科技行业5月裁员38242人:创2024年以来最高纪录
2026-06-16 3357333
2026-06-16 0
最近做内容生成、代码辅助和长文整理时,我把 GPT-5.5 与上一代模型放在同一批任务里做了几轮对比。为了减少环境差异带来的干扰,我通常会在 AI 模型聚合平台库拉镜像平台leadhi.cn 里统一切换 Gemini、ChatGPT、Claude Code 等模型做测试,这类入口对开发者比较友好,不需要额外调整网络环境,也方便快速观察不同模型在同一任务下的输出差异。

这次测试的重点不是看谁“回答更长”,而是看稳定性。
所谓稳定性,主要包括四个方面:
输出是否跑题、格式是否一致、逻辑是否前后冲突、连续多次生成是否保持质量。
对于开发者来说,这比单次惊艳回答更重要。
因为真正接入业务后,模型不是只跑一次,而是每天、每小时、甚至批量执行任务。
一、测试任务怎么设计?
为了更接近实际使用,我没有只测聊天问答,而是选了几类高频场景。
包括:
技术文章摘要
API 文档解释
简单代码生成
Bug 原因分析
产品需求拆解
表格化信息整理
每个任务都用相同提示词,连续执行多轮,然后看输出是否稳定。
比如在“技术文章摘要”任务中,我要求模型输出固定结构:
背景、核心问题、解决方案、风险点、结论。
如果模型第一轮能按格式输出,第二轮却变成自由发挥,这就说明稳定性不足。
二、GPT-5.5 最大变化:更少“自我发挥”
和上代模型相比,GPT-5.5 一个比较明显的变化是:更愿意遵守任务边界。
上代模型在内容生成时,经常会出现一种情况:表达很流畅,但会主动补充一些原文没有的信息。
这对普通写作影响不大,但对技术内容就比较麻烦。
比如原文只说“接口响应延迟较高”,模型可能会扩展成“数据库索引设计不合理导致延迟升高”。
这听起来合理,但如果原文没有依据,就属于过度推断。
GPT-5.5 在这类任务里更克制。它通常会把“不确定”“需要进一步排查”“原文未说明”这类边界标出来。
这点对技术社区内容很重要。
三、格式稳定性提升比较明显
在实际工作里,很多人使用 AI 不是为了看一段漂亮文字,而是为了拿到可处理的数据结构。
比如 Markdown 表格、JSON 草稿、需求列表、测试用例。
上代模型偶尔会出现格式漂移:
你要求输出表格,它前面是表格,后面变成段落;
你要求固定字段,它会临时新增字段;
你要求不解释,它还是补充一大段说明。
GPT-5.5 在这方面更稳,尤其是结构化输出任务。
下面是一个偏实战角度的对比:
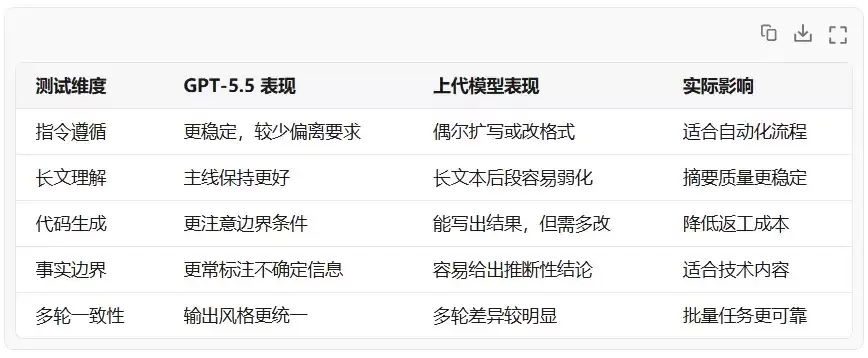
可以看出,GPT-5.5 的提升不是简单的“更聪明”,而是更适合进入稳定流程。
四、代码任务里的差距更接近“工程化”
在代码生成测试中,我让两个模型分别完成一个简单接口封装任务。
要求包括:
支持异常处理、返回统一结构、加基础注释、不要引入复杂依赖。
上代模型通常能写出可运行代码,但有时会忽略异常分支,或者加入一些没有要求的库。
GPT-5.5 的代码不一定每次都最短,但更倾向于保留边界处理。
比如它会主动处理空参数、接口超时、返回值为空等情况。
这说明模型在理解“可用代码”和“演示代码”的区别上更进一步。
不过也要说清楚:AI 生成代码仍然需要人工 review。
尤其是权限、数据、并发、性能相关逻辑,不能直接复制上线。
五、长文任务里,上代模型的问题更明显
长文提炼是最能体现稳定性差距的场景之一。
上代模型在处理长材料时,前半部分通常总结得不错,但到了后半部分容易变得笼统。
有时它会把多个观点合并,导致原文的层次被压平。
GPT-5.5 更擅长把内容拆成模块。比如一篇关于 AI 应用落地的长文,它通常会分清:
行业背景、技术路径、落地案例、成本问题、风险限制、未来趋势。
这让后续二次加工更方便。
对于写技术博客、整理会议纪要、做知识库沉淀的人来说,这种差异很实际。
六、差距是不是“巨大”?
我的判断是:单次简单问答,差距不一定特别明显。
如果只是问一个概念解释,或者写一段普通文案,上代模型仍然够用。
但一旦任务变成“多轮、长文本、结构化、可复用”,GPT-5.5 的稳定性优势就会放大。
它更像是从“能回答问题”升级到“能参与流程”。
这也是当前大模型发展的一个趋势:
不再只比拼谁生成得更华丽,而是比谁更可靠、更可控、更适合接入真实业务。
七、给开发者的使用建议
如果你只是偶尔写文章、改标题、做简单问答,上代模型依然有性价比。
如果你要做以下事情,GPT-5.5 更值得优先测试:
批量生成技术内容
整理长文档和会议纪要
生成固定格式数据
辅助代码开发
搭建 AI 工作流原型
使用时建议把提示词写得更明确,比如限定输出格式、字段名称、是否允许补充信息。
不要只写“帮我优化一下”,而要写清楚优化目标。
总结
GPT-5.5 相比上代模型,最大提升不是单点能力,而是稳定性更强。
它在指令遵循、长文理解、格式保持、边界控制和多轮一致性上,都更接近实际工程需求。
如果说上代模型适合“单次辅助”,那么 GPT-5.5 更适合“持续协作”。
对开发者和内容团队来说,这个变化比参数规模更值得关注。真正决定模型能不能落地的,往往不是它最好的一次回答,而是它能不能稳定地产出可用结果。