SQL 规范执行率提至 95%:得物数仓 Harness 实践全解析
2026-06-05 3342513
2026-06-05 0
原创 花叔 2026-06-04 16:07 天津


前几天,海外的AI圈和基础科学的学术圈有个传闻挺热闹的:尹希,哈佛史上最年轻的华人正教授,弦理论这门基础科学里最难啃方向的顶尖学者,据爆料离开哈佛去了OpenAI。当然,到目前为止OpenAI、哈佛和他本人都还没正式回应,也有人说他只是停薪留职去那边待一阵。
先说尹希是谁。他1983年生,12岁进中科大少年班,2006年拿到哈佛物理博士,2015年31岁晋升正教授,是哈佛史上最年轻的华人正教授之一。研究方向是弦理论和量子引力,物理学里最抽象、最难出成果的硬骨头,拿过斯隆研究奖和基础物理学突破奖的新视野奖,长期被同行看作有希望冲诺奖的苗子。就这么一个人,现在公开把宝押在AI上。
然后顺着这个传闻,我找到了个更有依据更有趣的信息。今年4月,哈佛校报写过一篇长文,讲AI怎么搅动理论物理。尹希在里面说,AI给他的提速「至少100倍」,几周里写出的代码,他自己写要花10年。他还说,不相信有任何一项人类智力能力是AI无法复制的。他最后还说:我自己有没有亲手得出那个解,是次要的,只要结果能被验证。
一个站在基础科学最顶端的人,如此相信AI和使用AI,我觉得还真挺特别的。所以借此我也很想看看,现在AI到底是怎么钻进实验室、帮人类做科学研究的?
带着这份好奇,我翻了2026上半年一批论文,发现AI在高校实验室里的渗透还真挺不错了。它开始干一些人类自己都不太擅长、甚至干不了的事:读懂基因组里没人看得懂的暗区,在三天里造出上千万条蛋白数据,生成几千个「平行版本的2023年夏天」去找那个本可能更热的极端值。
这比AI写代码更值得关注。写代码是把存量知识自动化,做科学是去碰人类还不知道的东西。AI for Science(AI4S)这两年本就热闹,也为了满足自己的好奇心,我想把这半年各个学科里真实发生的事一件件讲清楚,最后再回到尹希那句话,说说我作为一个天天指挥AI干活的人,到底怎么看「我有没有亲手得出解是次要的」这种判断。
读了几十篇之后,我发现表面上五花八门的成果,底下其实是三条线在反复出现。
第一条,每个学科都在造自己的「基础模型」。就是那种一个模型干很多件事的玩意儿,跟GPT一个套路,只不过吃的不是文字,是基因序列、是分子结构、是天气场、是脑片子。
第二条,干湿闭环开始真落地。所谓干,指电脑里算;湿,指实验室里真做实验。以前AI算完一个方案,得人类去手动验证。现在AI直接驱动机器人做实验,自己提假设、自己跑、自己看结果再调整。
第三条,不过呢,也有些排斥AI的学者提供了些泼冷水的声音,我们也会大致聊聊。
记住这三条,下面分学科看就不会乱。
生命科学这半年最破圈的,是Google DeepMind的AlphaGenome(Nature,2026年1月)。
你可能听过一个数字:人类基因组里只有约2%是编码蛋白质的,剩下98%长期被叫做「暗区」。但偏偏大多数跟疾病相关的突变,就藏在这98%里。问题是这片区域太难读了,它不直接造蛋白,而是像开关一样调控别的基因什么时候开、开多大。
过去研究它,得拼好几个专用模型:看基因怎么被剪接拼接用一个,看DNA什么时候打开用一个,看它在细胞核里怎么折叠又是一个。一个任务配一把专用钥匙。AlphaGenome干的事,是把这些全塞进一个模型。它一次能读进100万个碱基对的DNA序列,以单个碱基的精度,同时预测十来种调控信号。
效果到底行不行?在26项变异效应预测的评估里,它有25项追平或超过此前各自领域最强的专用模型。这意思是,一个通才打赢了一屋子专才。
但我得替它把话说圆。这些大多还是计算预测跟实测数据比相关性,在一个常用基准上,预测值跟真实实验结果对得上六成多,剩下三成多还对不上。这说明它对单个突变的解释力还有限,离「医生拿着它直接判断这个突变到底致不致病」还有距离。它是把暗区的地图画得更全了,不等于已经能临床用。
另一个我觉得特别戳中要害的,是哈佛团队的Sequence Display(Nature Biotechnology,2026年4月)。
AI做蛋白工程这事,瓶颈从来不是模型不够聪明,而是没数据喂。蛋白的「序列长这样、活性有多强」这种配对数据,过去靠人一个个测,慢得要死。Sequence Display想了个巧办法:给每个蛋白挂一个「活性条形码」,活性越高,条形码被编辑得越多,最后靠测序按活性分桶。
结果是单次实验产出超过1000万个数据点,从产数据到训完模型,总共三天。它已经在小型基因编辑酶、tRNA合成酶这些蛋白上验证过,还真找出了能识别非天然氨基酸的合成酶变体。我喜欢这个工作,是因为它没去卷模型,而是去卷数据这个真瓶颈,反过来给那些蛋白大模型造训练集。当然,它读的活性是用条形码间接读的,不是直接测酶的反应速度,目前也只在四类蛋白上验过,能不能推广到更复杂的酶和抗体,还得看。
顺带说一句,造蛋白这块还有个有意思的趋势。英伟达和牛津在ICLR 2026上的一个工作(Proteína-Complexa),把大模型里那套「想得越久、答得越好」搬进了蛋白结合体设计,单样本生成只要15.6秒,在它自己选的14个靶点上全拿最佳。还有一篇综述(arXiv 2602.03779)把这些年生成式AI设计酶的成绩单摊开:有个被重设计的蛋白酶活性提升26倍、耐热温度抬高40度。十多年来从头设计的酶一直催化效率低到没法用,现在第一次摸到了工业上能用的门槛。这些目前主要还是计算成功率,真做实验验证偏少,但方向已经很清楚。

化学这块,我挑了一个特别诚实、也特别打脸的工作来讲:A-Lab(Ceder组,arXiv 2604.11957)。
这是第一个能在严格无氧环境下,全自动合成怕空气材料的自驱动实验室。它在手套箱里自动合成加表征了352个卤化物锂尖晶石样品,覆盖19种金属。更妙的是,它把大模型显式拆成两个角色:一个专门找异常样本、提假设,另一个找规律、往外推。这样你能追溯它每一步「为什么这么决定」。
听起来很科幻对吧?但结果反直觉的地方在这儿:所谓「成功」的样本比例,也就是导电性达标、纯度高的那种,从最初75个样本的1.33%,跑到最后75个样本,**也只提升到5.33%**。
就算用上最前沿的agent做闭环优化,命中率还是停在个位数百分比。作者自己也承认,找异常那个agent主要在已经探索过的区域里精修,真正往外扩展靠的是找规律,两者协同的增益有限。我觉得这事的价值,恰恰在于它没吹,它证明的是「这条路能跑通」,而不是「我们发现了一堆好材料」。
不过话说回来,5%的命中率,跟一个有经验的材料学家用直觉去筛,到底是快还是慢、好还是差,论文没比,我们也别急着替它下结论。它了不起的地方是把整个流程自动转起来了,不是说这条路已经赢了人。
材料这边还有一条「基础模型」的线值得提。大阪大学的工作(arXiv 2603.03223),把通用原子模拟模型能算的元素,从此前的89种撑到了97种,专门补齐了镅、锔、锎这类极重的放射性元素,这些东西实验极难测、传统计算又极贵,过去基本是盲区。剑桥的MACE-POLAR-1(arXiv 2602.19411)则在1亿个分子结构上训练,让模型在带电、弱相互作用这些原本算不准的地方,精度逼近一种很贵的精确算法,蛋白和药物分子结合的精度改善约4倍。这俩都是冲着「一个模型管一大片体系」去的。
(另外有一项工作用大模型agent去优化一类多孔材料的合成,宣称结晶度大幅提升,但具体数字我没核实到,这里就不写死了。)
物理这块我最想讲哈佛的一个工作(arXiv 2604.08358),因为它直接关系到「我们到底什么时候能造出能用的量子计算机」。
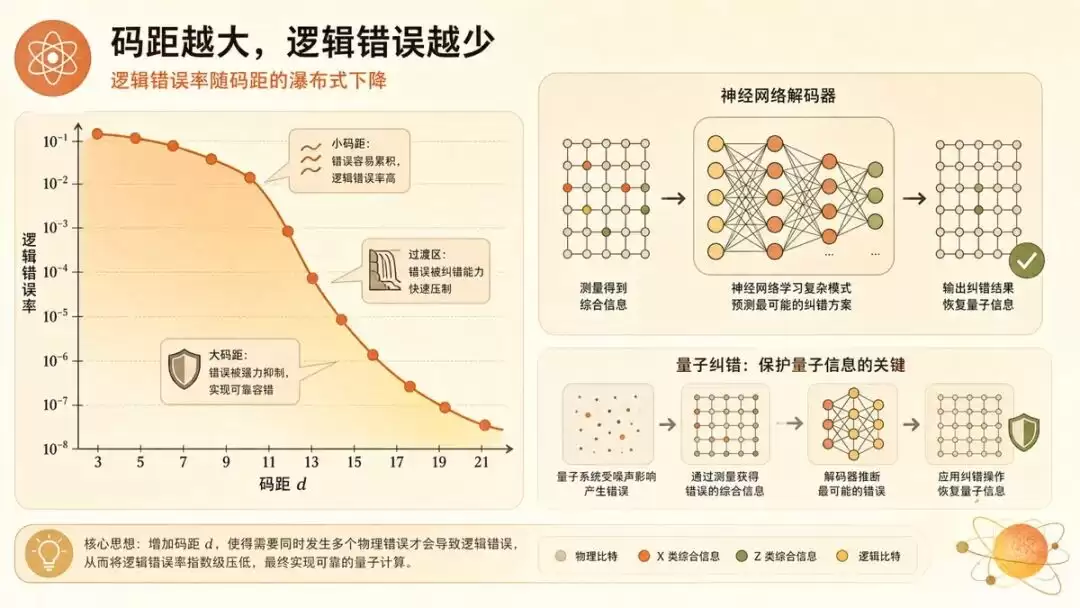
量子计算最大的麻烦是错误率高,得靠纠错。纠错的核心是个叫解码器的东西,实时判断哪里出了错。传统的算法解码器有个天花板。这篇用神经网络做了个解码器,把出错率压到了一个夸张的水平,相当于连续运算一百亿步才出一次错,已经摸到实用量子计算机的门槛。
更要命的是它带来的省钱效应。它发现量子纠错有个「瀑布」现象,错误抑制比教科书公式陡得多。利用上这个,要达到同样的目标,用神经网络解码器需要的量子比特规模明显更小。换算下来,造一台量子计算机用的物理量子比特能少约40%。少四成硬件,这是真金白银。而且它判断一次只要约40微秒,已经快到能跟上实际机器的节奏。
要泼的冷水也在:这些都是模拟数据,不是真机实测;而且这种神经解码器在理论上没法保证不出某类小错误,可能存在一个「错误地板」,目前只是没观测到。
物理还有两个我觉得很费曼味的小工作。一个是宾州州立的(arXiv 2603.15853),用AI解量子方程时,发现大家长期默认的「让能量最低」这个目标,会被神经网络太强的能力坑害,算出来的能量假性偏低,物理上根本不可能。换个目标函数,从很差的起点出发,10次里9次能稳定收敛,而老办法只有2次。这是个典型的「目标定错了」的故事,提醒人别迷信默认设置。另一个是用Transformer预测核聚变装置里等离子体的行为(arXiv 2602.19110),整体吻合度很高、算一次只要0.1秒,但作者老老实实指出有两个关键参数明显更差,因为喂给模型的信号里压根不含相关信息。不是模型不行,是信息不够。
天文气候这块,有个工作我看完直接拍桌子,劳伦斯伯克利和英伟达做的(arXiv 2604.09754)。
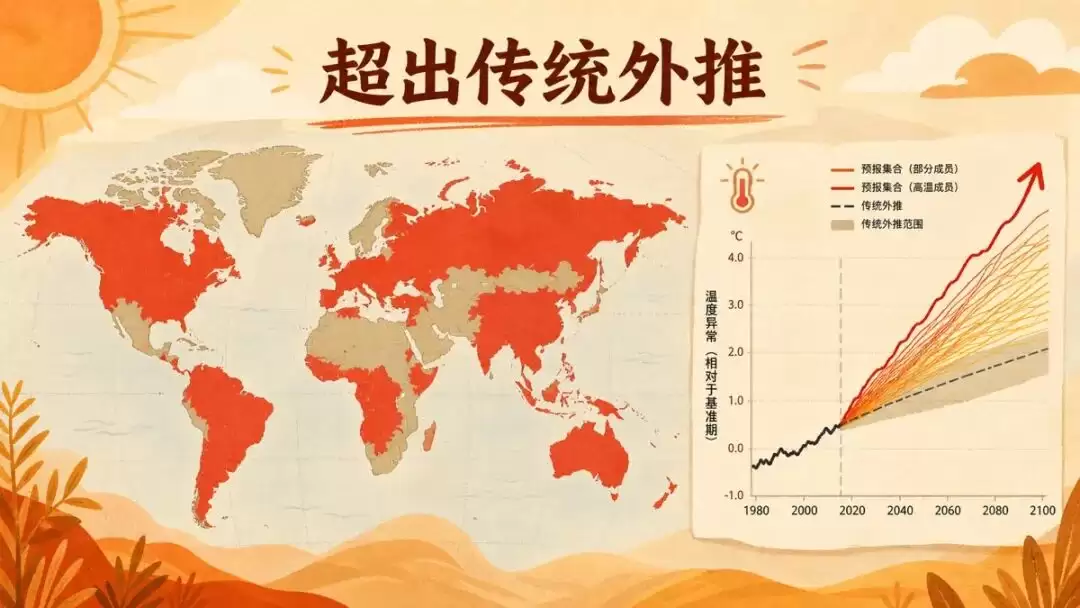
传统气象预报想估算极端天气,靠的是跑少量几个版本再做数学外推。欧洲那套主流系统,一次就跑50个版本。这篇用AI天气模型,生成了7424个2023年夏季的情景,等于造了7424个「平行版本的那个夏天」。
结果是:全球约三分之二的陆地上,AI算出的极端高温还在传统方法能覆盖的范围内。但剩下三分之一的陆地,AI算出的极端事件完全超出了传统外推的范围。其中7.3%的陆地,那个高温就算用传统数学外推也属于「极不可能」,主要落在格陵兰、俄罗斯东部和北部、阿拉斯加,以及中国东部、华北的部分地区。
我觉得这事最反直觉的点在于:大模型在这里的科学价值,不是「预报得更准」,而是「廉价生成几千个平行现实」,把传统方法压根够不着的极端情况翻出来。这直接服务于公共安全预警分级,你得先知道最坏能坏到哪,才知道防到什么程度。当然它是事后情景模拟不是真实预报,模型本身也有偏差,作者就指出它在某些地区反而算冷了。
天气这块的「基础模型」叙事也很热。英伟达一篇工作(arXiv 2601.18111,叫ATLAS)证明了一件挺去魅的事:做顶尖的天气预报,根本不需要那些天文级定制的特殊网格,一个通用Transformer就够了,大多数变量上还稳定超过欧洲那套产品,算一步快到3.3秒。另一篇(HealDA,arXiv 2601.17636)则戳中了AI气象的软肋:过去AI只换掉了「预报」这一环,而把观测数据整理成预报起点这一步,还吊在传统方法上,这一步吃掉全球预报算力的约四成。HealDA用一个简单网络,单张H100显卡一秒就出结果,对比欧洲那套要约1小时、1800个CPU节点,而预报精度只损失不到一天的时效。
脑科学我讲两个。
一个是BrainIAC(哈佛系,Nature Neuroscience,2026年2月)。它用近4.9万张脑部MRI做训练,全程自学、不用人工标注,一个模型干了7件事:估计脑龄、预测痴呆风险、检测脑肿瘤的基因突变、预测脑癌生存期等等,整体跑赢了3个传统的专用AI。
这事的意义是,医学影像AI过去是「一个病训一个模型」,BrainIAC证明放射科也能走GPT那条路:先在海量没标注的片子上自学通用本领,再用很少的标注微调出各种诊断能力。而且越是数据稀缺、任务越难,它相对专用模型的优势越大。代码和模型都开放了。它具体的准确率数字Nature正文在墙后我没拿到,这里就不编百分比了。
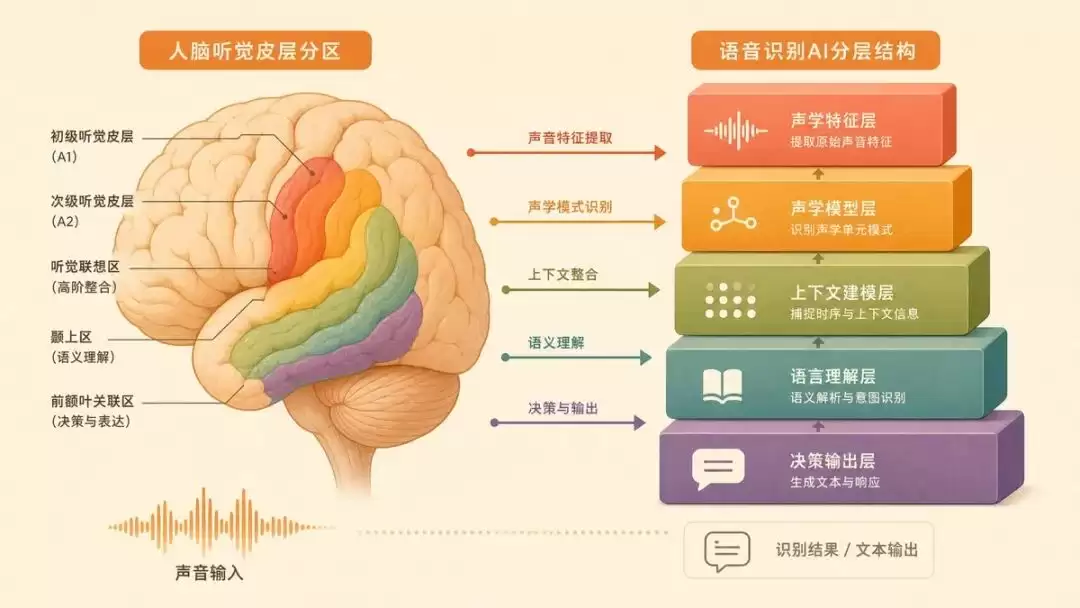
另一个更哲学,让我想了很久(Nature Machine Intelligence,2026年2月)。15名脑子里植入了电极的患者听语音时,研究者记录他们听觉皮层的反应,再去比对一个语音识别AI内部各层的活动。结果是脑区和AI模型的层几乎一一对应,从声音、到音节、到词、到意思,人脑和语音AI走的是同一条递进的处理阶梯。
过去我们说「AI能预测脑活动」,那是弱对应,可能只是碰巧。这篇把它推到了强对应:连内部一层层的结构都平行了。它暗示生物和人工系统,在「把声音变成意义」这件事上,可能用了相似的策略。
这个方向值得盯,但我得提醒一句:层级对应,也可能只是因为「把声音变成意义」这件事本来就只有这一条阶梯可走,未必是两套系统真的想到一块去了。再加上样本只有15人,用的也是特定的AI,这是相关性证据,不等于人脑真就用这套机制。免责声明放前面,我还是想说,这个方向比任何一篇刷榜论文都更让我好奇。

这半年也有几个反共识的发现,我觉得反而让人更踏实。有研究拿两家不同厂商的前沿模型去生成科研新假设,发现输出相似度高得惊人,你问3家还是问10家,结果几乎一样,创新的多样性被预训练和对齐压扁了。另一边,一个只有35亿参数的小模型,微调后控制原子级显微镜,命令准确率干到99.3%,反而超过了OpenAI的o4-mini,因为大模型输出带概率性,在纳米尺度一出错就是不可逆的实验失败,精密科学里确定性的小模型反而更靠谱。还有篇综述算了笔账:现在有系统能2.3小时产一篇论文,但生成能力一直在跑赢验证能力,AI产得越来越快,却没法证明自己对、有意义。这些声音不扫兴,它们一致指向同一句话:AI可以把生成做到无限快,但验证和负责这一端,目前还得人来。

把这半年看完,作为一个天天指挥AI做产品的人,我想说说自己的判断。
我做App的时候,AI是我的工具。它写代码写得比我快,但出了bug,是我对着报错改、是我决定这功能要不要、是我去App Store担责。AI再强,它都站在「我」这个判断主体的下游。
科学这事,本来也该是这样。但我看到的趋势是,AI正在从科研的工具,往科研的流程本身挪。自驱动实验室自己提假设、自己跑、自己改;AI科学家从选题到写论文一条龙。挪到一定程度,那个负责判断的主体就模糊了:到底是谁在做科学?
我的看法是,这条边界不能模糊。而且巧的是,这半年最扎实的工作恰恰都没模糊它。A-Lab老老实实报5.33%的成功率;那个小模型靠确定性赢过大模型;路线图综述直接说瓶颈是「为真实性负责」。它们共同指向一句话:AI可以无限扩张「生成」,但「验证」和「负责」这一端,目前还非人类不可,短期也看不到松动。
所以回到尹希那句话。他说自己有没有亲手得出解是次要的,只要结果能被验证,我其实挺认同。解越来越多地交给AI去生成,这是大好事,它意味着人类能问的问题、能碰的边界,一下子被推远了。剩下还得人站着的岗,是「验证」和「负责」这一端。但我一点都不觉得这是坏消息。反过来看,这恰恰是把人从「测一千万条数据」「算几千个平行宇宙」这种力气活里解放出来,让我们专心去干那件最像人的事:判断哪个问题值得问,以及为答案负责。
我得说句实话:这一堆基础模型、自驱动实验室,到2026年中真正进了科学家日常的还不多,大部分论文还停在概念验证。但方向我是真信。过去要十年的事现在几周做完,这种提速一旦铺开,基础科学会以我们还没适应的节奏往前冲。可控核聚变、室温超导、阿尔茨海默的药这些卡了几十年的硬骨头,第一次有了被批量啃动的可能。
所以比起担心,我更多是兴奋和期待。AI钻进实验室这件事,我赌它是这十年里对人类最重要的变化之一。如果加盟传闻属实,尹希把整个职业生涯押上去,我挺理解他。换我站在他那个位置,看到AI能把十年压成几周,可能也会做一样的选择。