科技行业5月裁员38242人:创2024年以来最高纪录
2026-06-16 3357333
2026-06-14 0
最近做接口文档治理时,我顺手把同一批 Controller 方法丢给两款主流大模型做注释生成:GPT-4.1 和 Gemini 2.5 Pro。测试入口用的是库拉镜像平台leadhi.cn,它把 Gemini、ChatGPT、ClaudeCode 等模型整合在一个环境里,国内开发者不用反复折腾调用配置,适合做这种横向对比。

这次不聊泛泛的“谁更聪明”,只看一个很具体的场景:给后端接口补充可读、可维护、能直接进入团队代码评审的注释。
测试样例:一个真实但不复杂的接口
我选了一个常见的订单查询接口,业务逻辑不算难,但参数、权限、异常分支都比较典型。
java
@GetMapping("/orders/{orderId}")
public OrderDTO getOrderDetail(
@PathVariable Long orderId,
@RequestParam(required = false) Boolean includeItems) {
return orderService.getOrderDetail(orderId, includeItems);}
给两款模型的提示词基本一致:
请为这个接口补充 JavaDoc 和必要的行内注释,说明接口用途、参数含义、返回值、异常情况和使用注意事项。注释要适合企业项目,不要过度解释基础语法。
第一轮感受:GPT 更稳,Gemini 更会展开
GPT-4.1 的输出偏“工程规范”。
它会比较克制地写接口用途、参数说明、返回值说明,并补充一些合理的异常场景,比如订单不存在、无访问权限、参数非法等。整体风格像是团队里资深后端同事写的,不花哨,但能直接放进代码里。
Gemini 2.5 Pro 的输出更“内容型”。
它会把接口背景、调用场景、可能的前端使用方式也写出来,有时还会建议增加分页、缓存、权限校验、审计日志等扩展点。优点是信息量大,适合帮助开发者理解业务;缺点是如果直接作为代码注释,会显得有点长。
对比结果
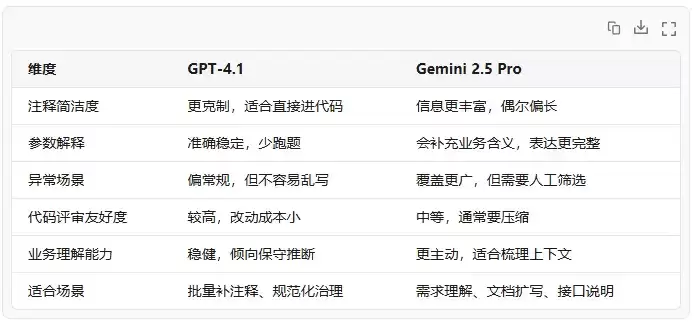
一个很明显的差异:是否“脑补”
接口注释最怕两件事:一是写得太少,别人看不懂;二是写得太多,把代码里没有的逻辑也写进去。
GPT-4.1 在这点上比较保守。比如代码里没有显式权限判断,它通常会写成“可能抛出无权限异常,取决于业务实现”,这个表述比较安全。
Gemini 2.5 Pro 则更愿意主动补业务设定。它可能会写“仅订单所属用户或管理员可访问”。如果项目里确实有这个规则,那很好;如果没有,就属于注释先于实现,容易误导后续维护者。
所以在接口注释场景里,我更看重模型的“克制能力”,而不是单纯的信息量。
实战建议:不要让模型一次写完所有东西
如果是团队里真正要落地,我建议分三步用:
第一步,让模型只生成 JavaDoc,不要生成业务扩展建议。
第二步,让模型单独列出“可能缺失的校验点”,不要直接写进注释。
第三步,由开发者确认后,再把确定存在的规则合并进代码。
这样可以避免 AI 把“建议”写成“事实”。
一个比较好用的提示词是:
只根据当前代码生成接口注释。对于代码中无法确认的业务规则,请使用“可能”或“需结合实现确认”表述,不要编造确定性结论。
这句话能明显降低误写风险。
趋势:接口注释会从“补文字”变成“补上下文”
过去我们说接口注释,通常只是解释参数和返回值。
但现在大模型介入后,接口注释正在变成一种“轻量级知识沉淀”:它可以把接口用途、调用边界、异常策略、兼容性注意事项都串起来。
不过这也带来新的问题:注释越像文档,就越需要准确性。否则时间一久,注释和代码分离,反而增加维护成本。
我的判断是,未来团队不会简单地让 AI 自动生成注释后直接提交,而是会把它放进研发流程中:
模型负责初稿,开发者负责确认,代码评审负责兜底。
结论
如果目标是批量给接口补充规范注释,GPT-4.1 更省心,输出稳定,人工修改少。
如果目标是理解接口上下文、扩展接口文档、发现潜在设计问题,Gemini 2.5 Pro 更有启发性,但需要人工筛选。
一句话总结:
GPT 更像代码评审助手,Gemini 更像技术文档助手。
在接口注释这种偏工程落地的场景里,不一定是信息越多越好。真正好用的 AI,不只是会写,还要知道哪些内容不该写得太满。