北大发布全球首个自进化5D世界模型:基于摩尔线程全国产算力底座
2026-06-06 3343802
2026-06-06 0
通用智能体已经深入真实工作流,能自主完成写代码、处理文件等复杂任务。然而,一旦任务失败,很难界定是模型“没想明白”,还是工具或环境“没配好”。
为此,我们推出全新评测基准
PawBench
。
它面向个人助理与通用智能体场景,
将底座模型与运行框架(Harness)纳入
同一评测体系
。
底座模型
:负责思考任务怎么做,决定智能体的能力上限。运行框架(Harness)
:负责给模型装配 Prompt、提供工具、管理workspace和处理异常,决定能力能否稳定落地。PawBench v1.0 构建了包含 150 道真实任务、4050 个测试单元的评测集,不仅能评出
‘模型+Harness’的最佳组合
,更能
帮Harness开发者精准定位问题
并验证优化。
项目地址:
https://github.com/agentscope-ai/PawBench
榜单地址:
https:/
/agentsc
ope-ai.github.io/PawBench
OpenJudge项目地址
:
https://github.com/agentscope-ai/OpenJudge
Openjudge项目主页:
https://openjudge.me
注:PawBench 是 OpenJudge生态的一部分。它沿用了 OpenJudge“评测驱动优化”的核心理念,并专注于评估 LLM × Harness 这一垂直维度的联合效果。

PawBench 不是单纯做一个模型排行榜,而是把“模型、Harness、任务”三者放在一起做交叉评测。
本次评测矩阵是 9 个模型 × 3 个 Harness × 150 道任务,一共 4,050 个测试单元。三家 Harness 分别是
Hermes
、
OpenClaw
和
QwenPaw
。所有任务都在 Docker 沙箱中运行,执行轨迹、grader 产物和环境快照都会被保留下来,方便后续按切片复盘。
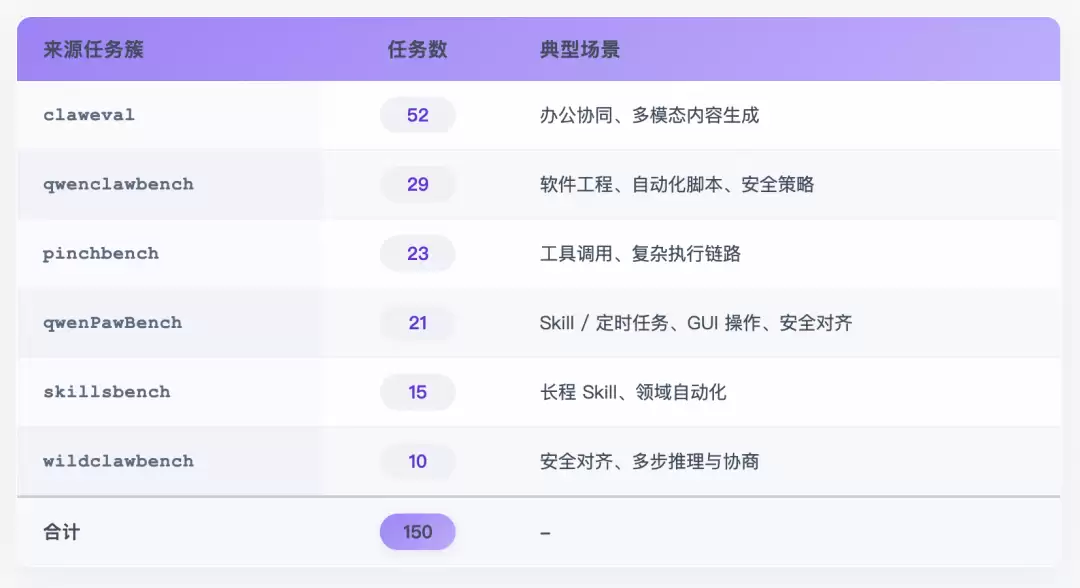
其中150道任务是从 6 个高质量 Agent 评测集中抽取的:
每道题都会按照 5 个维度打标:
应用场景
:例如办公协同、软件工程、自动化脚本、多模态内容生成。
原子能力
:例如工具调用、Skill 使用、规划、逻辑推理、自我校验。
复杂度
:L1 / L2 / L3,避免只靠简单题刷高分。
输入模态
:区分纯文本任务和图像、音频、视频等多模态任务。
运行 环境
:区分离线沙箱任务和需要联网的 Web 搜索 / 网页获取任务。
最终得分由两部分组成:一部分来自自动评分器,包括规则和子项断言;另一部分来自 LLM-as-judge,用于评估更偏语义的结果质量。本期评测采用混合权重计算最终分数,分数范围为 0 到 1。

PawBench 榜单支持 Overall、Text、Multimodal 三个切片。同一组提交结果可以看 150 道任务的总分,也可以切换为 124 道纯文本任务或 26 道多模态任务。
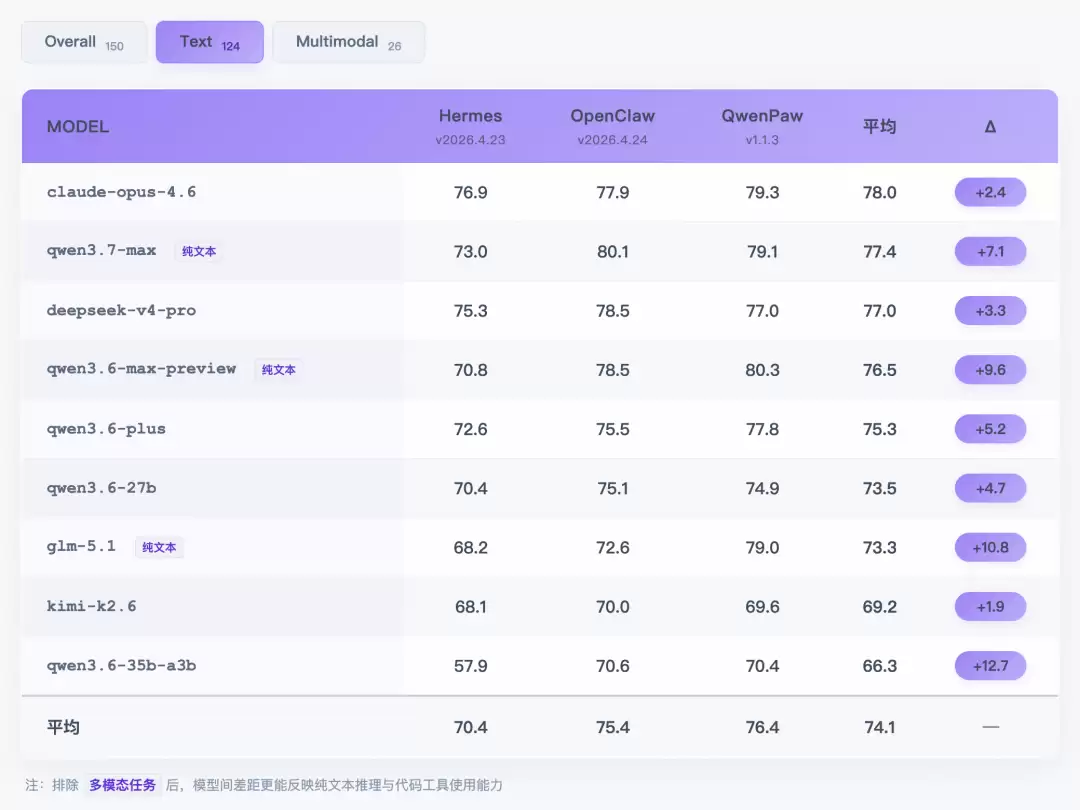
查看完整榜单,请前往:https://agentscope-ai.github.io/PawBench/
从本次结果看,有两个结论比较明显。
Harness 间存在稳定分差
:QwenPaw(76.4)、OpenClaw(75.4)、Hermes(70.4)。最高 6.4 分的极差,堪比一次重大的模型版本升级。
好 Harness 能让模型“以下克上”
:在 Hermes 环境下,GLM 5.1 仅得 68.2 分;而在 QwenPaw 环境下,
Qwen3.6-35b-a3b
却能拿到 70.4分。这证明 Harness 环境甚至比底座模型本身更关键。
面对如此决定性的差距,PawBench 的价值不仅在于给出一个排行榜,更在于提供深度诊断,帮我们追问:这关键的几分,到底是从哪里拉开的?

PawBench 的切片能力可以把 4,050 个测试单元按模型规模、模态、任务类型、技能领域等维度拆开,再对照执行轨迹,定位 Harness 行为上的差异。
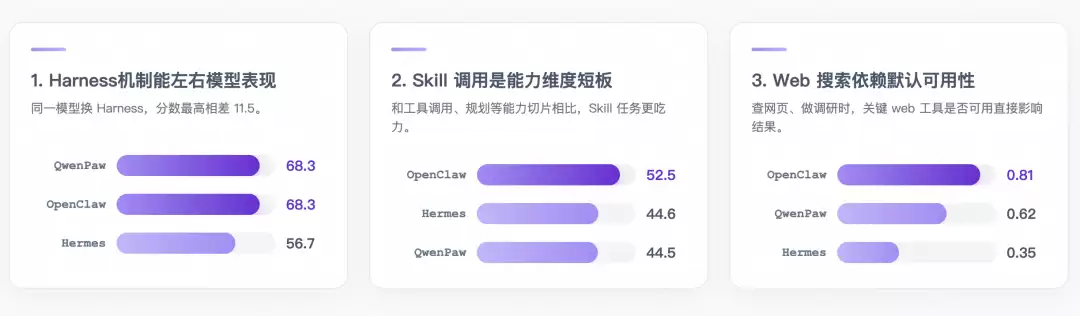
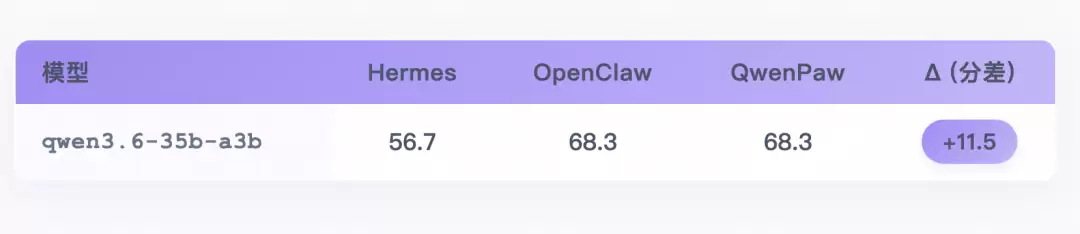
发现一:Harness机制能左右模型表现
最典型的样本是 qwen3.6-35b-a3b。同一个模型只换 Harness,分数差距达到 11.5 分。
对执行轨迹做复盘后,我们看到几个可能原因。
(1)缺乏“产物级”硬校验:
导致“虚假完工”目前的 Harness 多依赖模型的自我声明,缺少对工作区(Workspace)产物的实质性校验(如文件是否真正落盘、diff 是否生成、测试是否通过或路径是否正确)。这导致模型极易过早宣布完成,从而在此类任务中严重掉分。
(
2)
路径感知与约束宽松:
比如Hermes 未在 Prompt 中明确当前工作目录,也未在 write_file 等工具层强约束写入路径。这导致模型“自以为”写入成功,但评测程序在标准工作区却扫描不到产物。

(3)工具表体 量过大,增加模型决策负担:
不同 Harness 默认装载的工具数量差异显著(Hermes 约 65 个,OpenClaw 约 30 个,QwenPaw 约 15 个)。工具并非越多越好,庞大的工具 Schema 不仅挤占上下文,还会显著增加小模型的首轮决策负担。
发现二:Skill主动发现是Harness能力短板
很多用户会将
S
kills放在项目workspace中,作为项目专属Skills。本次评测模拟就是这种情况:每个task专属的
S
kills会复制到workspace中,来测试Harness主动发现和应用skills的能力。从结果来看,相比于工具调用、规划或逻辑推理等其它能力切片相比,三家 Harness 在 17 道 Skill 任务上的表现都较为吃力。
这暴露出两个核心问题。首先是
Harness的主动发现能力不足
。除了OpenClaw外,另外两个harness都不会主动加载workspace中的skills。如果 Harness 只扫描全局预装 Skill,而不扫描当前工作区,就会漏掉这份关键指南,让模型只能自行摸索。
其次是
模型自身的长链路推理瓶颈
。即使 Harness 成功注入了 Skill 并立好了“路标”,模型在执行复杂推理和精细计算时依然容易出错。Harness 能指路,但能不能走通,最终仍考验底座模型的能力。
发现三:Web搜索任务很依赖默认可用性
这里说的Web 搜索任务侧重考察模型的网页检索、内容抓取与深度调研能力。本次评测不追求“配齐所有搜索服务 API Key 的理论上限”,而是
还原开发者第一次 clone 后的默认体验
:拉固定版本源码,写入 LLM 密钥,然后直接跑。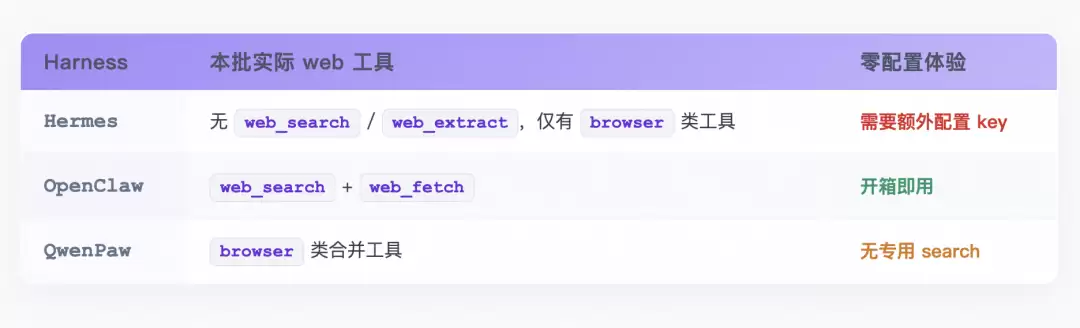
在这类任务中,Hermes 表现偏低,核心原因是
其核心工具在零配置下被“锁死”
。虽然源码内置了
web_search
和
web_extract
,但必须配置外部搜索 API Key 才能启用。在仅配置 LLM 密钥的评测环境下,模型拿不到这些工具,只能降级使用基础
browser
工具硬做。
相比之下,OpenClaw提供了更好的体验,它的
web_search
支持 DuckDuckGo 等免密服务,
web_fetch
依赖内置 HTTP 抓取,真正
实现了零配置直连
;QwenPaw 虽无专属搜索工具,但通过browser_use
结合模型知识储备,也能有效完成基础的 Web 访问。
这说明,Web 搜索任务的评测结果不只反映模型搜索和阅读能力,也反映 Harness 是否把关键工具做成了“默认可用”。

结合上面的切片结果,PawBench 给 Harness 设计提供了 4 条比较直接的原则。

1. Inform
Fully:充分告知
模型看不见的东西,对它来说就不存在。
Harness 应该明确告诉模型当前运行环境:cwd 在哪、workspace 在哪、输出目录在哪、工作区里有没有 SKILL.md,以及有哪些可用资源。不要假设模型会自己猜到这些上下文。
2. Equip o
n Demand:按需装备
工具要装得对,也要装得精。
“装得对”指关键工具应该在默认配置下可用,例如 keyless web search、内置 HTTP fetch、Skill helper 自动注册。“装得精”指工具数量要匹配目标模型的上下文和注意力预算。工具不是越多越好,过多的 schema 反而可能压垮小模型。
3. Monitor
Actively:主动监控
不要只听模型说了什么,要看它做了什么。
Harness 应该检查任务产物是否真的落地:文件是否存在、是否非空、是否包含必填字段、工具调用是否合法、exit code 是否正常。尤其在文件写入、代码修改、报告生成这类任务中,产物级校验比一句“我完成了”可靠得多。
4. Recover G
racefully:弹性恢复
一次异常不一定代表任务失败。
当 Harness 发现模型空响应、只画计划、工具调用异常或产物缺失时,可以给它一次更有信息量的续推机会,例如注入当前状态、说明缺少什么产物、保留中间结果,并设置合理的 retry budget。很多任务不是不会做,而是在关键节点缺少一次及时纠偏。

如果你是智能体用户,PawBench
可以
帮你选择更合适的模型和 Harness 组合
。比如,面对纯文本任务、多模态任务、Skill 任务或 Web 搜索任务,不同组合的表现并不一样。
如果你是 Harness 开发者,PawBench
不只是一个榜单。它提供了 4,050 个 cell 的对照矩阵和切片分析能力,可以帮助你做三件事:
横向自检
:把你的 Harness 跑到同一组模型上,看在哪些任务类型上落后。
失败画像
:锁定可疑切片,对比 trace,找到具体的 Harness 行为问题。
回归验 证
:每次修复后重新切片,看分数变化是否真的对应到问题上。
这类评测对通用智能体尤其重要。因为真实用户不会只问模型一个问题就结束,他们会让智能体操作文件、调用工具、跑脚本、读网页、跨步骤完成任务。PawBench 希望把这些复杂链路拆开,让模型能力和 Harness 能力都能被看见、被诊断、被持续改进。

PawBench v1.0 已开源。你可以到社区参与:
接入新的 Harness,例如 Cursor Agent 或其他社区框架。
提交新的模型评测结果。
贡献更多任务,并按照五维标签体系完成标注。
基于 slice 能力分析你关心的任务切片,反馈诊断报告。
PawBench 站在开源 Agent 评测社区的肩膀上,致敬Claw-Eval、QwenClawBench、WildClawBench、PinchBench 和 skillsbench。欢迎你一起参与贡献,共建Agent评测生态。
推荐阅读
Qwen3.7-Plus:把多模态AI变成“实干家”

Qwen-VLA:迈向通用具身智能的统一动作框架
