突破传统范式:9位清华博士以具身本能重塑工业产线运行逻辑
2026-06-02 3338341
2026-06-02 0
2026年初,AI领域掀起上下文窗口长度竞赛,各大厂商纷纷突破百万级token处理能力。本文将深入探讨长上下文带来的KV缓存挑战及创新解决方案。
研究团队揭示了一个反直觉现象:输出相同的模型,其KV缓存压缩性可能天差地别。通过"词频统计"案例,他们展示了两种实现方式的本质区别。
第一种实现方式对每个token独立编码,通过注意力机制平均计算。这种看似自然的方法却存在致命缺陷:任何压缩都会破坏计算结果。数学证明显示,这种方式理论上不具备压缩容错能力。
第二种结构化实现则巧妙记录位置信息,即使压缩成单一向量也能通过校准恢复准确结果。理论上可将任意长度前缀压缩至一对KV向量而不损失精度。
KV-CAT训练方案的核心在于模拟压缩环境。研究人员将其比作"记忆障碍训练",迫使模型将关键信息内化为真正理解而非依赖完整缓存。
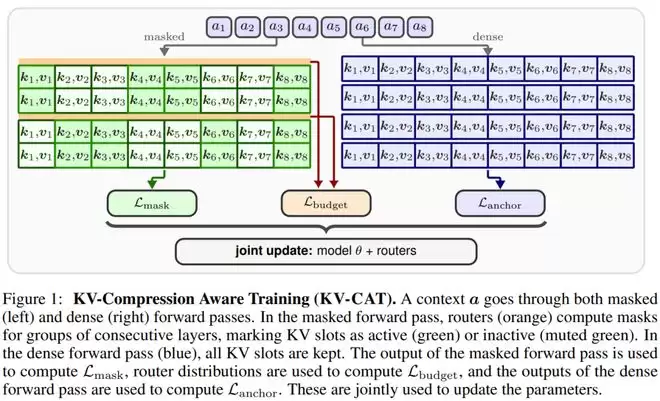
具体实现包含三个关键组件:轻量级路由器模块动态筛选KV槽位;双重计算机制同时进行全量和压缩计算;三部分训练目标确保效果。

在0.5B和1.5B参数的Qwen2.5模型上,KV-CAT展现出全面优势:
基础能力保持稳定,六个基准测试中波动不超过0.7个百分点;压缩效果显著提升,困惑度差距最多缩小3.21倍;检索准确率大幅跃升,0.5B模型从28%提升至47%;长文问答任务表现改善,最大提升幅度达39%。
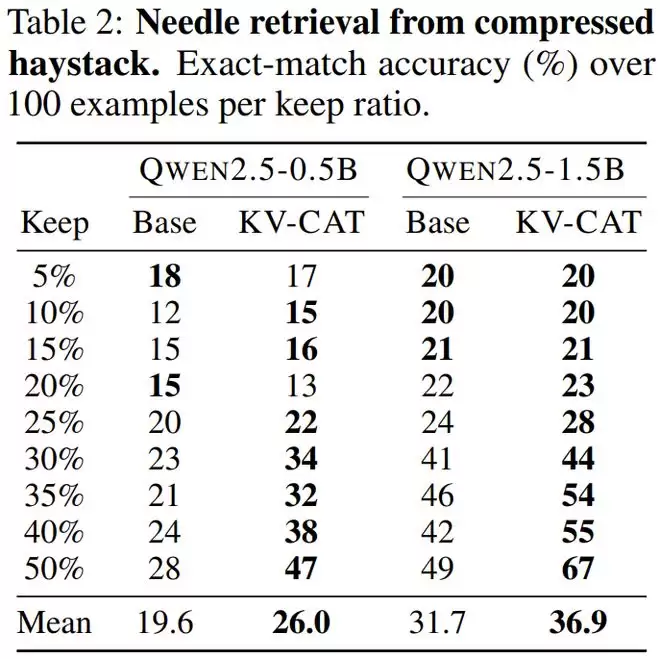
KV-CAT开创性地将压缩友好性融入模型训练,为突破显存瓶颈提供了新思路。虽然扩展到大模型仍需验证,但其"预防优于治疗"的理念必将影响未来AI系统设计。