小米米家首款枪灰色花洒正式发售:配备超大置物台与顶喷 售价999元
2026-06-03 3339687
2026-06-03 0
快手最新发布的多模态大模型Keye-VL-2.0-30B-A3B在视频理解领域取得突破性进展,通过创新架构实现了远超同级别模型的性能表现。

总参数30B、推理时只激活3B的多模态模型,在多项视频理解榜单上压过了200B+的开源大模型
01
引言
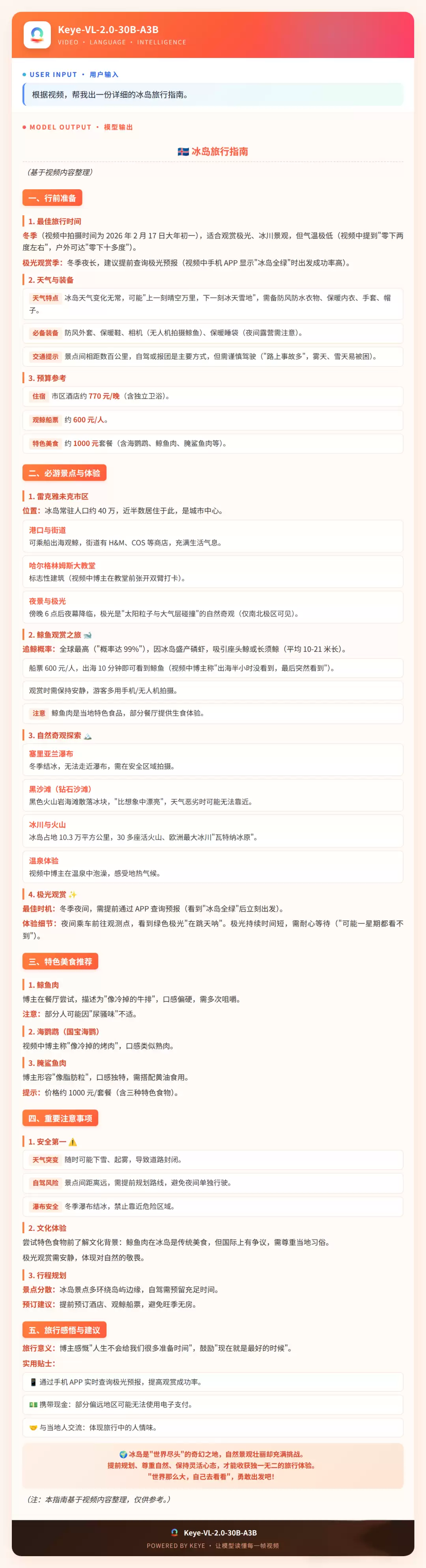
快手推出的Keye-VL-2.0-30B-A3B大模型展现出卓越的视频理解能力。面对9分钟冰岛旅行Vlog这类复杂视频内容,常规模型仅能生成表面描述,而该模型能深入分析场景转换、提取关键细节并提供实用建议。通过引入DSA架构,模型实现了256K超长上下文处理能力,在多项基准测试中超越规模更大的开源模型。
输入视频:
Keye-VL-2.0-30B-A3B能够捕捉"冻手"等细节提供保暖建议,理解猎奇美食评论给出文化体验推荐,并基于"雪地车祸"画面智能建议跟团游更安全。
开源地址:
02
视频理解:DSA落地多模态
视频理解的主要挑战在于长序列带来的计算负担和信息稀释问题。Keye-VL-2.0通过应用DSA技术,结合稀疏注意力和特征聚合,在处理长视频时能有效提取关键信息。这一创新使长序列Prefill成本降低50%,为大规模视频处理提供了高效解决方案。
TimeLens细粒度时序理解基准测试结果:
|
子任务 |
Keye-VL-2.0 |
Gemini-2.5-Pro |
Gemini 3 Flash |
|
Charades(日常动作) |
58.4 |
— |
61.2 |
|
ActivityNet(动作定位) |
58.5 |
58.1 |
57.0 |
|
QVHighlights(高光提取) |
70.1 |
— |
49.5 |
ActivityNet表现优于Gemini系列,QVHighlights领先Gemini 3 Flash达20.6分。
陶杯工艺视频分析示例(9分33秒):
模型准确识别了所有专业工序并与时间轴精准对应。

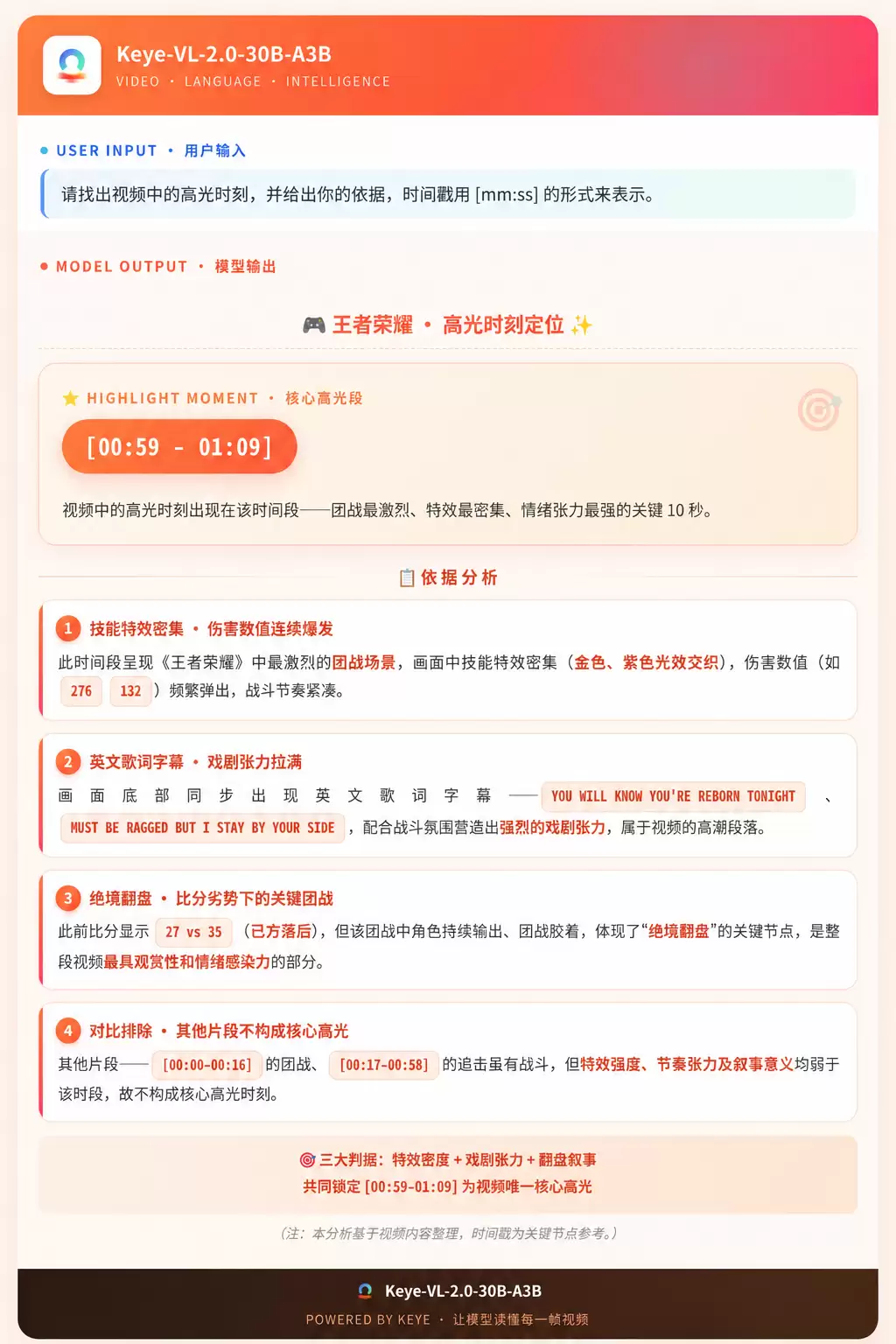
《王者荣耀》高光提取示例(1分09秒):
模型基于视觉特效、伤害数值和比分变化等综合因素,而非简单依赖击杀提示,准确识别了游戏中的关键战斗节点。
03
实现视频理解SOTA
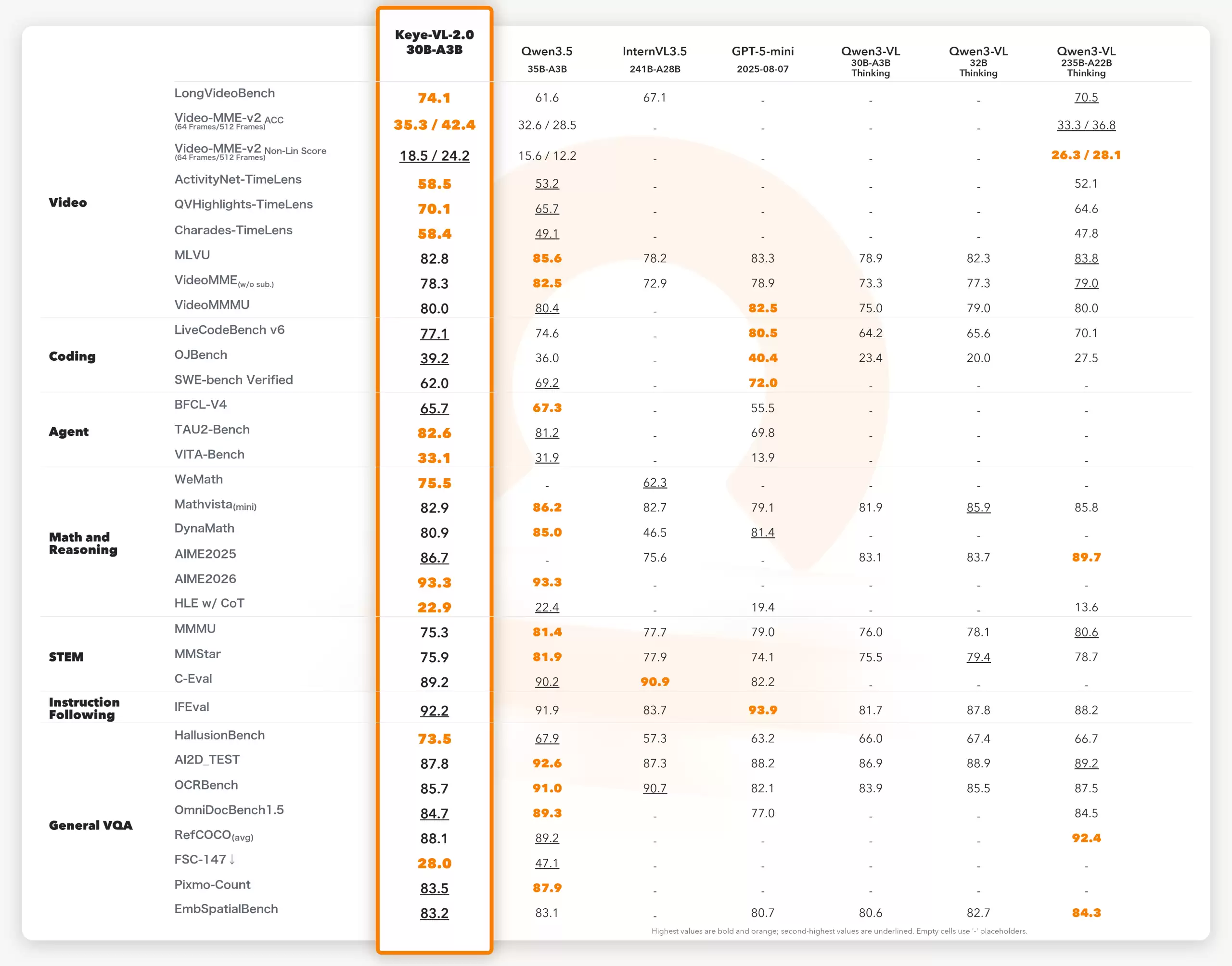
Keye-VL-2.0通过时空编码优化,在多项基准测试中达到30B级别最佳水平。VideoMME V2测试中,输入帧数从64增至512时,准确率提升7个百分点。LongVideoBench测试达到74.10分,超越更大规模的模型。
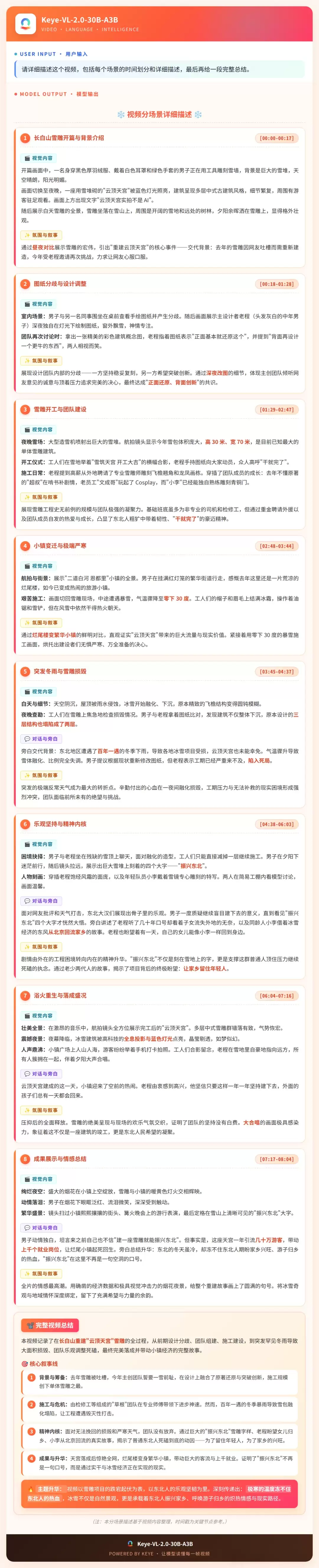
长白山纪录片分析示例(8分04秒):
04
Agent能力
模型首次内置多模态Agent机制,具备复杂的多步任务处理能力。在LivecodeBench v6测试中获得77.10分,部分超越200B+模型。TAU2-Bench测试中达到82.58分,展现出优秀的工具调用能力。
05
MOPD与Context-RL
MOPD技术有效解决了多任务学习中的遗忘问题,通过细粒度建模强化核心信号。Context-RL机制则构建了稠密奖励信号,显著降低了复杂场景下的幻觉倾向。这两项技术的结合使模型在各类任务中均获得全面提升。
06
模型部署
推荐使用预构建Docker镜像快速部署。启动服务后,可通过标准接口进行图像和视频的多模态处理,支持自定义帧采样参数设置。示例代码展示了如何调用API实现图像描述和视频分析功能。
Keye-VL-2.0-30B-A3B通过技术创新实现了视频理解的重大突破,为多模态AI应用开辟了新的可能性。