千寻智能高阳团队提出Legato方案:让机器人动作如连音般流畅丝滑 成功入选RSS 2026
2026-05-29 3336041
2026-05-29 0
大模型性能优化迎来重大突破,蒙特利尔大学与DeepMind团队提出统一神经缩放定律,将多变量影响、阶段性转折等复杂因素纳入数学模型,为AI规模化训练提供新范式。


传统大模型缩放定律主要关注参数量、数据量和计算量对性能的影响。然而实际训练过程涉及更多关键因素:训练步数、处理token数、数据复用情况、batch size、学习率、初始化尺度等。这些变量之间并非简单线性关系,往往会产生复杂的交互效应。
研究人员发现,某些变量在特定区间会成为性能瓶颈,甚至导致曲线出现拐点。训练数据不足或过多epoch可能引发过拟合,学习率或初始化权重设置不当也会损害模型表现。为应对这些挑战,研究团队开发了统一神经缩放定律(UNSL),通过数学框架统一描述这些复杂现象。
该定律采用分层函数结构,在多维对数空间中将性能建模为平滑连接的超平面:
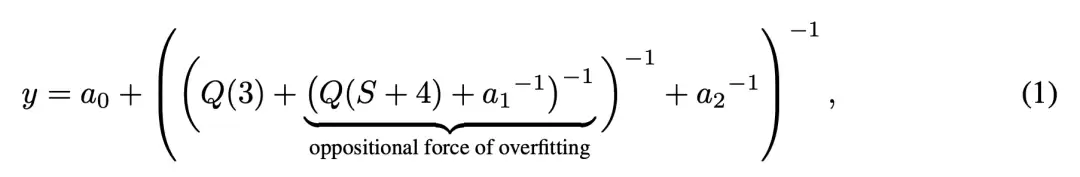
核心组件包括:
分层结构的设计理念如下:底层K函数处理log-log空间中的转折曲面;R函数区分整体趋势与瓶颈限制;Q函数纳入超参数影响;最外层则考虑性能极限和过拟合项。
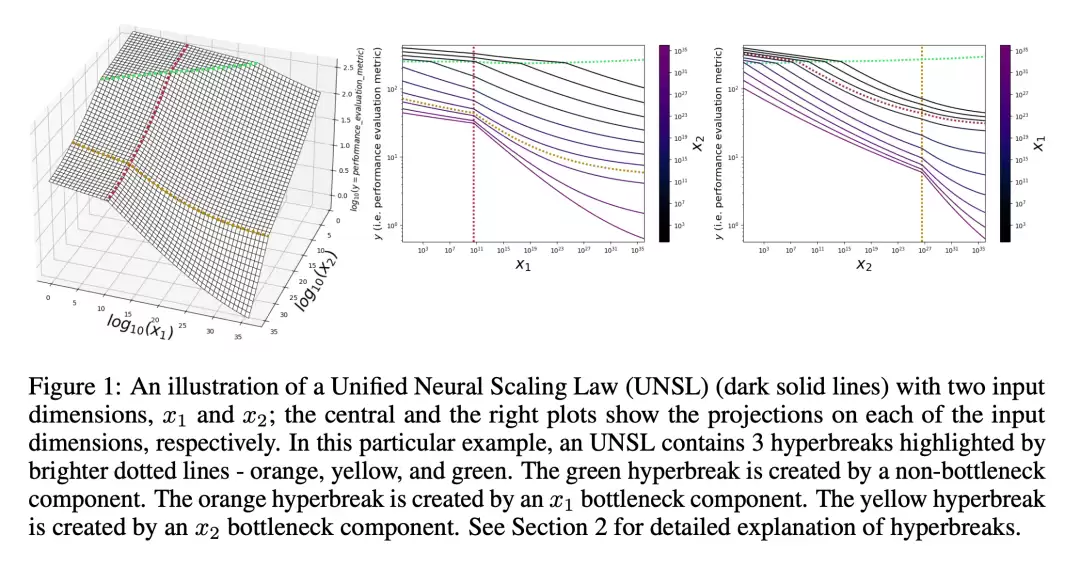
研究团队在视觉和语言任务上进行了系统验证:
三变量实验尤其凸显UNSL优势:

在强化学习、模型架构等扩展场景中,UNSL同样展现出色适应性,证明其广泛的应用潜力。

这项突破性研究为大模型训练提供了更精确的性能预测工具,其统一框架有望指导更高效的AI系统开发,推动深度学习规模化应用进入新阶段。