SQL 规范执行率提至 95%:得物数仓 Harness 实践全解析
2026-06-05 3342513
2026-06-05 0
NLPer 2026-06-04 16:06 江苏
腾讯微信团队提出了WeStar——一个轻量自适应的风格化 AI 助手框架,论文已被ACL 2026 Findings收录
大语言模型驱动的对话 Agent 正在被大规模部署到内容平台。在微信公众号、内容社区等场景中,一个核心需求是:AI 助手不仅要回答得准,还要回答得"像"——像这个账号一贯的说话风格。
然而,当账号数量达到百万级别时,挑战也随之而来:每个账号都有自己的历史文章、粉丝评论和互动风格。为每个账号单独微调模型,成本上完全不现实;用长 prompt 把历史文章塞进上下文,又会拖慢推理速度、稀释模型对注入信息和风格的把握能力。
围绕这一问题,腾讯微信团队提出了WeStar——一个轻量自适应的风格化 AI 助手框架,论文已被ACL 2026 Findings收录。WeStar 用一套共享基座模型加按风格簇动态激活的 LoRA 模块,实现了"一个模型服务百万账号"。
论文标题:One Agent to Serve All: a Lite-Adaptive Stylized AI Assistant for Millions of Multi-Style Official Accounts 论文链接:https://arxiv.org/abs/2509.17788 代码仓库:https://github.com/WeAgentAI/WeStar

公众号 AI 助手的场景看起来简单:用户提问,AI 根据账号的历史文章来回答。但这里的难点不在"能不能答",而在于"答得对不对味"。
一个科普类账号的回答,通常需要专业术语、强逻辑衔接、高权威性;一个生活类账号的回答,则需要亲切随意、短句表达、适量使用表情。同一个问题"如何看待这件事",不同的账号给出的回答风格应该截然不同。
现有方案主要有三条路:
CoT 提示(Chain-of-Thought):让模型先检索历史文章、再推理、再生成。优点是零训练成本,缺点是每次回答都要多轮生成,延迟显著增加,且风格把握不够精准。
逐账号微调:为每个账号单独训练模型。风格最贴合,但百万账号意味着百万次微调,计算和存储成本无法承受。
长 prompt 注入:把历史文章全文塞进 system prompt。信息量大,但 prompt 越长,模型对注入内容的把握越弱,且推理成本线性增加。
WeStar 的思路是:知识是账号级别的,但风格是可以聚类的。百万个账号不需要百万种风格,它们可以归入若干"风格簇",每个风格簇共享一套微调参数。
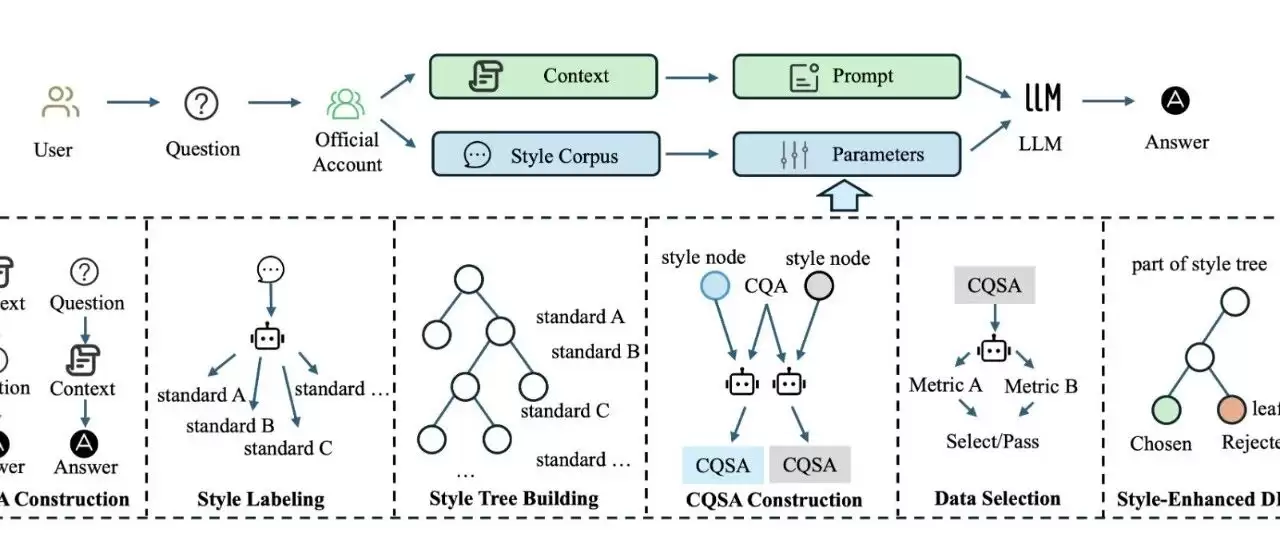
WeStar 的核心设计可以归纳为两条线并行:
知识注入:通过传统的 RAG(检索增强生成),从账号历史文章中检索相关内容,作为回答的知识支撑。
风格注入:通过PRAG(Parametric RAG),在推理时根据账号所属的风格簇动态激活对应的 LoRA 模块,让模型以该风格的"语气"来生成回答。
这里是关键创新。传统 RAG 做的事是"检索→拼接文本→喂给模型";WeStar做的事是"判定风格→激活参数→改变模型行为"。前者影响模型"知道什么",后者影响模型"怎么说"。
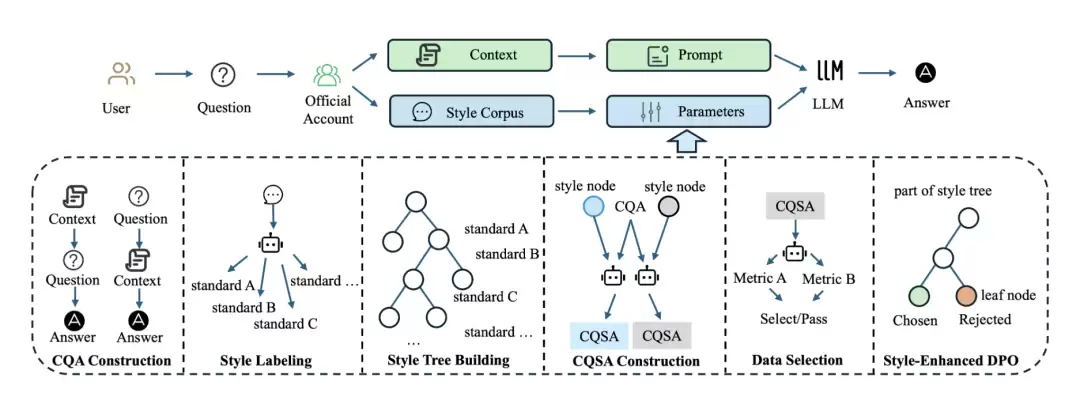
要让 LoRA 学会"风格",首先要有一套可操作的风格标签体系。WeStar 定义了 12 个风格维度:
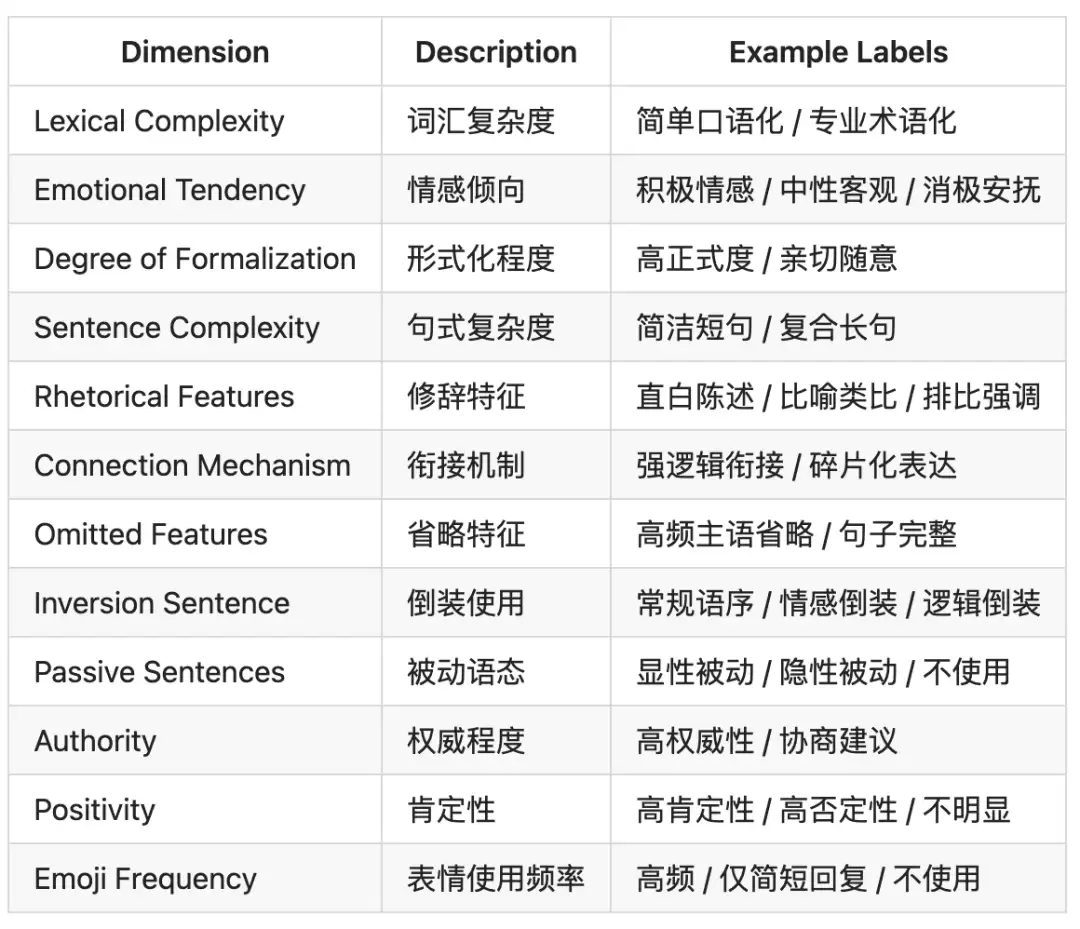
有了这套标签体系,每个账号的历史文章和评论回复都可以被标注为 12 维风格向量,再通过聚类算法构建风格树,将百万账号归入有限数量的风格簇。
WeStar 不要求为每个风格簇训练一个完整模型。它只训练 LoRA 低秩适配器——每个风格簇一份,参数量远小于全模型微调。推理时,系统根据请求账号的 biz_id 查到其所属风格簇,动态挂载对应的 LoRA 权重,整个过程对单个账号的额外计算开销极小。
这种"共享基座 + 按簇激活 LoRA"的方案,实现了风格多样性和参数效率之间的平衡。百万账号用的是一个 Qwen3-32B 基座模型,真正按账号变化的只是几份轻量 LoRA 模块。
有了风格簇和对应的 LoRA 参数,还需要一个训练目标来让 LoRA 真正学会该风格下的优质回答。WeStar 提出了SeDPO(Style-enhanced Direct Preference Optimization)。
传统 DPO 的做法是:同一个问题,一个"好回答"和一个"差回答"组成偏好对,让模型向"好回答"方向优化。SeDPO 的改进在于偏好对的构造策略:
正样本(chosen):来自目标风格簇的高分 CQSA(Contextual Question-Stylized Answer)数据。
负样本(rejected):同一个问题,但用的是兄弟风格簇的回答。
这意味着 SeDPO 的训练信号不只是"回答好不好",而是"这个风格下怎样回答是对的"。模型通过反复对比不同风格簇对同一问题的回答差异,逐渐学会风格边界。
此外,WeStar 还在论文中实验了 MDPO(Multi-cluster DPO)等变体,以验证不同偏好构造策略对风格学习的影响。
WeStar 的实验在两个维度上进行了验证:
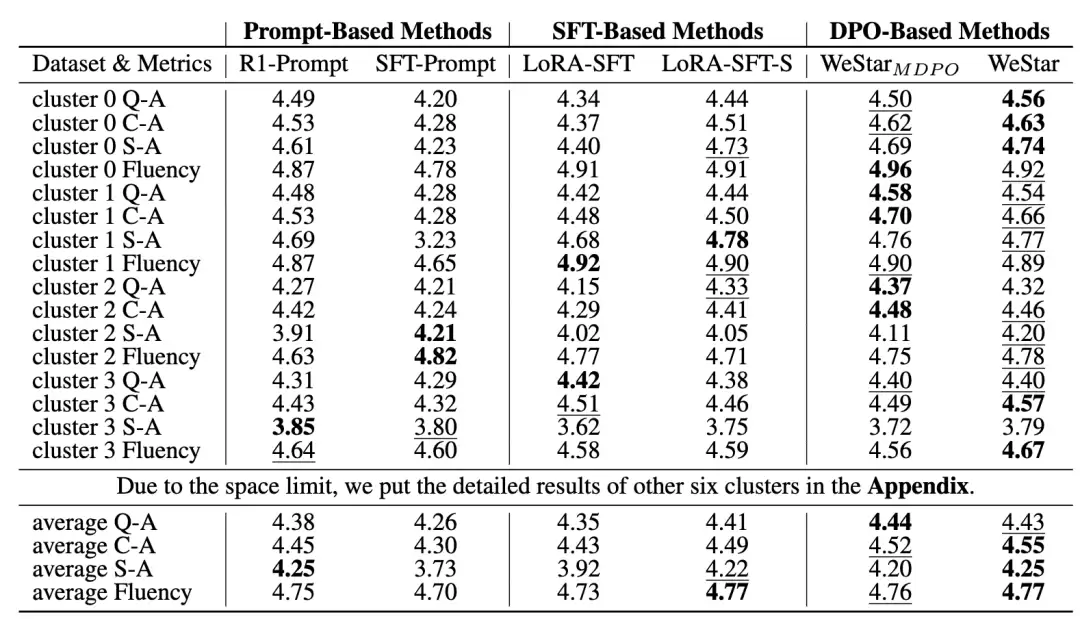
WeStar 在 Context–Answer 一致性和 Style–Answer 一致性两个核心维度上均取得最优。值得注意的是,LoRA-SFT 虽然回答质量不错,但风格一致性显著落后——说明仅做 SFT 远不足以让模型学会风格对齐。
PRAG 比纯 RAG 更懂风格:在风格一致性指标上,WeStar 比纯 prompt 注入方法提升明显。
SeDPO 比普通 DPO 更精准:用兄弟簇回答作为负样本,比随机采样负样本带来的风格区分度更高。
LoRA 足够了:不需要为每个账号训练模型,按风格簇共享 LoRA 的方案在大规模场景中效率与效果兼得。
WeStar 给行业的一个启示是:当 AI 助手需要大规模、多风格部署时,瓶颈往往不在模型能力本身,而在风格的高效表达与迁移。
传统思路是"给更强的模型写更好的 prompt"。WeStar 的思路是"让模型参数本身学会风格"。前者可解释性强但上限低,后者上限高但需要精巧的工程与训练设计。WeStar 用 LoRA + 风格树 + SeDPO 的组合,找到了一条在百万账号规模下可行的路径。
这背后指向一个更大的趋势:**AI 助手从"个性化"走向"规模化个性化"**。当一个模型需要同时服务科普博主、母婴达人、财经分析师、体育评论员时,真正稀缺的不是算力,而是让同一个模型在不同"身份"之间自如切换的能力。WeStar 的方法为这个问题提供了一个可复用的框架。
论文发表于 ACL 2026 Findings,代码已在 GitHub 开源。
进技术交流群请添加AINLP小助手微信(id: ainlp2)
请备注具体方向+所用到的相关技术点

关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括LLM、预训练模型、自动生成、文本摘要、智能问答、聊天机器人、机器翻译、知识图谱、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP小助手微信(id:ainlp2),备注工作/研究方向+加群目的。
