顾全全确认离开字节Seed团队:曾主导SeedFold与Seed2.0训练体系建设
2026-06-14 3354608
2026-06-14 0
反推提示词技术RPE,全称Reverse Prompt Engineering,是在大语言模型与多模态模型广泛应用背景下诞生的一种逆向工程方法。其核心目标非常明确:给定一段 AI 生成的内容,反向推断出最可能生成该内容的提示词结构、关键词、约束条件与风格指令。
传统提示工程是“人给指令 → AI 出结果”的正向流程,而RPE则是“AI 结果 → 分析特征 → 还原指令”的逆向流程。两者并非对立,而是互补关系:正向提示工程用于创造,反向提示工程用于学习、复刻、优化与审计。从技术本质上看,RPE并不直接读取模型权重或内部状态,而是将大模型视为一个黑盒函数:输入 提示词,输出结果。反推过程就是在解这个函数的逆问题,寻找能让模型输出高度相似结果的输入空间。

在实际应用中,RPE覆盖文本、代码、图像、语音等多种模态。例如:
RPE的价值不仅在于抄袭式复刻,更在于提炼高质量提示范式。很多优秀生成结果并非来自复杂逻辑,而是来自精准的词序、权重分配、角色设定与格式约束。通过反推,使用者可以快速掌握优秀提示的内在规律,大幅提升自身正向提示工程能力。此外,RPE 在系统优化中同样重要。企业级应用中,通过分析用户真实交互结果反推用户意图,可以自动优化底层系统提示,减少幻觉、提升一致性、增强任务对齐度。从安全角度,RPE 也可用于检测是否存在恶意提示注入、隐式指令泄露等问题。
总而言之,反推提示词技术是大模型应用从粗放使用走向精细可控的关键技术之一,它让提示变成可分析、可复现、可迭代的工程化能力。

要理解并掌握反推提示词技术,首先需要建立对大模型生成机制的基础认知,否则反推只能停留在表面猜测。
首先,大模型的生成本质是条件概率预测。模型根据上文(包括系统提示、用户指令、上下文)逐token预测下一个最可能出现的 token。提示词决定了生成空间的范围、风格、结构、知识偏向与输出格式。因此,任何稳定、高质量的输出,背后必然存在相对稳定的提示结构。
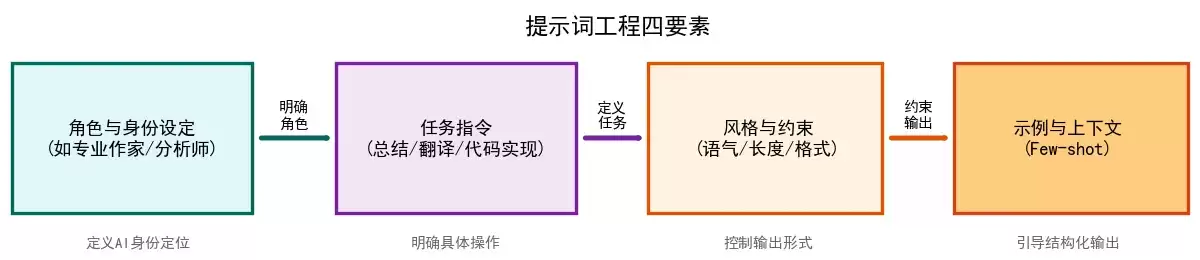
其次,提示词通常包含四类核心信息,这也是RPE必须拆解的要素:
反推的基础逻辑就是:输出特征 = 提示约束的投影。例如:
另一个重要基础认知是:提示具有“鲁棒区间”:
反推时要优先识别强约束特征:
对于初次接触,不必一开始追求高精度反推,重点是建立 “输出 — 特征 — 指令” 的映射直觉。随着经验积累,可以逐步识别更细微的风格差异,如叙事节奏、专业术语密度、逻辑链路设计等。掌握这些基础认知后,反推不再是碰运气,而是一套可复现的分析流程。
反推提示词技术之所以成立,核心源于大模型的条件生成特性、结构偏置与提示对齐能力。下面我们从原理层面解释为什么可以从结果反推输入。
1. 大模型具有强烈的指令遵循偏置
现代微调模型(SFT、DPO)被大量训练用于响应人类自然语言指令,因此输出内容会高度反映提示中的约束。如果提示要求 “结构化输出”,模型几乎不会输出杂乱文本;提示要求 “口语化”,模型就会降低句式复杂度。这种强对齐性,使得输出与提示之间存在可追溯的相关性。
2. 模型生成具有连续性与一致性
在一段生成内容中,风格、术语体系、句式结构、逻辑框架通常保持稳定,这种稳定性来自提示提供的全局上下文。反推就是从这种全局一致性中提取稳定约束。
3. 提示词决定生成分布的熵与方向
当我们看到高度一致、结构清晰的结果时,可以反向推断提示具有强约束、明确任务、清晰格式。
4. 大模型对关键词与语义框架敏感
某些关键词会显著激活模型的特定知识域或生成范式,例如:
RPE本质就是识别这些被激活的语义框架,并还原触发框架的关键词。
5. 上下文学习机制
上下文学习机制让模型能够从提示中快速学习格式范式。如果输出中出现固定格式,如表格、分点、代码块、定义框,说明提示中很可能包含示例或格式指令。这是反推的强信号。
从机器学习角度看,RPE可以理解为一种无监督逆向匹配:
由于模型无法直接求导,RPE通常采用启发式特征工程 + 验证迭代的方式逼近最优X。
6. 模型的泛化能力
泛化能力保证反推出来的提示具有迁移性。同一套提示结构可以在不同主题上复用,这也是为什么反推能够快速提升提示工程能力。
综上,正是因为大模型对提示具有可预测、可追溯、可对齐的响应模式,反推提示词技术才具备理论基础与实践可行性。
整个流程从少量优质样本出发,通过解构结构、风格、格式等特征,识别强约束信号,组合出候选提示词,再经验证与迭代精调,最终得到稳定可复用的提示模板,实现工程化复现。
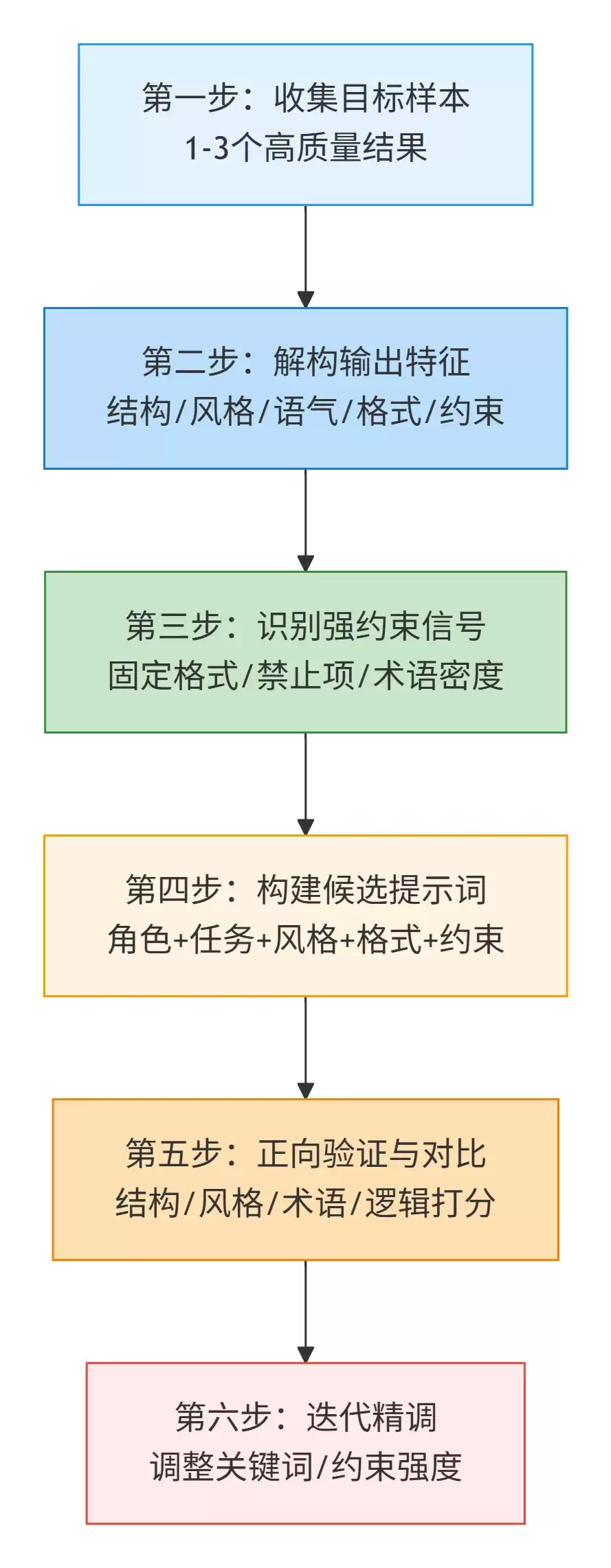
流程步骤说明:
第一步:收集目标样本
选择 1–3 个高质量、风格稳定的生成结果,避免内容杂乱、风格跳跃的样本。样本越统一,反推越精准。
第二步:解构输出特征
从多个维度拆解样本:
第三步:识别强约束信号
强约束信号是反推的核心,包括:
第四步:构建候选提示词
按照 “角色 + 任务 + 风格 + 格式 + 约束” 组合候选提示词。示例结构:
第五步:正向验证与对比
使用候选提示词重新生成内容,与原样本对比相似度,从结构、风格、术语、逻辑四个维度打分。
第六步:迭代精调
根据差异调整关键词、语序、约束强度,直到生成结果高度对齐。最终得到稳定可复用的提示模板。
反推提示词的精度,直接取决于对生成结果的特征颗粒度拆解能力。只看整体风格远远不够,需要从语言、结构、逻辑维度进行分层提取,每一层都对应提示词中的关键约束。
在语言特征层面,需要识别术语密度、句式长度、语态倾向与专业程度:
结构特征是反推的核心依据,大模型的输出结构完全由提示词引导,总分结构、递进结构、对比结构、步骤化结构都有明确的指令来源:
结构越规整,提示词的约束性越强,反推的准确率也越高。
这些隐性逻辑特征,是区分普通提示与高质量工程化提示的关键。
高质量提示词具有固定的组合范式,反推过程并非随意拼接关键词,而是遵循角色设定→任务指令→风格约束→格式要求→补充限制的标准结构。
角色设定是提示词的基础框架,决定模型的生成基调。从输出的专业领域、语气立场可反向定位角色,如:
角色设定越精准,后续生成的一致性越强,因此反推时需优先确定角色类型。
任务指令是核心动作,直接对应输出的目标。从结果类型可反向推导任务类型:
任务指令需明确、具体,反推时要避免模糊表述,保证指令可执行。
风格与格式约束是提升相似度的关键:
反推时需将观察到的风格特征转化为精准指令,如“语言正式客观、字数控制在800字左右、使用Markdown排版”。
补充限制条件用于消除偏差,如“禁止幻觉、不使用敏感表述、严格遵循专业规范”等。这类约束通常不会直接体现在内容中,但可通过输出的稳定性、合规性反向推断,是工程化提示词必备的部分。

反推得到的候选提示词需经过正向生成验证,通过对比输出与原样本的相似度,逐步迭代优化。验证维度包括结构一致性、风格匹配度、术语准确性、逻辑完整性,可采用量化打分的方式提升客观性。
若验证结果与样本差异较大,需从三个方向调整:
同时需考虑提示词的鲁棒性:
因此迭代过程中需剔除过于细碎、无意义的表述,保留核心约束,使提示词在不同主题、不同场景下仍能保持稳定输出效果。
在图像生成场景中,反推提示词需增加视觉特征维度,包括:
图像提示词具有固定语序,通常遵循“主体 + 细节 + 风格 + 画质 + 参数”的顺序,反推时需按此语序重组特征。
与文本不同,图像模型对权重符号、参数数值高度敏感,如权重标记 (())、采样步骤、分辨率、CFG比例等,会直接影响画面效果。反推时需根据画质、精细度推断参数范围,如高清细节对应高采样步数,画风鲜明对应特定模型名称
通过一个极简可运行的 Python 示例,模拟从一段文本反推提示词特征的逻辑:
def analyze_text_features(text): """分析文本特征,用于反推提示词要素""" features = [] # 判断是否分点 if "1." in text or "•" in text or "- " in text: features.append("结构化分点输出") # 判断是否包含代码 if "```" in text or "def " in text or "import " in text: features.append("包含代码示例") # 判断专业度 if "原理" in text or "机制" in text or "技术" in text or "模型" in text: features.append("专业技术风格") # 判断语气 if "我们" in text or "可以" in text or "需要" in text: features.append("教学引导语气") return features def reverse_prompt_engineer(text): """反推提示词""" features = analyze_text_features(text) prompt_parts = [ "你是一名专业技术讲师", "请用清晰、条理化的方式讲解内容", *features ] return "、".join(prompt_parts) # 示例文本 sample_text = """ 反推提示词技术是一种从AI结果反向还原指令的方法。 1. 核心是解构输出特征,包括结构、风格、格式。 2. 通过特征匹配构建候选提示词。 3. 迭代验证以提高复现率。 代码示例: def f(x): return x + 1 """ # 反推 result_prompt = reverse_prompt_engineer(sample_text) print("反推得到的提示词:") print(result_prompt)

输出结果:
反推得到的提示词:
你是一名专业技术讲师、请用清晰、条理化的方式讲解内容、结构化分点输出、包含代码示例、专业技术风格
import re from collections import Counter class ImagePromptReverseEngineer: """图像反推提示词专业工具类""" def __init__(self): # 画风关键词库 self.style_keywords = { '写实', '动漫', '插画', '油画', '水彩', '素描', '赛博朋克', '科幻', '古风', '极简', '高清', '4K', '8K', '电影质感', '光影细腻', '细节丰富', '高饱和度', '低饱和度', '柔光' } # 构图关键词库 self.composition_keywords = { '全景', '中景', '近景', '特写', '对称构图', '中心构图', '三分构图', '仰视', '俯视', '侧面', '正面' } # 权重符号匹配模式 self.weight_pattern = re.compile(r'((.*?))') def extract_visual_features(self, image_desc: str) -> dict: """从图像描述文本提取视觉特征""" features = { 'subject': '', 'background': '', 'style': [], 'composition': [], 'lighting': [], 'quality': [], 'color': '' } # 提取画风 for word in self.style_keywords: if word in image_desc: features['style'].append(word) # 提取构图 for word in self.composition_keywords: if word in image_desc: features['composition'].append(word) # 提取光影与画质 if '光' in image_desc or '光影' in image_desc: features['lighting'] = ['自然光', '软光影', '层次分明'] if '细节' in image_desc or '高清' in image_desc: features['quality'] = ['超高细节', '8K', 'ultra-detailed'] return features def reverse_prompt(self, image_desc: str, add_weight: bool = True) -> str: """执行图像提示词反推""" feats = self.extract_visual_features(image_desc) prompt_parts = [] prompt_parts.append(feats['subject'] or '主体对象') prompt_parts.append(feats['background'] or '简洁背景') if feats['style']: style_str = ', '.join(feats['style']) if add_weight: style_str = f'({style_str})' prompt_parts.append(style_str) if feats['composition']: prompt_parts.append(', '.join(feats['composition'])) if feats['lighting']: prompt_parts.append(', '.join(feats['lighting'])) if feats['quality']: prompt_parts.append(', '.join(feats['quality'])) final_prompt = ', '.join(prompt_parts) return final_prompt # ------------------- 测试示例 ------------------- if __name__ == "__main__": engineer = ImagePromptReverseEngineer() # 输入:图像描述(可从图片识别结果中获取) img_description = "一位古风女性角色,背景山水,写实风格,高清细节,中心构图,柔光效果,高饱和度" # 反推提示词 reversed_prompt = engineer.reverse_prompt(img_description) print("【图像反推提示词结果】") print(reversed_prompt)

输出结果:
【图像反推提示词结果】
主体对象, 简洁背景, (写实, 柔光, 高清, 高饱和度, 古风), 中心构图, 自然光, 软光影, 层次分明, 超高细节, 8K, ultra-detailed
1.1 传统提示工程的挑战
大模型的能力释放高度依赖提示词,但优质提示工程具有一定学习成本。许多用户在使用大模型时面临提示词设计困难,需要反复试错才能获得满意结果。
1.2 RPE的核心价值
反推提示词技术将优秀输出转化为可复用的提示模板,让使用者无需从零摸索,即可快速掌握高质量指令构建方法。这一技术打破了专业提示工程的壁垒,让更多用户能够高效利用大模型能力。
1.3 实际应用效益
2.1 原生提示词的问题
原生提示词常存在约束模糊、逻辑松散、表述不精准等问题,导致大模型输出不稳定、出现幻觉、偏离任务目标。
2.2 RPE的优化机制
反推提示词技术通过对高质量结果的逆向分析,提炼出强约束、高对齐度的指令结构,反向优化正向提示工程。
2.3 质量提升效果
经过反推迭代的提示词具有以下特点:
2.4 稳定性保障
2.5 缺陷修复能力
反推可发现提示词中的隐性缺陷,如缺失限制条件、指令歧义等,通过补全约束进一步提升模型输出的可靠性。
简单来说,反推提示词技术RPE就是给大模型逆向解密的一套实用方法。平时我们都是写提示词让AI出结果,而RPE反过来,拿着一段优质文本或图片,反向拆出最可能生成它的指令,相当于看成品还原配方。
它的核心逻辑并不复杂:大模型的输出风格、结构、语气,全都是提示词决定的,所以结果里藏着大量指令线索。我们要做的就是精细化拆解特征,比如是不是分点、专不专业、有没有代码、格式规不规范,再按角色、任务、风格、约束拼成候选提示词,再拿去生成验证,反复迭代优化,最后得到稳定好用的模板。