0.6B VLM重塑AI修图推理流程:支持手机端侧部署 vivo+浙大出品
2026-06-16 3357450
2026-06-16 0
魔搭ModelScope社区 2026-06-15 19:54 美国
上海交大等机构联合发布首个通用音频编辑评测基准MMAE,涵盖2000条真实场景任务。评测显示,当前最强模型指令遵循率仅约50%,完美编辑率不足5%,揭示音频编辑技术距实用仍有较大差距。
01
引言
上海交通大学、上海创智学院、南洋理工大学、腾讯混元团队、天津大学、数搭国际数据开源社区、北京大学、复旦大学等机构联合发布 MMAE(Massive Multitask Audio Editing Benchmark),首个面向通用指令式音频编辑的综合评测基准。MMAE 包含 2,000 条真实场景音频编辑任务与 17,741 条细粒度 rubric 评测项,系统覆盖 7 种模态、6 级难度、8 类操作。团队对 5 款主流音频编辑模型做了全面"体检",结果显示:即便表现最优的模型,指令遵循率也仅在五成上下,完美编辑率(EMR)更是全部低于 5%
开源地址:
ModelScope:https://modelscope.cn/datasets/ddlBoJack/MMAE
Github:https://github.com/ddlBoJack/MMAE
01
数据集构成
| 维度 | 内容 |
| 数据规模 | 2,000 条高保真测评样本 + 17,741 条 rubric 评测项 |
| 覆盖模态 | 7 种:sound / music / speech 及其两两、三者混合(sound-music / sound-speech / music-speech / sound-music-speech) |
| 难度分级 | 6 级:single / multi-part / multi-instruction / multi-audio / multi-round / multi-hop;从简单单步操作到多主体、多指令、多音频输入、多轮迭代、多跳推理 |
| 操作粒度 | 2 级:local(局部)/ global(全局) |
| 操作类型 | 8 类:local addition(增) / local removal(删) / local replacement(改) / local extraction(查) / local alteration(属性编辑) / global background change(背景编辑) / global foreground change(前景编辑) / global alteration(属性编辑) |
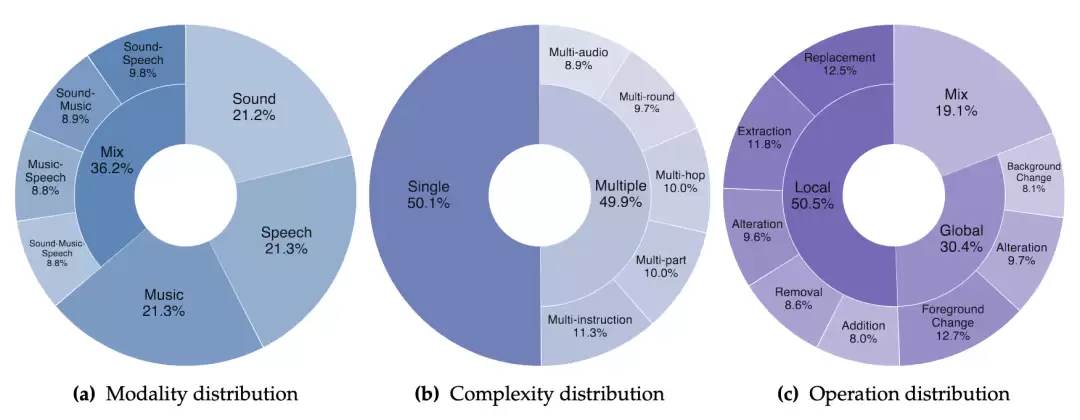
△ MMAE在三个维度上的数据分布

△ MMAE中覆盖不同模态、复杂度、操作类型的数据示例
02
数据构建与评测方法
MMAE 所有测评样本均来自真实场景音频,而非合成数据。初始标注由专业团队通过人机协作(Human-LLM Collaboration)完成,再经过多轮精细化修订与独立审核:每条数据都由不同于原标注者的审核人员复核,不达标的样本被反复修正或淘汰,以保证数据高质量、无歧义、可验证。
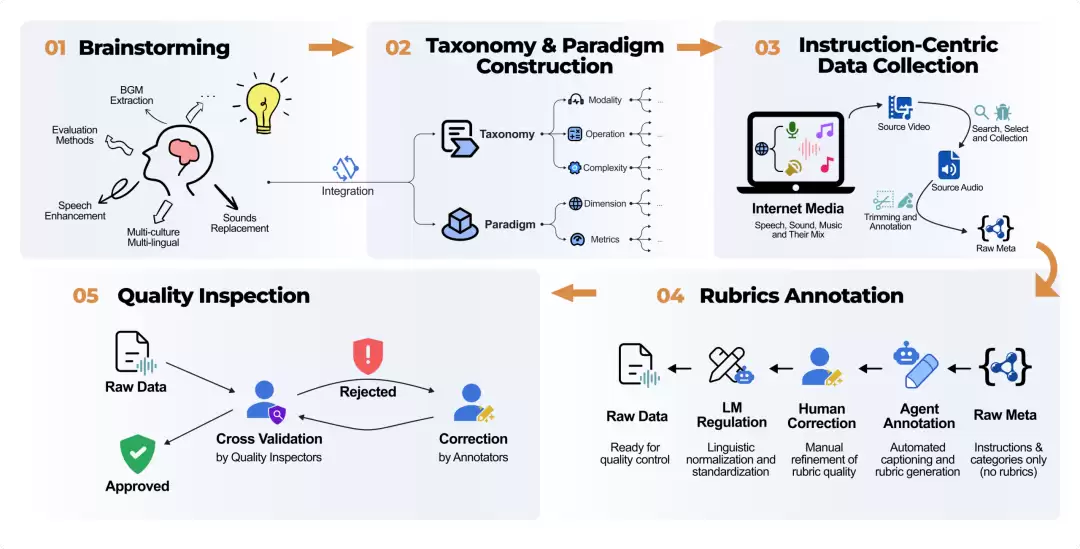
这是 MMAE 区别于传统评测的核心创新。FAD、CLAP 等粗粒度指标只能给出"总体打分",无法定位模型究竟在哪一环节出错。MMAE 为每条样本平均设计约 9 条细粒度 rubric,每条都是一个原子化选择题,分别从两个维度评估:
IFR(Instruction Following Rate,指令遵循率):指令要求的修改有没有做到。
CR(Consistency Rate,一致性率):指令未涉及的部分有没有被破坏。
同时引入EMR(Exact Match Rate,精确匹配率):仅当一条样本的所有 rubric 全部通过才计为成功。这套设计既保证可解释性(哪一环出错一目了然),又能有效阻断"只改不保"或"只保不改"的投机策略。
以一个多音频任务为例,指令为"把音频 2 的歌词全改成 'Hachimi',声音用音频 1 的音色",对应 5 条 rubric:歌词是否为反复出现的"Hachimi"(IFR)、音色是否接近音频 1(IFR)、伴奏是否与原音频 2 基本一致(CR)、旋律节奏是否被改动(CR)、是否出现音质劣化(CR)。
17,741 条 rubric 通过流水线自动化生成:先用Omni-Captioner中提出的 Omni-Detective 管线提取音频细粒度标注,再由 LLM 批量生成草稿,最后人工审核修正。评分阶段由多模态大模型 Qwen3-Omni 担任"阅卷老师"逐条判分;为降低位置偏见,每次评分随机打乱选项顺序,每条 rubric 独立评估 3 次取多数决。
03
实验结果
| 关键发现 | 数据 |
| 最强模型(全集)Step-Audio-EditX | Step-Audio-EditX | IFR 44.86%,CR 58.88% |
| 最强模型(≤10s子集)Audio-Omni | Audio-Omni | IFR 50.73%,CR 56.93% |
| 所有模型的完美编辑率(EMR) | 均低于5% |
进一步分析表明,随着任务复杂度的提升(从单步操作到多轮、多跳、多指令),模型性能显著下降;在涉及多模态混合(如语音、音乐与环境音同时存在)的场景中,模型表现更是大幅退化。这表明,当前方法在简单情境下具备一定能力,但距离真实复杂应用场景仍有明显差距。
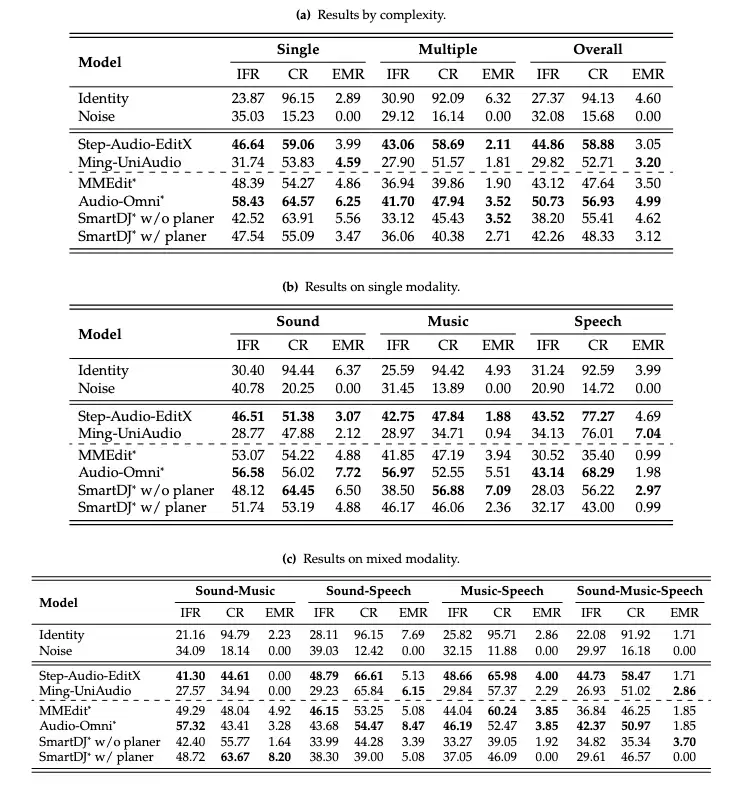
△ 主要实验结果
此外,实验还揭示出若干值得关注的现象:
仅看单一指标容易对模型能力产生误判:例如,Identity 基线直接输出原始音频,不执行任何编辑操作,能获得 94.13% 的 CR,部分提取任务也能拿到一些IFR分数;而 Noise 基线输出纯噪声,虽然完全破坏了原始输入,但在部分删除类任务中也可能获得较高的 IFR。这说明音频编辑本质上同时包含两个目标:既要准确完成修改,又要尽可能保留原有内容。只关注其中任何一项,都可能让模型通过“投机策略”获得不错分数。因此,MMAE 将 Instruction Following 与 Consistency 作为两个独立的评测维度,并引入EMR指标,对编辑能力进行更全面的刻画。
Agent机制提升有限:SmartDJ在引入Gemini 2.0 Flash 进行规划后,IFR略有提升,但CR有所下降。这表明当前系统在“理解”(规划准确性)与“执行”(编辑可靠性)两个层面仍存在瓶颈,提示基础模型能力仍需进一步加强。
平均能力与完美执行存在差异:尽管Step-Audio-EditX 在IFR与CR上均优于 Ming-UniAudio,但其EMR反而略低。这反映出模型在“覆盖更多任务类型”与“确保单个任务完全正确”之间存在权衡,也提示平均指标并不能完全反映系统整体可靠性。
04
上手实践
MMAE 使用 Qwen3-Omni 作为评判模型,依据评分标准对音频编辑输出逐条打分。完整评测分三步。
步骤 1:部署 Qwen3-Omni
克隆官方仓库并按其说明配置环境:
gitclonehttps://github.com/QwenLM/Qwen3-Omni.gitcdQwen3-Omni# 按官方 README 安装依赖
随后启动 vLLM 服务。仓库提供了参考部署脚本launch_qwen3_omni.sh
,会在 8 块 GPU 上启动两个 Qwen3-Omni 实例(每个 tensor-parallel=4),分别监听 8001 与 8002 端口。需将脚本中的MODEL_DIR
改为本地模型权重路径。
步骤 2:准备预测结果
在 MMAE 基准输入数据(元数据)上运行你的音频编辑模型,在原始 chatml 格式的messages后追加一条assistant回复,写入输出音频路径:
{"id":"69e897fbf1844435bec75eca","messages":[ {"role":"user","content":[{"type":"text","text":"Extract the music component from the audio."},{"type":"audio","audio_url":"wav/69e897fbf1844435bec75eca/audio1.wav"} ]}, {"role":"assistant","content":[{"type":"audio","audio_url":"your_output_wav_path"} ]}]}
audio_url
可为绝对路径,或相对于预测文件目录(或--audio_root
)的相对路径。将修改后的元数据另存为 JSON,即为模型预测结果。
步骤 3:运行评估
python-m eval.score --predictions path/to/your_predictions.json --base_urls"http://localhost:8001/v1,http://localhost:8002/v1" --audio_root path/to/audio_root --output_dir outputs/your_model --concurrency8
点击阅读原文,获取详细信息
?点击关注ModelScope公众号获取
更多技术信息~
阅读原文