英伟达版MacBook Pro曝光:黄仁勋亲自操刀研发CPU!
2026-06-01 3337514
2026-06-01 0
计算机智能体在GUI操作与工具调用间的路径选择难题,已成为提升执行效率的关键瓶颈。复旦大学与通义实验室联合提出的ToolCUA框架,通过混合动作空间优化显著提升了任务完成质量。
传统计算机智能体主要依赖原子化GUI操作,如点击、输入等基础交互。虽然这类操作具备良好的泛化能力,但在处理复杂任务时存在明显缺陷:执行步骤冗长、误差容易累积,常常导致级联错误。相比之下,工具调用或API操作通常更为高效精准,能大幅简化操作流程。
实验发现一个反直觉现象:直接为强模型接入工具调用能力,并不总能带来性能提升。在混合动作空间中,智能体面临持续的选择困境:是采用通用但低效的GUI操作,还是选择高效但需特定条件的工具调用。
典型失败模式包括两种:工具使用不足(Tool underuse)和工具滥用(Tool overuse)。前者表现为智能体固守GUI操作而忽视更优工具,后者则是频繁但不恰当的调用工具。研究团队将这一问题定义为最优GUI-工具路径选择问题。
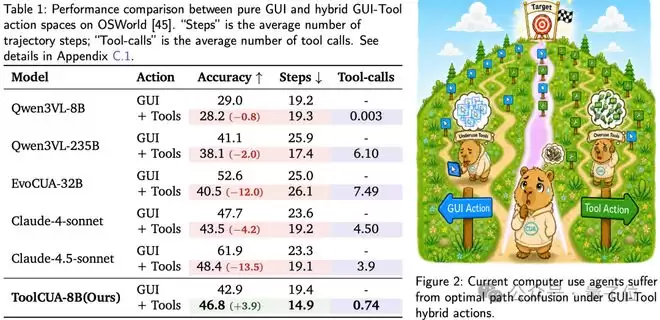
数据清晰展示了这一现象:Qwen3VL-8B几乎不使用工具,准确率反而下降;Qwen3VL-235B则过度依赖工具,虽然步骤减少但准确率降低。Claude系列模型同样出现类似情况,说明混合动作空间的核心挑战在于路径选择能力。
构建高质量的GUI-工具混合轨迹数据是首要挑战。真实工具接口往往存在应用局限和维护成本问题,而现有GUI数据多为纯操作轨迹,缺乏工具使用指导。
ToolCUA采用创新的数据合成流程:
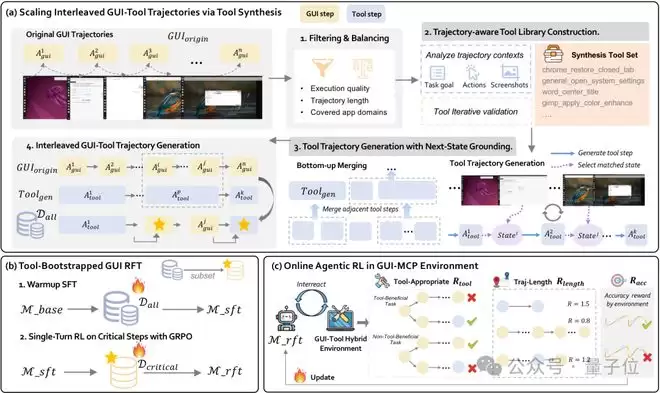
最终数据集包含约4000个独特工具,覆盖多级粒度。基于这些数据,ToolCUA执行工具引导的强化训练:先进行监督微调学习工具知识,再通过单步强化学习优化关键切换点的决策。
第二阶段聚焦完整任务中的路径选择优化。ToolCUA在真实混合环境中进行长程推演,通过专门的工具效率路径奖励机制引导学习:
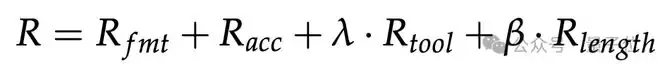
工具适当性奖励(R_tool)鼓励智能体在适合工具的任务中正确调用工具,在不适合的任务中避免滥用。路径效率奖励(R_length)则通过组内比较,推动模型发现更高效的执行路径。
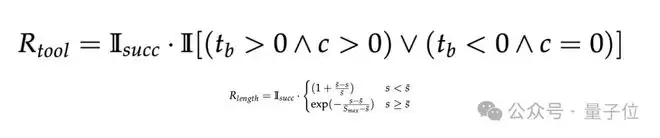
在OSWorld-MCP基准测试中,ToolCUA-8B取得46.85%的准确率,相比基线提升约66%。其平均完成步数仅14.93步,为所有模型中最低,工具调用率从8.41%提升至24.32%。
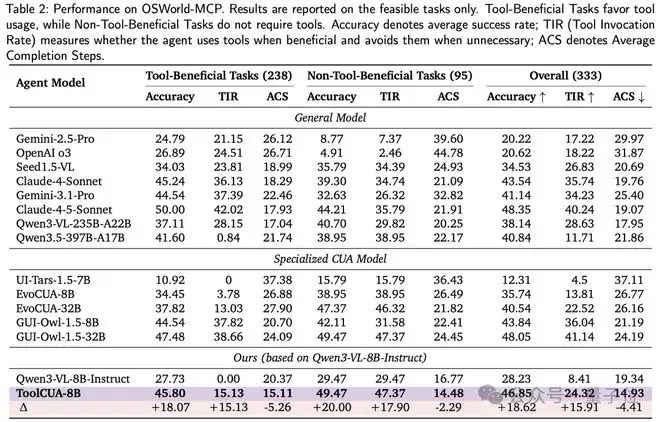
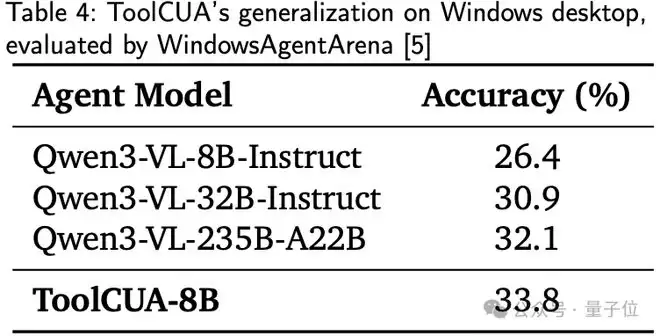
特别值得注意的是,在未参与训练的多应用任务和Windows平台测试中,ToolCUA仍保持优异表现,验证了其学习到的混合动作协调能力具有良好泛化性。
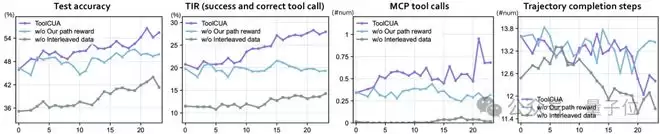
消融实验明确了三个关键结论:
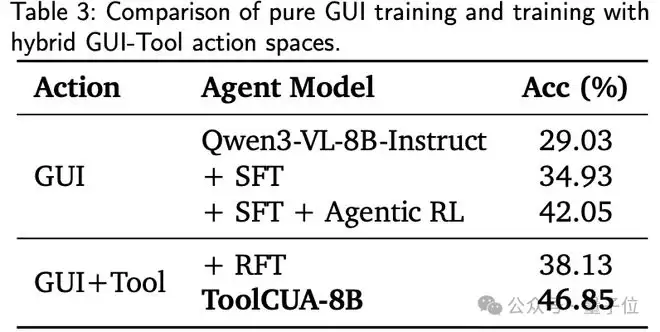
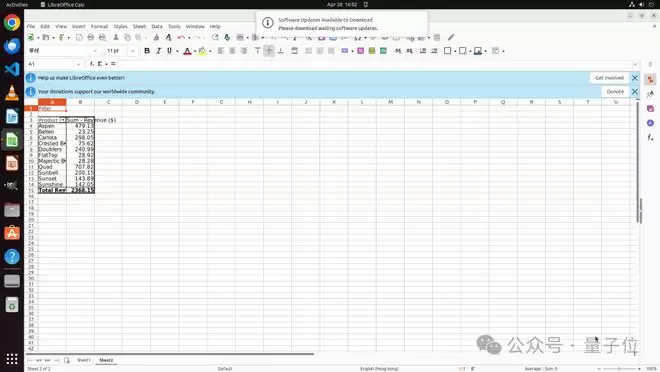
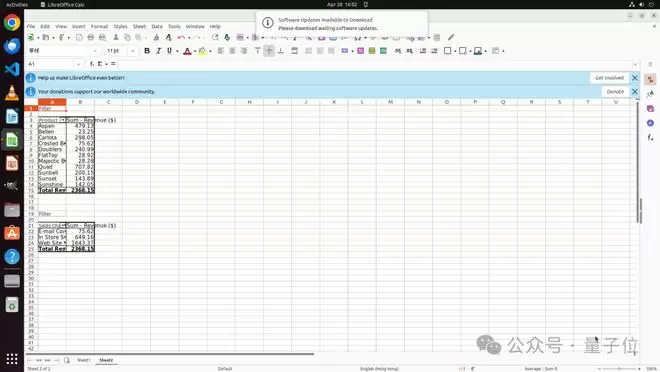
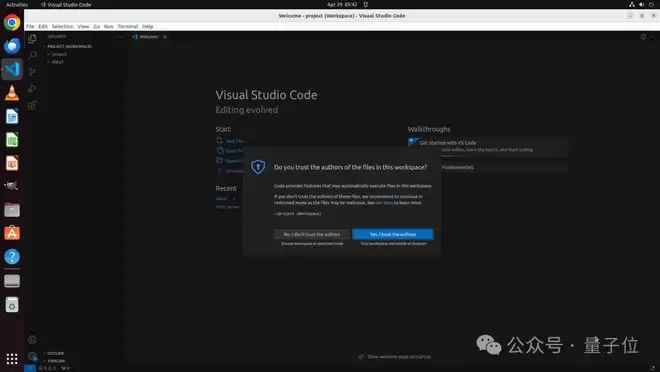
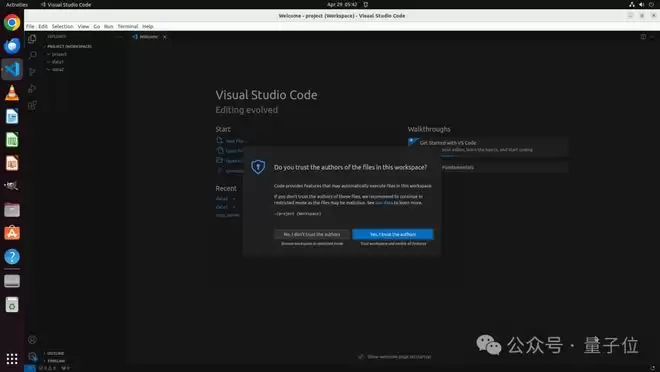
LibreOffice案例展示了工具在结构化操作中的优势:智能体通过工具调用直接创建数据透视表,避免了冗长的GUI导航。VS Code案例则体现了动态切换能力:先用工具添加文件夹,再切回GUI处理信任确认。
ToolCUA框架通过分阶段训练和专用奖励机制,有效解决了智能体在混合动作空间中的路径选择难题。其开源的代码与模型为计算机智能体领域提供了重要参考,展示了混合动作训练范式的巨大潜力。