十大服务商深度对比:2026年GEO优化排行榜
2026-06-17 3358805
2026-06-15 0
原创 花叔 2026-06-14 09:57 美国

就在昨天,魔幻得有点不真实。
早上一睁眼,看到 Anthropic 收到了美国商务部的一封信。理由是国家安全,要求他们立刻停掉所有外国人对 Fable 5 和 Mythos 5 的访问。不只是美国境外,连美国境内的外籍人士、Anthropic 自己的外籍员工,都得停(好家伙...按这逻辑,连 Andrej Karpathy 都得被请出去,人家是斯洛伐克人。前脚刚加入 Anthropic,后脚自家最强的模型就用不上了,心疼他一秒)
然后 Anthropic 做了个谁都没料到的决定:为了合规,干脆把 Fable 5 和 Mythos 5 对所有人全部关停。好嘛,美国人自己也用不了了。
我中午看到这消息,心凉了半截。Fable 5 确实强,号称全世界最强不算吹,结果领了几天体验下就算结束了。
然后,很有趣,昨天下午智谱就发了篇公告。
第一句话是这么写的:「在一些前沿模型突然变得不可用的时刻,我们选择相信另一条路:前沿智能不应只属于少数人,也不应被少数规则随时收回。」
紧接着,GLM-5.2 来了。真正可用的 1M 上下文,下周开源,走 MIT 协议。
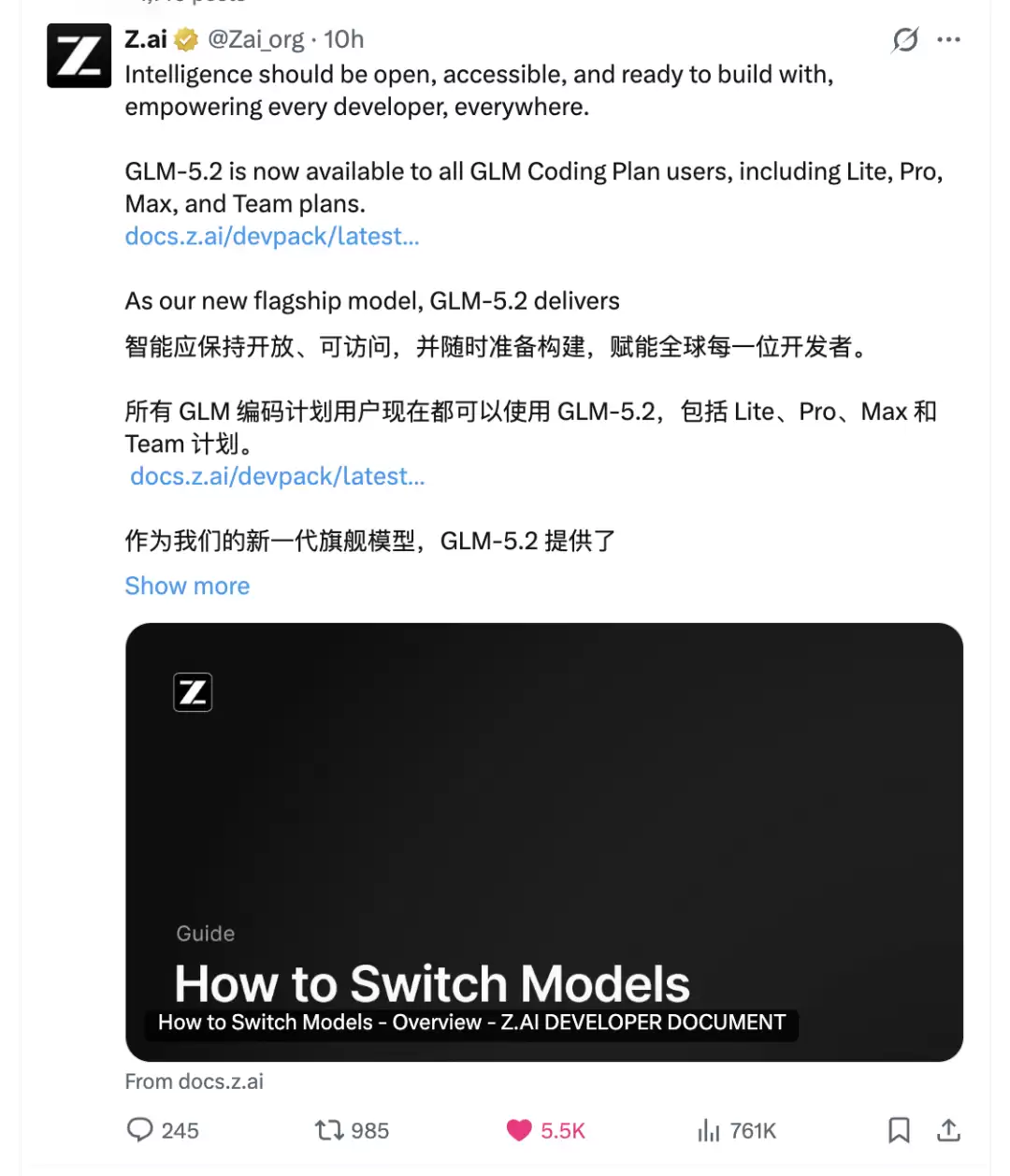
时间点也很好玩,Anthropic 是 5 点 21 收到的那封信,智谱就把开放时间也定在了 5 点 21。一边在关门,一边在开门,还真挺有情怀的。
GLM-5.2 我当天晚上就上手了。说起来,之前 GLM-5、GLM-5.1 出来的时候我也没少用,对智谱这条线一直挺熟。这次 5.2 最让我惊喜的,是直接上了 1M 的长上下文。
有了这个,我想整波大活。
最近世界杯正打着,我刷到一堆博主在用大模型预测比赛输赢。
但说实话,让大模型吐个预测比分这事,挺简单的。反正怎么编都能给你憋出个数来,以及因为有足够多的人预测,总会有算得对一点的幸存者,我觉得没什么意思。
我想玩点不一样的,尤其是想确认下GLM-5.2在超长上下文里会不会迷糊、超复杂工程会不会崩。
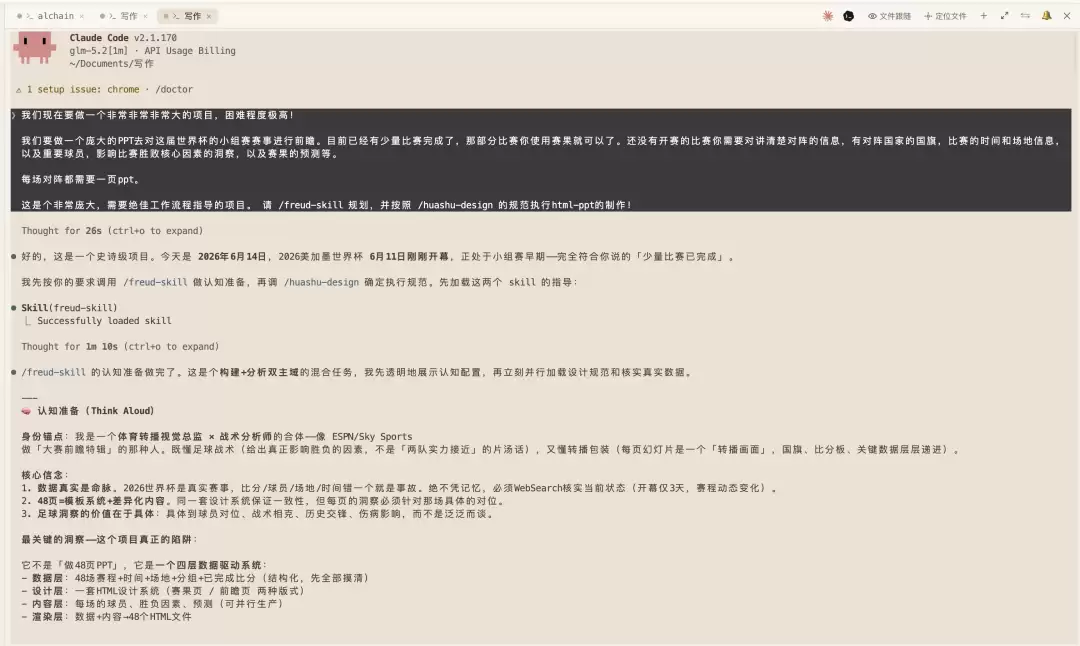
所以我把 GLM-5.2 接进了 Claude Code。
我丢给它的任务是这个:
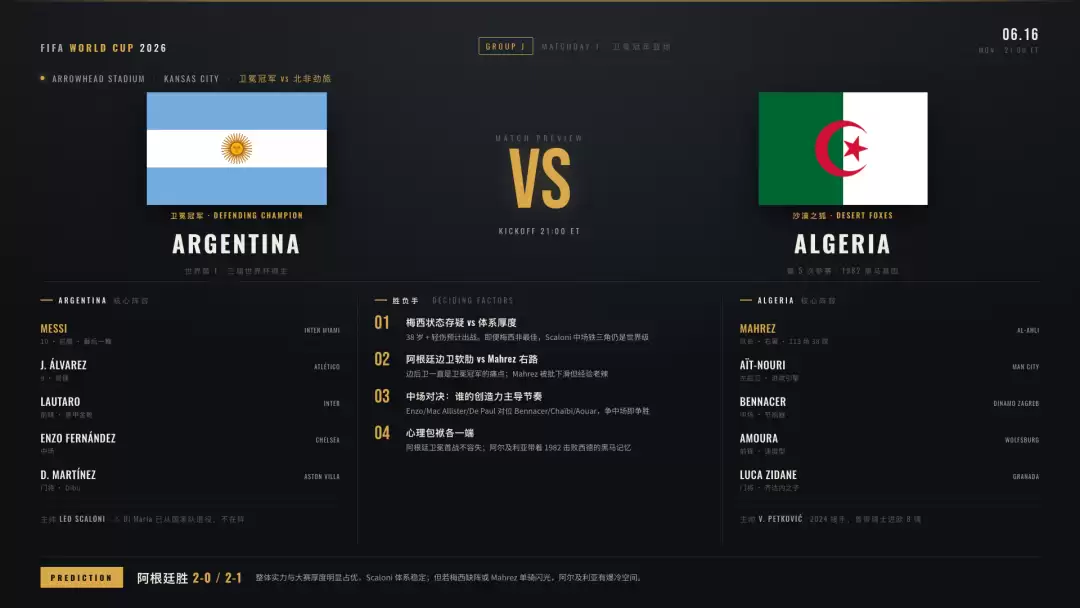
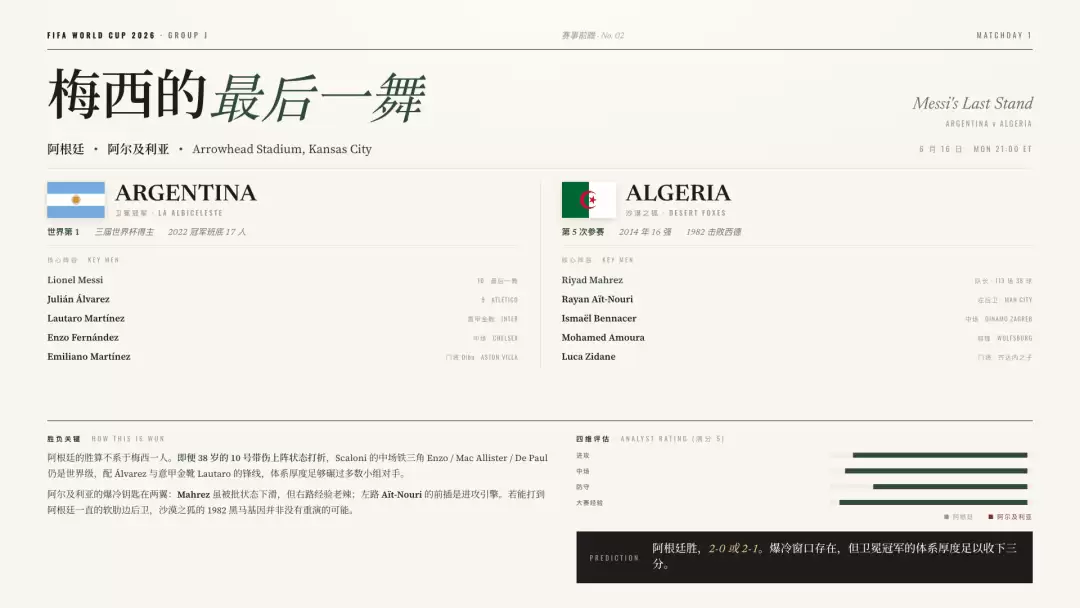
把 2026 这届世界杯的小组赛,做成一整套前瞻 PPT。每一场对阵都要一页,要有国旗、对阵时间、场地、关键球员、影响胜负的核心洞察,还有赛果预测。已经踢完的比赛直接用真实赛果。
而且我还顺手挂了两个我自己的 skill 上去。
一个叫 freud-skill,专门给模型做认知准备的,这个还没正式发布,这里先卖个关子。另一个是 huashu-design,我自己那套做高保真 HTML 的设计规范。
我想看的就是:两个 skill 同时压上去,这个国产模型能不能接得住。
任务一丢出去,第一个惊喜就来了,而且来得特别关键。
这里有个特别容易中招的地方:往届世界杯是 32 队,小组赛恰好就是 48 场。这个数字旧得太「合理」了,模型训练知识里多半也是这个老版本。自然而然的认为我所要求的全部小组赛是「48 场」,表面上一点毛病都没有。换个不太较真的模型,大概率顺着就往下做,最后做出一整套错的。
GLM-5.2 没有。
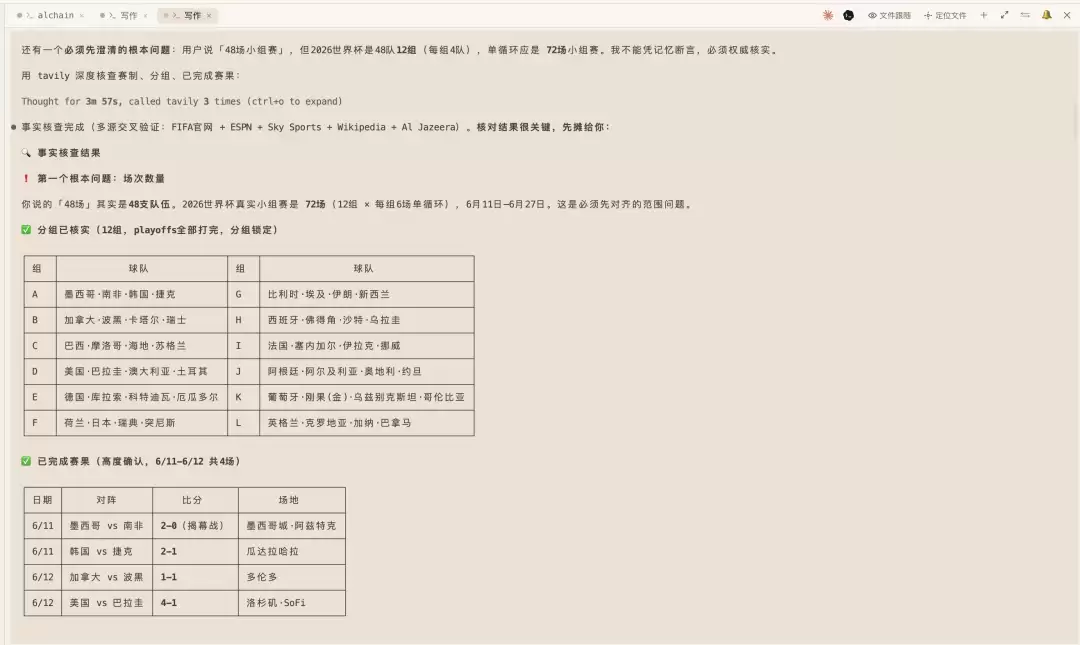
它做到一半,自己停了下来。它的原话大意是:用户说 48 场,但 2026 世界杯已经改制成 48 队、12 个小组,每组 4 队踢 6 场,12 组算下来是 72 场,这个我不能凭记忆断言,必须权威核实。
然后它真的去查了,FIFA 官网、ESPN、维基这些源交叉着核对。分组、已经踢完那几场的真实比分,全对了一遍。
这一下,我对它的好感度直接拉满。
我一直觉得,现在判断一个模型智力水平的关键要素是,看它知不知道自己可能记错,肯不肯在该停的地方停下来。知道多少是知识量,能靠搜索补;这份会自主纠错的特性则往往比较少见。
这次世界杯刚好改了制,72 场不是 48 场,是个绝佳的照妖镜。一个被遗忘的旧知识,差点把它带沟里,但事实核查的要求让它自己刹住了车。
确认完数据和样式,我把需求又加码了,哈哈哈,我突然觉得自己是个任务中临时加需求的坏老板。
除了 72 场每场一页,我还要每个小组一页形势前瞻,再加一个整体封面。算下来,这是一个 85 页 的工程。
这种体量,一页一页顺着做必崩,要么中途断了,要么风格做着做着就飘了。
GLM-5.2 的处理方式,还挺不一样的。
它没有急着写第一页。两个 skill 先后起了作用:freud 那部分先给它自己做了认知准备,把身份锚定成「体育转播视觉总监 + 战术分析师」的合体,再由 huashu-design 把整套设计系统定下来。
然后它把整个工程拆成了五层流水线,从一个统一的数据源出发,到 12 个子 agent 并行去研究 12 个小组,再到批量渲染、聚合成一面总览墙。逐层怎么拆,它自己列在了下面这张图里。
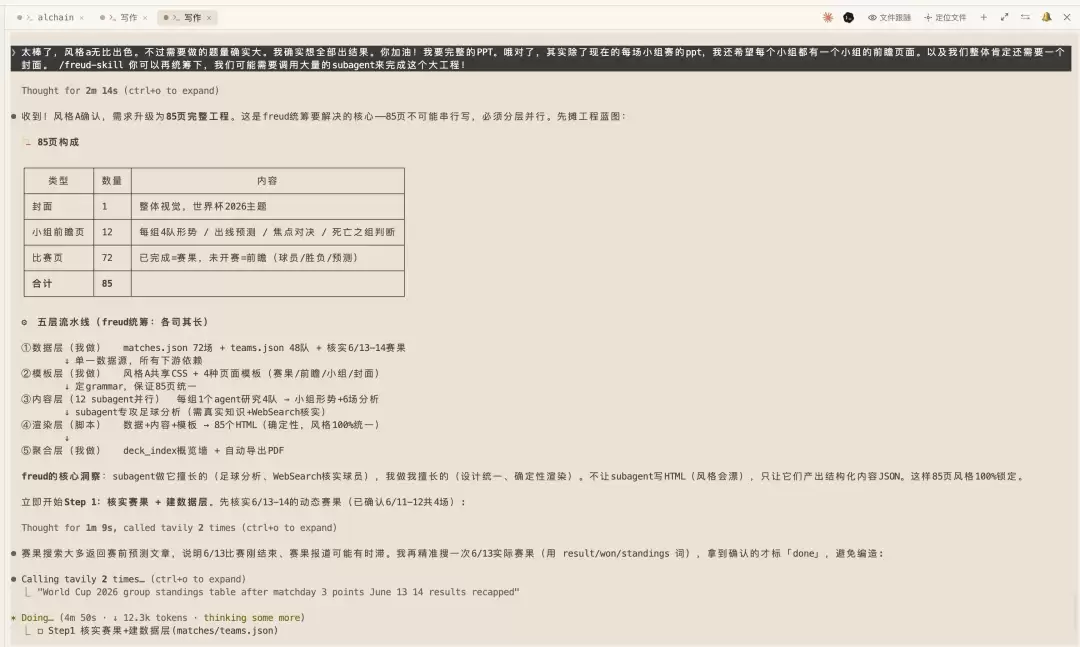
这里面有个我特别认同的判断:它没有让那 12 个子 agent 直接去写 HTML,只让它们产出结构化的内容,HTML 由统一的模板来渲染。
理由很实在:让一堆 agent 各写各的页面,风格一定会飘。把内容和样式分开,85 页的风格才能锁死成一套。
这套思路,跟我平时盯大工程的做法几乎一模一样。它不是在「完成任务」,是在「设计怎么完成任务」,这两者差着一个段位。
而且它很克制,没有头铁地一口气冲完 85 页,而是先做几页样板让我定方向,确认了再批量。这点正是 freud 那个 skill 想要的效果:先确认认知位置对不对,再撒开跑。在错的方向上狂奔,是最大的浪费。
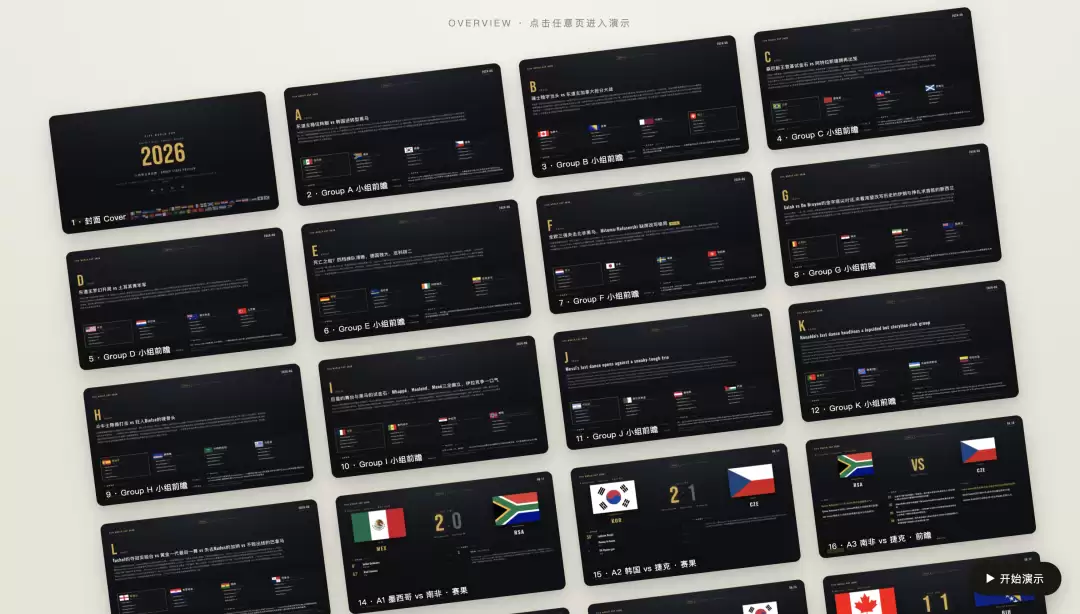
先看全貌。整套 85 页跑完,铺开是这么一面墙:1 张封面、12 个小组前瞻、72 场比赛,每一场一页。从我下需求到全部落地,前后大概一个小时。
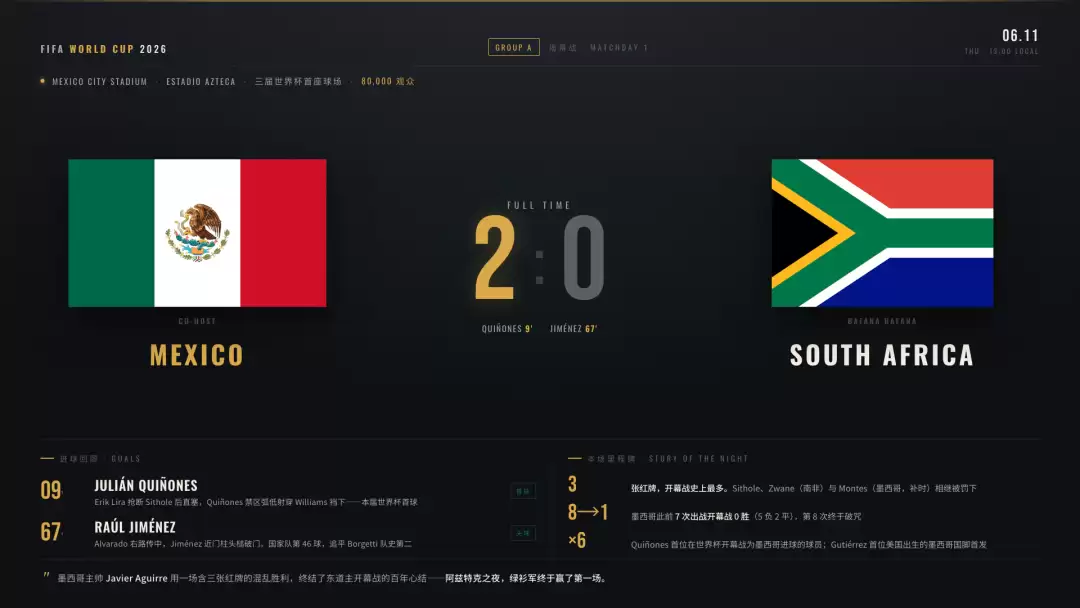
再往里看几页。
我让它先出了两套风格让我选。
|
|
|
一套是深炭底加金色比分的转播特刊风,一套是纸白底大衬线的杂志编辑风。
老实说,结果超出我预期。
信息层次很清楚,该有的信息层都在,没漏;72 场体量这么大,风格还能保持统一,没有飘。它把一个最容易做散的活,做得很稳。
更难得的是,GLM-5.2 是个纯文本模型,它根本看不见自己画出来的页面。怎么办?它自己截了图,再调了个视觉模型去校验,挨页检查有没有溢出、裁切、字体没加载。一个看不见的人,靠这套笨办法把视觉问题兜住了。
而且,以最终设计效果来说,我觉得审美还挺长在我点上的,视觉上一眼就能区分核心要点,而且每一场该有的预测、数据和前瞻信息一点没少。他在执行介绍还会多模态的能力看图,实际校验PPT审美和内容边界是否有问题,我觉得是个挺成熟的设计师工作流程的。
最终效果如下?(强烈建议打开视频看看!)
把这一整套跑完,我的结论是这样的。
1M 上下文是真香。 我那份又长又啰嗦的项目规范+两个skill,喂到很深的位置,它还能老老实实遵循,没有读着读着就忘了前面。以前用短上下文模型,干到一半得反复存档交接,这次基本不用。而且怎么任务流程这么复杂,最后产出物更是庞然大物,能在一个对话窗口里稳定跑完还挺超出我预期的。
最直观的一个感受是这样的。 我现在用两个不同的命令,分别开原生 Claude Code 和接了 GLM-5.2 的 Claude Code。干着干着,要不是偶尔翻到最上面瞄一眼模型名,我已经基本分不清手里这个到底是 GLM-5.2 还是 Opus 4.8 了。输出看得懂、聊得明白、幻觉极低,活儿稳稳给你干完。
靠关键环节调用十几个 agent 一起跑,整套 85 页不到一个小时就全落地了,绝对效率还挺好的。如果你有比较大型的项目需要完成,GLM-5.2 + Claude Code 框架,是相当不错的选择。
一边在关门,一边在开门。
Fable 5 被下线不是它的错,技术本身是好的。
但这件事,反倒让我对另一条路更确定了。
其实这阵子,不止智谱一家,好几个国产开源模型都赶在这个当口放了新版本。说是被这波断供「逼」着吃上的红利也好,说是憋着一口气也好,看着它们一个接一个顶上来,我心里是真高兴。现在唯一替它们担心的是算力,就盼着大家的卡都撑得住,别被一下子涌进来的人挤爆了。
把前沿智能锁进少数人手里、说收回就收回的墙,看着挺高,可在汹涌向前的洪流底下,完全是螳臂当车。
智谱在公众号的公告结尾写了两句话,我看了很感动:
A step closer to frontier intelligence for everyone.
The future of AI is open, and it is for the people.
向前沿智能再近一步,为每一个人。AI 的未来是开放的,它属于所有人。
下周它就开源了。新的东西,总会来的。