单 token 强行多算不仅浪费算力,还会让一部分本来预测对的 token 在第二次迭代里被改错,即latent overthinking。
TaH
在困难处停下来多想
为了解决这一问题,TaH 的思路非常直接:简单 token 快速输出,困难 token 继续迭代思考。
具体来说,TaH 在模型中加入一个轻量级 iteration decider(小型 MLP)。每完成一轮潜空间迭代后,decider 会基于backbone(模型骨干)的状态 *,预测一个继续概率。如果低于阈值,模型直接输出下一个 token;如果高于阈值,则进入下一轮潜空间迭代。
在实际推理中,TaH 平均每个 token 只执行 1.07 次迭代,相当于跳过了约 93% token 的二次迭代计算。相比「所有 token 都想两遍」的策略,TaH 把算力集中到了更可能出错、更可能影响推理方向的位置。
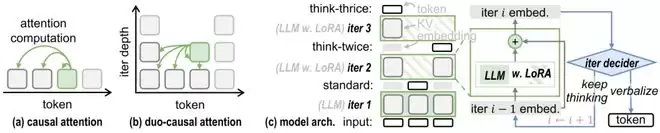
TaH 的 duo-causal 注意力机制以及模型架构;*decider 判定继续迭代的输入是 backbone 的浅层、中层和最终层的隐藏状态向量
为了让这种动态深度策略真正提升精度和效率,TaH 在模型架构和训练策略上都做了专门设计。
Duo-causal attention 架构。选择性迭代会把模型处理的序列结构从一维 token 序列,变成「token 位置 × 迭代深度」的二维网格。TaH 将大模型序列维度的因果注意力(causal attention)扩展到 token 维度和迭代深度的二维平面。如图所示,对于 token i 的第 d 次迭代,它的 query 可以注意到前序位置中深度不超过 d 的 key 和 value。
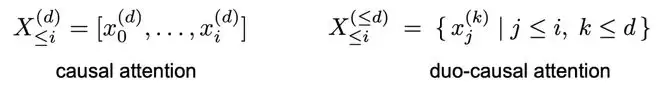
这样既允许跨迭代深度的信息流动,也保留了训练时序列维度计算的全并行性。
Depth-aware LoRA 架构。我们观察到,模型的第一次迭代主要负责常规下一个 token 预测(next-token prediction,NTP),更深层迭代则是在修正当前的困难 token。TaH 因此只在 d>1 的更深迭代中启用 LoRA adapter[12],让 LoRA 专注于学习困难 token 的修正方向。配合跨迭代的残差连接,深层迭代被自然地学习为「在前一轮基础上做修正」,而不是从零再预测一次。
两阶段训练。注意到,Decider 的判断目标依赖 backbone 的预测质量,而 backbone 的训练目标又依赖 decider 决定的迭代深度。因为这两者紧耦合,所以端到端训练并不稳定。TaH 采用解耦的两阶段方案:先用静态 oracle 策略训练 backbone 模型,再冻结 backbone,单独训练 decider 去模仿 oracle 的继续 / 停止决策。这种训练方法大大提升了训练的稳定性和收敛速度。
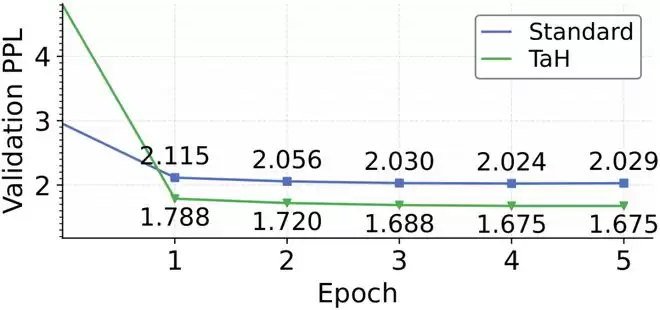
在 Qwen3-0.6B-Base 基础上训练,TaH 的收敛速度更快
结果
更少迭代,更强推理
论文在 Qwen3-0.6B、1.7B 和 4B 三个规模[3]的 backbone 上验证 TaH,训练数据来自 Open-R1[13]中数学、问答和代码的均衡混合,并在 GSM8K、MATH500、AMC23、AIME25、OlympiadBench、GPQA-Diamond、MMLU-STEM、HumanEval++ 和 MBPP++ 共 9 个基准上评测。所有方法 * 均使用完全相同的训练数据,在相同的预训练 backbone 模型上后训练。
准确性提升:在不增加参数预算的前提下显著超越基线。在 0.6B 和 1.7B 的严格参数限制下,TaH 相比标准 Qwen3 模型提升 3.0%-3.8%;TaH+ 在增加不超过 3% 额外参数(来自 decider 等)的情况下,将提升进一步扩大到 5.3%-6.2%。相比同类 Looped Transformer 方法 Ouro,TaH 取得 3.8–4.4% 的优势,TaH+ 的优势达到 6.1–6.8%。
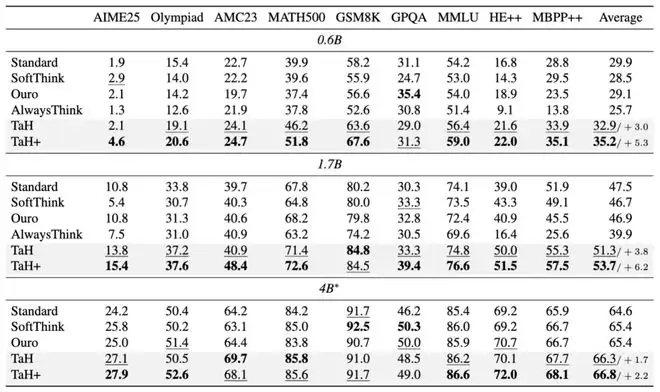
TaH 在几乎所有评测基准和模型尺寸上都实现了性能提升;*SoftThink 是推理时优化方法,无需训练
计算效率更高。TaH 平均每个 token 只执行 1.07 次迭代,完成问答的平均 FLOPs 和显存访问相比标准模型只多 4–5%。在真实解码测试中,TaH 相比始终迭代的 AlwaysThink 显存低 1.48 倍、解码快 2.48 倍,同时准确率反而更高。
迭代选择的语义解释。一个有意思的现象是,TaH 自动学到带有明显语义偏好的迭代行为。在验证集上,But 和 So 是最常被触发额外迭代的 token,概率分别达到 34% 和 18%。这些词大多对应转折、因果和推理方向的切换,正是复杂推理中最容易决定后续路径的位置。
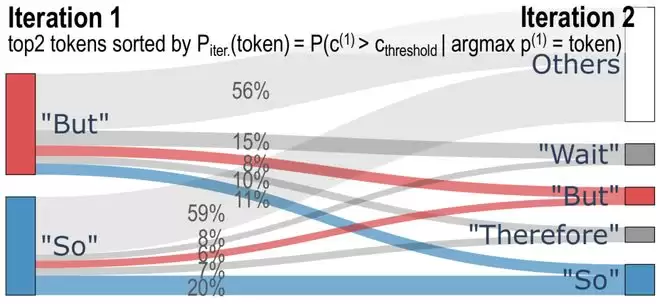
模型预测在两次迭代之间的变化
消融实验
为了验证 TaH 中每一项设计的必要性,我们做了系统的消融实验。
模型架构。把动态迭代深度的 decider 换成静态深度的 Always-1 或 Always-2,基准测试性能平均分别下降 6.1% 和 16.4%,说明选择性迭代本身就比统一深度更优;把 duo-causal 注意力机制替换为不同种的传统因果注意力,测试性能下降 5.4%-8.5%,说明跨迭代深度信息流动的重要性;移除 depth-aware LoRA 与跨迭代残差,效果下降了 4.9%,确认了在辅助不同迭代进行优化目标转变时,架构的重要性。
训练策略。相比 TaH 的两阶段训练,简单监督所有深度的预测会使基准测试性能下降 4.3%,说明不同迭代应承担不同优化目标;把训练时的迭代策略从静态 oracle 换成 decider-based 或动态 oracle 会因 backbone 与 decider 的耦合而不稳定甚至崩溃,证明了 TaH 两阶段训练的必要性
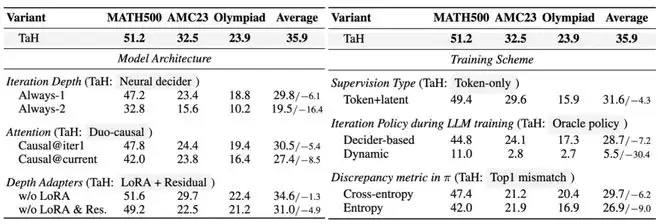
TaH 在模型架构和训练策略上的消融实验
总结与展望
TaH 的意义不止是提出了一个新的 Looped Transformer 变体和后训练方法,更重要的是,它探索了如何将 test-time scaling 推向更细的 token 粒度。TaH 表明,更智能的动态算力分配甚至可以比单纯使用更高算力的模型带来更好的效果,为后续研究带来启发。
参考文献
[1] Jaech, A., Kalai, A., Lerer, A., et al. OpenAI o1 system card. arXiv preprint arXiv:2412.16720, 2024.
[2] Guo, D., Yang, D., Zhang, H., et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
[3] Yang, A., Li, A., Yang, B., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025.
[4] Abdin, M., Aneja, J., Awadalla, H., et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219, 2024.
[5] Team, M., Xiao, C., Li, Y., et al. MiniCPM4: Ultra-efficient LLMs on end devices. arXiv preprint arXiv:2506.07900, 2025.
[6] Hutchins, D., Schlag, I., Wu, Y., Dyer, E., and Neyshabur, B. Block-recurrent transformers. Advances in Neural Information Processing Systems, 35:33248–33261, 2024.
[7] Saunshi, N., Dikkala, N., Li, Z., Kumar, S., and Reddi, S. J. Reasoning with latent thoughts: On the power of looped transformers. arXiv preprint arXiv:2502.17416, 2025.
[8] Zhu, R.-J., Wang, Z., Hua, K., et al. Scaling latent reasoning via looped language models. arXiv preprint arXiv:2510.25741, 2025.
[9] Wu, Y., Wang, Y., Ye, Z., Du, T., Jegelka, S., and Wang, Y. When more is less: Understanding chain-of-thought length in LLMs. arXiv preprint arXiv:2502.07266, 2025.
[10] Wang, S., Yu, L., Gao, C., et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning. arXiv preprint arXiv:2506.01939, 2025.
[11] Fu, T., Ge, Y., You, Y., et al. R2R: Efficiently navigating divergent reasoning paths with small-large model token routing. arXiv preprint arXiv:2505.21600, 2025.
[12] Hu, E. J., Shen, Y., Wallis, P., et al. LoRA: Low-rank adaptation of large language models. ICLR, 2024.
[13] Hugging Face. Open R1: A fully open reproduction of DeepSeek-R1, January 2025. URL https://github.com/huggingface/open-r1.
Claude Code 并发编程、多线程开发全教程:一键规避死锁、竞态:线上高并发稳定运行
2026-06-29 3372435
长上下文工程实践:GPT系列模型窗口机制深度解析与操作指南
2026-06-29 3372434
王兴兴GTC最新演讲:迈过具身智能临界点 还有三道坎-人工智能-ITBear科技资讯
2026-06-29 3372433
宇树科技王兴兴谈机器人痛点:AI大模型智能深度不足:实用性待飞跃-人工智能-ITBear比尔科技
2026-06-29 3372432
新浪人工智能热点小时报:2026年06月29日10时_今日实时人工智能热点速递
2026-06-29 3372428