0.6B VLM重塑AI修图推理流程:支持手机端侧部署 vivo+浙大出品
2026-06-16 3357450
2026-06-14 0
夕小瑶科技说 2026-06-12 09:00 北京
导 语
当大模型从“能对话、能看图、能调用工具”走向长周期任务,新的瓶颈正在浮现:模型不仅要看得长,更要记得住、想得起、用得对。记忆,正在从大模型的附加功能,变成 Agent、编程助手、企业知识系统和多智能体工作流真正落地的核心基础设施。哈工大(深圳)张民教授团队提出动态长上下文记忆推理、混合头稀疏解码和结构感知分层 KV 索引等系列方法,并开源 LycheeMem 记忆管理基础设施,尝试让大模型从一次性的上下文处理器,进化为能够压缩记忆、选择回忆、结构化组织并持续利用经验的记忆型智能系统
如果说过去几年大模型竞争的主线,是从“能对话”走向“能看、能听、能做”,那么进入 2026 年,真正的分水岭正进一步转向模型能否像人一样形成记忆、持续积累经验,并在超长文本与长周期任务中保持稳定、高效的推理能力。近期行业进展进一步放大了这一判断:MemoraX AI 在 LoCoMo-Refined 等长期记忆评测中发现,Agent 记忆并非简单存储,而应成为可学习、可归因、可进化的闭环系统;MemOS 则以开源框架和云服务形态,将记忆抽取、组织、检索、更新、治理与共享做成独立基础设施。随着 Agent、编程助手、企业知识系统和多智能体工作流加速落地,记忆正在从大模型的附加能力,变成决定其能否真正走向实用的核心基础。围绕这一方向,哈工大(深圳)张民教授团队持续推进“立知”系列大模型迭代,从语言智能、全模态智能一路走向记忆智能,逐步形成了面向通用人工智能的新技术路线。
自2022年11月30日 ChatGPT 推出以来,哈工大(深圳)张民教授团队共发布三代“立知”系列大模型(Lychee):
第一代:“立知”语言大模型(Lychee-Lang)于2023.6.18发布。Lychee-Lang是国内高校目前唯一拥有网信办和工信部双认证的大模型,拥有完整的自主IP。从数据、训练、推理到部署,全链路实现国产平台自主可控,并在Transformer架构基础上,进一步提出了“符号主义与连接主义融合”的大模型训练方法,包括“音形义”一体化的表示学习和“睁着眼睛学语言”的训练策略。“立知”第一代大模型踩过很多坑、走过很多弯路,但探索和走通了当时国际最先进的技术路线,并有所创新。
第二代:“立知”全模态大模型(Lychee-Uni-MOE-Omni:Lychee-UMO)历时两年,于2025.6.18发布。Lychee-UMO提出了“以自然语言为核心、语言智能原生的AI大模型新范式”。该范式具有两点比较大的创新:语言智能原生,多专家(MOE)架构的全模态理解和生成。第一点创新指的是在MOE框架下,非语言模态每个专家的初始化源自语言模型的映射,因此天然具有语言模型原生的知识属性。第二点创新是在业界首次设计并实现了高效的MOE全模态大模型架构。这个模型的发布在学术界和产业界得到很多关注,技术路线和模型架构被很多公司采用,并实现了落地化应用。
第三代:“立知”记忆大模型(Lychee-Memory)于 2026 年 4 月发布。记忆是人脑对过去经历、获取信息与外界刺激进行编码、存储,并在需要时提取与再现的认知过程,也是个体积累经验、认知世界、完成学习活动的核心心理机能。基于这一认识,前两代“立知”主要回答的是模型能否理解世界、表达世界,以及感知并关联不同模态的信息;而第三代则进一步面向记忆智能,探索让大模型具备类人记忆、持续学习和面向超长文本的推理能力。模型不再只是被动处理当前输入,也不再仅仅追求“看得更长”或“模态更多”,而是开始具备跨轮次、跨任务沉淀知识、调用经验并持续演化的能力。
相关论文:
Dynamic Long Context Reasoning over Compressed Memory via End-to-End Reinforcement Learning. ACL 2026.
LycheeDecode: Accelerating Long-Context LLM Inference via Hybrid-Head Sparse Decoding, ICLR 2026.
LycheeCluster: Efficient Long-Context Inference with Structure-Aware Chunking and Hierarchical KV Indexing. ACL 2026 Findings.代码仓库:
https://github.com/LycheeMem/LycheeMem
开源模型:
https://huggingface.co/lerverson/LycheeMemory-7B
项目主页:
https://lycheemem.github.io
当前主流大模型虽然在长序列建模与外部知识调用上不断进步,但大多仍停留在容纳更多信息而非形成有效记忆的层面。问题不仅是“找不到信息”,还包括写入不稳定、旧信息更新不及时、关键证据召回不准、临时状态与长期画像混淆、正确证据与噪声并存等。无论是稀疏/线性注意力、检索增强生成,还是循环记忆架构,都不同程度面临性能衰减、上下文碎片化、推理延迟高以及跨任务知识难以沉淀等问题。归根结底,真正关键的已不只是模型能看到多少信息,而是能否高效存储、动态激活、持续更新并长期利用信息与知识。
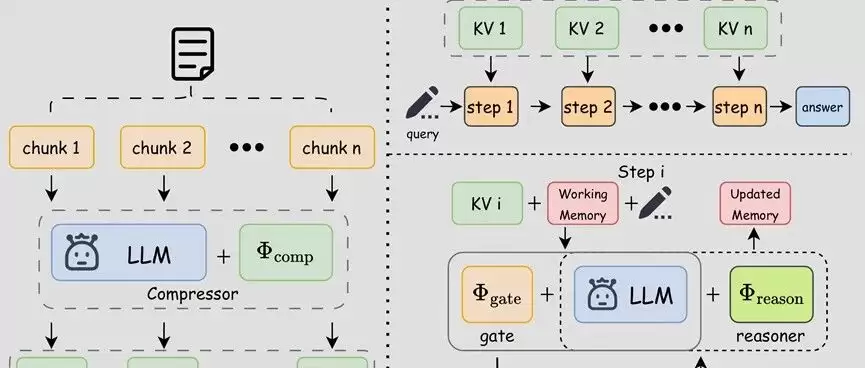
针对这一问题,立知记忆大模型Lychee-Memory将记忆提升为能力演进的核心目标,首次实现了隐式长期记忆与显式工作记忆的动态协同,并通过记忆导向的强化学习联合优化信息压缩、记忆激活与任务求解过程,推动大模型从一次性的上下文处理器迈向具备长期经验沉淀与调用能力的记忆型智能系统。与仅依赖向量库写入、检索排序或提示词拼接的应用层方案不同,Lychee-Memory把“记什么、何时激活、如何用于求解”纳入统一训练目标。它先将长文本切分为若干语义片段,再压缩为高信息密度的 KV-cache 风格潜在表示,形成可持续保留的隐式长期记忆;随后结合当前任务状态,从这些长期记忆中选择最相关的内容,逐步读取、更新显式工作记忆并完成推理。通过这一机制,模型不再只是被动处理上下文,而是开始真正学会“为了思考而记忆”。
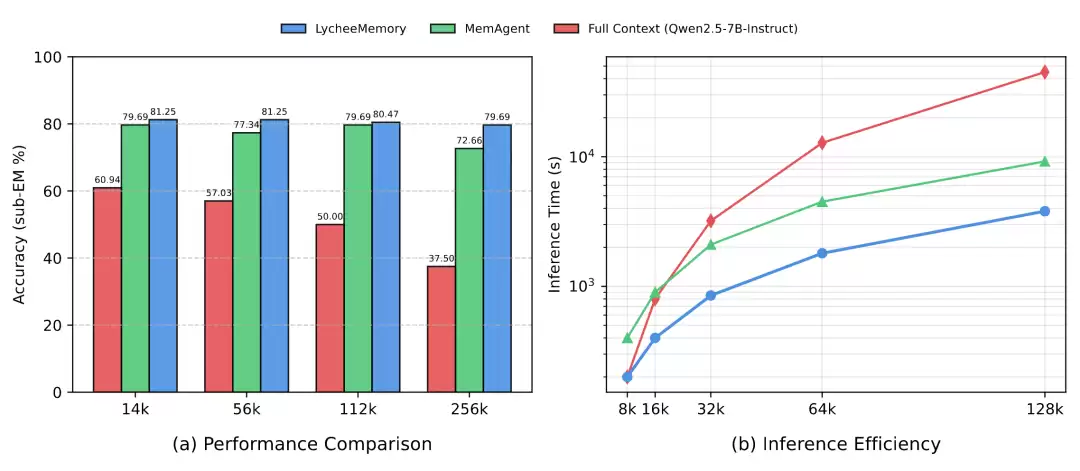

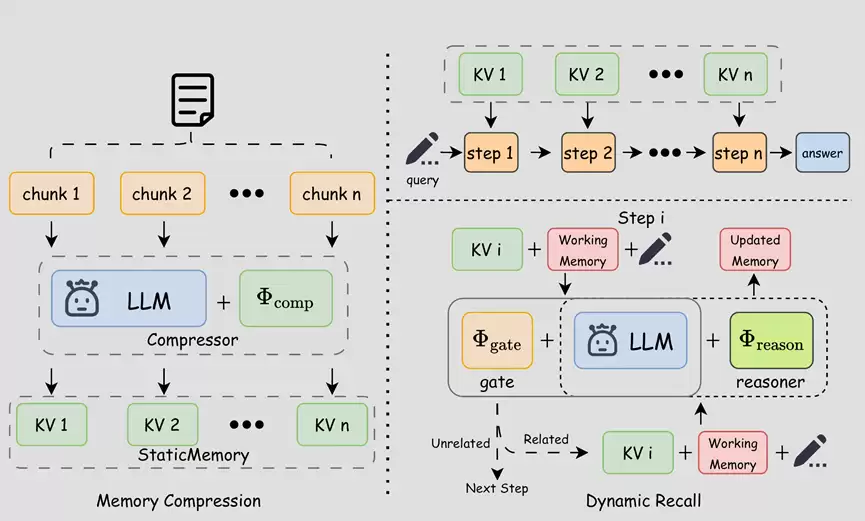
实验表明,模型不仅在多跳推理与长文本基准上取得了明显性能提升,还成功将处理长度从训练时的 7K 外推至 1.75M,理论上支持无限长文本推理。相较字节Seed提出的MemAgent,其在推理阶段实现了平均 2 倍的峰值 GPU 显存下降和 6 倍的速度提升。这说明记忆机制带来的不仅是能力增强,也包括效率上的显著改善。
与此同时,面向 Agent 场景,团队进一步开源了大模型记忆管理基础设施LycheeMem。针对大模型在长周期任务中易遗忘精确代码、复杂工作流与历史决策链的问题,团队构建了 3 层认知记忆架构,并结合 4 重检索信号融合与 5 类 Agentic 记忆推理能力,实现记忆的结构化组织、精准召回与主动固化。在 PinchBench 测评中,接入 LycheeMem 系统后,OpenClaw 相较原生记忆方案整体评分提升约 6%,Token 开销下降约 71.3%,总成本降低约 54.8%。按测评结果估算,每投入 1 元 Embedding 成本,最高可节省约 54.8 元大模型调用成本,ROI 达 5480%。这表明第三代“立知”的记忆能力不仅更强,也更具实际落地价值。
仅有长期记忆与工作记忆的协同机制还不够。要让大模型在超长文本场景中真正具备稳定推理能力,还必须进一步解决原生上下文记忆的调用问题。在解码阶段,随着上下文不断增长,KV Cache 会持续累积。这部分内容既构成了推理过程中的巨大计算负担,也可以被看作模型在当前任务中不断沉淀下来的原生上下文记忆。问题在于,传统全注意力机制本质上是一种对全部历史记忆进行无差别读取的方式,不仅代价高昂,也容易让模型淹没在大量无关信息之中。
针对这一问题,团队并没有将重点仅仅放在推理加速上,而是进一步探索模型如何在原生上下文记忆中有选择地回忆真正有用的信息。为此,团队提出了“检索头全局定位 + 稀疏头高效复用”的混合头稀疏解码框架,不再在层级这一粗粒度上统一共享关键 Token,而是让不同注意力头在记忆读取过程中进行细粒度分工:少数检索头负责在全局上下文记忆中动态寻找当前最关键的信息,多数稀疏头则复用这些被筛选出的关键信息完成高效计算。同时,团队首次将 HardKuma 概率分布引入端到端头角色学习,让检索头与稀疏头的分化能够在连续可导的训练过程中自然收敛到离散边界,从而消除了训练与推理之间的鸿沟。
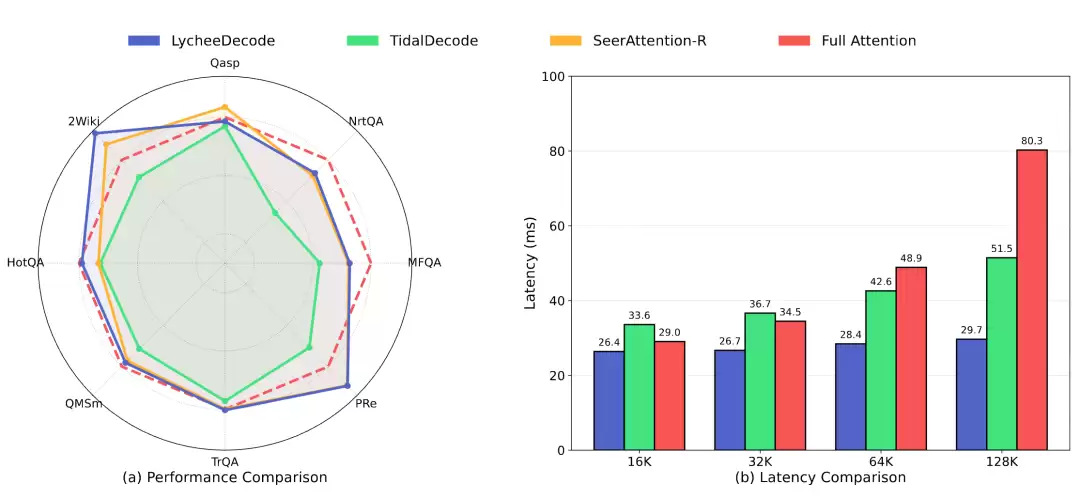
在系统层面,团队结合 TileLang 定制了混合头稀疏解码底层算子,通过工作负载池化最大化 GPU 利用率。最终,立知记忆模型在 LongBench、RULER、AIME24 等长文本理解与复杂推理任务上保持了与全注意力基线相当甚至更优的效果,并在 128K 上下文下实现了最高 2.7 倍的端到端解码加速,为第三代“立知”在超长文本场景下更高效地调用原生上下文记忆提供了关键支撑。
在解决了记忆形成与记忆选择的问题之后,第三代“立知”进一步关注原生上下文记忆的组织方式。对于超长文本任务而言,随着上下文不断增长,历史记忆往往以线性方式不断堆积。即便模型已经具备了有选择地回忆关键信息的能力,仍然会面临语义边界被破坏、结构信息丢失以及检索效率下降等问题。
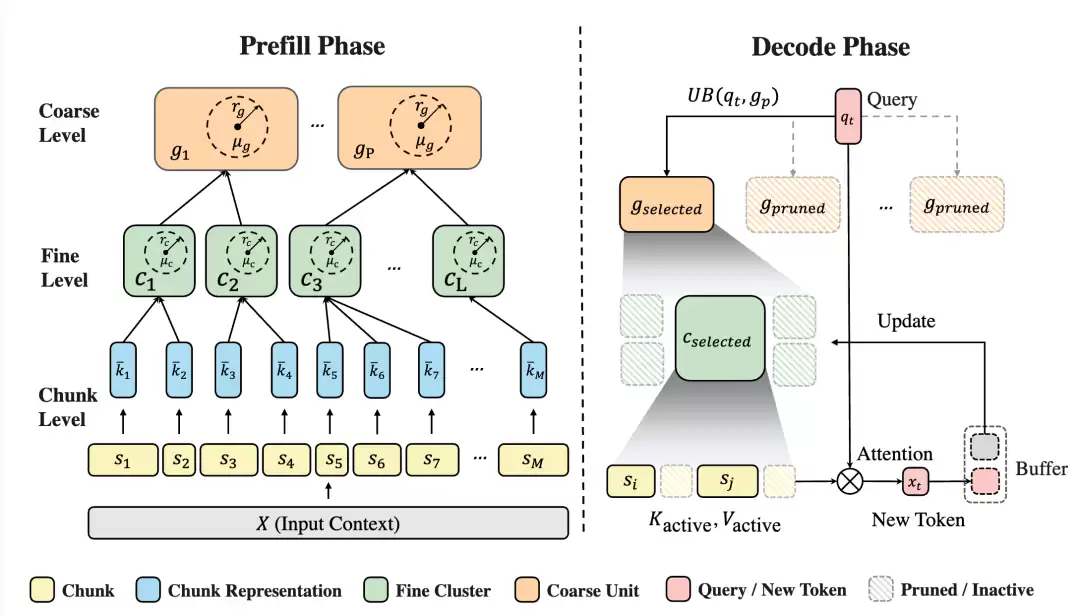
针对这一问题,团队进一步将关注点从选择记忆推进到组织记忆。与固定大小分页/Token 级聚类等传统方法不同,立知记忆模型不再按照机械长度切分上下文,也不再将原本连续的局部语义打散,而是通过结构感知的边界分块,保留代码、JSON、推理链以及自然语言段落中的语义完整性。在此基础上,进一步构建了递归式分层 KV 索引算子的 CUDA 内核,使原本依赖线性扫描的检索过程转化为可逐层剪枝、逐步定位的结构化检索,并通过懒更新机制支持流式生成场景下的低开销更新。
实验结果表明,在几乎不牺牲模型性能的前提下,立知记忆模型实现了最高 3.6 倍的端到端推理加速,并在长文本理解、结构化数据检索与复杂推理场景下优于 Quest、ClusterKV 等主流方法。这说明原生上下文记忆的高效利用,不仅取决于模型能否回忆,更取决于这些记忆能否被合理组织;而这也正是第三代“立知”面向无限长文本稳定推理补齐的关键一环。
从第一代语言大模型、第二代全模态大模型,到第三代记忆大模型,“立知”系列的技术演进正在逐步指向一个更清晰的方向:大模型能力竞争的重点,正在从“谁的窗口更大、模态更多”,转向“谁能真正记住、持续学习并稳定服务复杂任务”。当 AI Agent 从演示走向生产、从单轮问答走向长周期协作,记忆不再只是附加功能,而正在成为决定模型上限的底层能力。最新行业实践正在把这一趋势推向更具体的工程形态:一方面,应用侧记忆系统开始围绕写入、检索、利用、治理和 Skill 化沉淀形成闭环;另一方面,模型侧也必须在压缩记忆、原生上下文选择和结构化组织上补齐能力。第三代“立知”不再将长文本能力简单理解为上下文窗口的被动扩展,而是围绕记忆形成、记忆管理、记忆选择与记忆组织展开系统设计,尝试让大模型同时具备类人记忆智能、持续学习能力和面向无限长文本的推理能力。这一系列工作表明,大模型有望逐步摆脱对超长序列的直接暴力处理,转而在可压缩、可调用、可治理、可持续演化的记忆体系上,完成更稳定、更高效的推理与决策。
未来,张民团队还将继续探索更动态的记忆管理机制、记忆原生的大模型架构、更高效的原生上下文记忆调用方式,以及更贴近真实工作流的持续学习范式,并推动模型侧记忆机制与 Agent 记忆基础设施、企业级治理、多 Agent 协作和 Skill 沉淀进一步结合。随着相关模型、系统与基础设施的不断完善,具备类人记忆、持续学习与复杂任务执行能力的新一代智能体,正在加速从研究走向现实。

