友讯达:企业暂不涉及算力业务
2026-06-12 3351903
2026-06-12 0
在如今的 AI 应用落地中,如何选择合适的底层模型来驱动 Agent(智能体)正成为开发者们最核心的痛点。尤其是在复杂的自主工作流中,模型的推理能力、工具调用(Function Calling)准确率以及上下文记忆能力,直接决定了任务的最终完成率。为了在不同场景下快速找到最优解,很多开发者开始借助像库拉镜像平台(leadhi.cn)这类AI模型聚合平台,它整合了 Gemini、主流大模型、ClaudeCode 等多款主流工具,原生适配国内网络环境,无需额外改造环境就能直接调试调用,无论是个人开发者做原型验证,还是中小企业落地 AI 业务,都提供了一个低门槛的调试入口。

一、 评测场景与任务设计
为了客观评估不同模型在 Agent 任务中的真实表现,我们设计了一个典型的“自动化行业竞品分析”Agent 任务。该任务并非简单的单次问答,而是一个包含多步规划的复杂工作流:
信息检索:根据设定的关键词,调用搜索 API 抓取最新的技术文章和竞品动态。
数据清洗:过滤掉广告和无关信息,提取出核心的技术参数。
结构化分析:对比不同产品的技术路线,并输出优劣势矩阵。
报告生成:自动整理并输出一份格式规范的 Markdown 格式行业报告。
我们选择了当前市场上最具代表性的两类模型进行同等条件下的压测:模型 A(主打深度推理与复杂逻辑的高阶模型) 与 模型 B(主打长上下文与高性价比的实用型模型)。
二、 核心数据对比
在进行了 50 轮相同的 Agent 任务闭环测试后,我们整理了以下关键维度的对比数据:
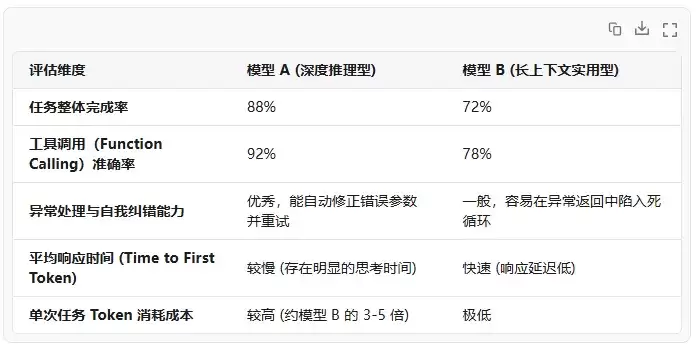
三、 实战表现深度拆解
从测试过程中的日志来看,两个模型在处理 Agent 任务时表现出了截然不同的特征:
四、 行业趋势与落地建议
单纯依赖某一个大模型来搞定所有 Agent 任务的时代正在过去。目前的行业共识正朝着“多模型混合路由(Router)”的方向发展。
在实际项目落地中,更务实的架构是:
前置过滤与数据清洗:交给像模型 B 这样速度快、成本低的轻量模型处理。
核心决策与复杂规划:将关键的推理和工具调用分发给像模型 A 这样的高阶模型。
这种动静结合的“组合拳”方案,既能将任务完成率维持在商业化可用的高标准线上,又能最大程度地降低企业日常运营的 API 账单成本。