高通推出骁龙START计划 推动个人AI终端加速落地
2026-06-20 3361915
2026-06-20 0
原创 罗西的思考 2026-06-18 20:16 浙江

0x00 概要
0x01 Rollout基础
1.1 概念
1.2 RL2 对比
0x02 OpenClaw-RL Rollout基础
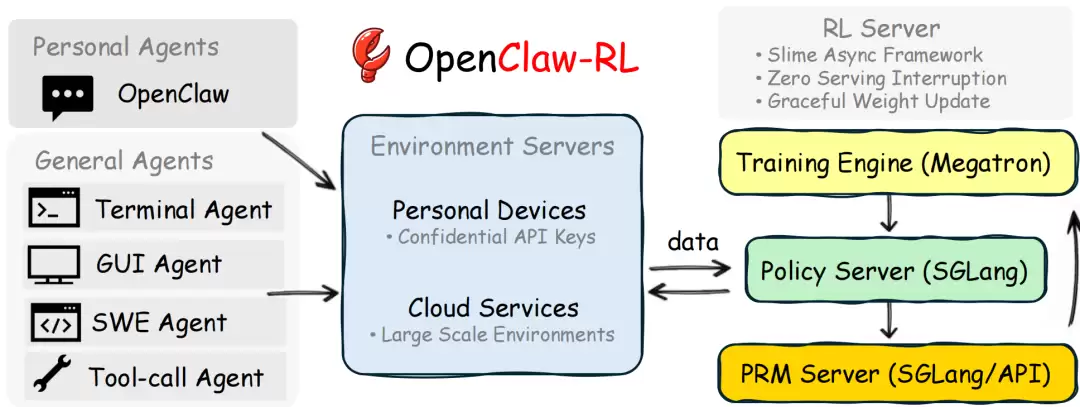
2.1 硬件架构
2.2 总体模块交互架构图
2.3 Slime 的 RolloutFunction 封装
2.4 被动Rollout
2.5 小结
0x03 OpenClaw-RL Rollout 实现
3.1 Rollout 完整流程
3.2 Session 生命周期
3.3 At-Least-One Guarantee
0x04 AsyncRolloutWorker
4.1 功能
4.2 示例图
4.3 三个核心职责
4.4 与 OpenClawAPIServer 的协作机制
0xFF 参考
本系列的目的是:借着对 OpenClaw-RL 源码的学习,来梳理强化学习的一些相关概念和思想。所以,会有一些基础知识、扩展和发散,OpenClaw-RL 只是一个切入点。而且,因为整篇系列是一个整体,所以有些概念的解读/学习会在不同的文章中出现,还请大家谅解。
OpenClaw-RL 是一个用于在线强化学习(Online RL)的框架,专门针对智能体工具使用场景。它通过从环境反馈中提取过程奖励信号来训练语言模型,支持三种主要模式:
openclaw-rl:基于二元奖励的强化学习(Binary RL / GRPO)
openclaw-opd:基于后见之明提示的在线策略蒸馏(On-Policy Distillation, OPD)
openclaw-combine:联合方法,在同一 PPO 更新中同时利用 RL reward 和 OPD teacher signal
可以把 RL 训练管道划分为如下5 个阶段(会有重叠,依据不同系统而不同),本篇介绍Rollout。
Stage1 Stage2 Stage3 Stage4 Stage5────────────────── ───────── ───────── ─────────PromptRolloutRewardAdvantage GradientSelectionGenerationScoringComputationUpdate"问什么""怎么答" "打几分" "好了多少""往哪走"
Rollout = 用策略在环境中执行并产生轨迹 τ = (s₀, a₀, r₀, ..., sₜ, aₜ, rₜ)。
在 RL 框架中,"rollout" 这个词同时指代:
含义 1: 过程 (动词):"doing a rollout" = 用策略在环境中生成一条轨迹的过程
含义 2: 结果 (名词):"the rollout" = 生成出来的那条轨迹数据,包含: tokens, log_probs, reward, loss_mask 等。
在Slime代码中,generate_rollout_openclaw()函数名用的是含义 1(执行rollout过程),返回的 RolloutFnTrainOutput(samples=...)是含义2(rollout的结果数据)。
Rollout = 在环境中执行策略,产生一条完整的交互轨迹(trajectory)。
形式化:
给定策略 π 和环境 E一次 rollout 产生一条轨迹 τ: τ = (s₀, a₀,r₀, s₁, a₁,r₁, ..., sₜ, aₜ,rₜ)其中:s₀ ~ ρ₀ (初始状态,从 prompt 分布采样)aₜ ~ π(・|sₜ) (策略生成 action)sₜ₊₁ ~ P (・|sₜ,aₜ) (环境转移)rₜ =R(sₜ, aₜ)(环境给出奖励)
在 LLM RL 中,Rollout = 给定一个 prompt, 模型生成一个完整 response + 记录 log-probs + 打分。当然,也有人这么归纳:一次 rollout = 给定一个 prompt, 模型生成一个完整 response
s₀ = prompt (初始状态)a₀, a₁, ..., aₜ = response 的每个 token (一系列 action)r = 对整个 response 的打分 (terminal reward)轨迹 τ = (prompt, token₁, token₂, ..., tokenₜ, reward)
注意: LLM 的 rollout 通常是 single-step episode (一轮就结束), 不像游戏有多步交互。
一个 GRPO rollout batch:
采样 B 个 prompt
每个 prompt 生成 N 个 response
总共 B × N 条轨迹
每条轨迹包含:
prompt (input)
response tokens (actions)
log π_old (a_t | s_t) (旧策略的 log-probs, 用于后续 PPO ratio 计算)
reward (打分)
OpenClaw 的 "rollout"的特点:
不主动生成
等用户对话 → 从 queue 收集
凑够 rollout_batch_size 个样本 = 一次 "rollout"
每条轨迹包括:
prompt = 用户消息 (s₀)
response = 模型回复 (a₀...aₜ)
rollout_log_probs = SGLang 生成时记录的 log π_old (用于 PPO ratio)
reward = PRM 评分 {-1, 0, +1}
(OPD) teacher_log_probs = teacher 的 log-probs
主动和被动的对比如下。
标准 RL Rollout:────────────────────────────────────────────────dataset = load ("math_data.jsonl")forpromptindataset.sample (batch_size): ← 主动选题responses = model.generate (prompt, n=4)← 主动生成 N 个forrespinresponses:score = reward_model (resp)submit (prompt, resp, score)OpenClaw Rollout:────────────────────────────────────────────────@openclaw_rollout.pydefgenerate_rollout_openclaw(...):worker.resume_submission()← 打开阀门whilelen(data) < rollout_batch_size:data += queue.get()← 等!等用户发消息awaitasyncio.sleep(0.05) ← 继续等...worker.pause_submission ()← 关阀门returndata # 数据从哪来?从 API Server 的请求处理流程来 # rollout 函数本身不生成任何数据!
具体可以参见下表
| 标准 | OpenClaw | |
|---|---|---|
| 谁控制prompt? | 训练系统 | 用户 |
| 谁控制N? | 训练系统(n=4~16) | 用户(永远n=1) |
| 数据到达时间 | 确定的(GPU生成速度) | 不确定的(等用户) |
| --disable-rollout-global-dataset | 不需要 | 必须(没有dataset) |
我们用 RL2 这个框架来做对比,看看它是怎么做rollout的。
RL2 的本质架构为:在同一组 GPU 上交替做推理和训练。或者说,RL2 = 一个on-policy RL循环,把LLM当policy network,把推理服务器当采样器。
展开核心数据流如下:
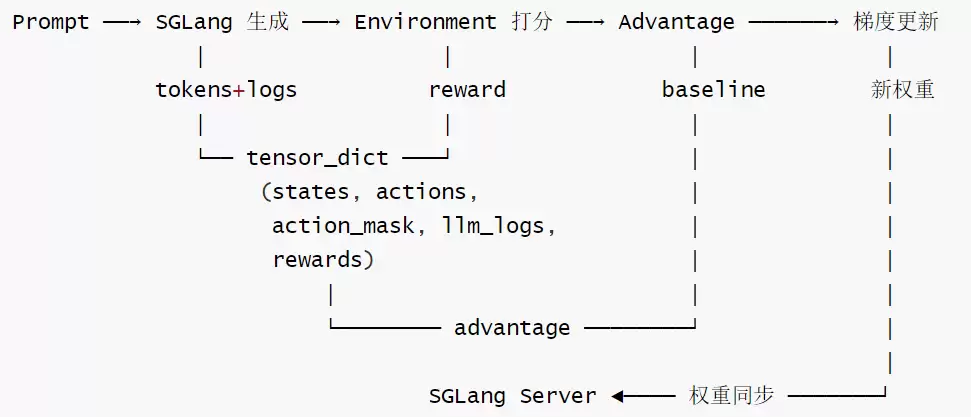
三个核心子系统及其职责:
Rollout = SGLang推理 + 环境交互 → 产出(token序列,reward)
Actor/Critic = FSDP分布式模型 → 计算logps/values → 反向传播
Environment = env_step(action)→ reward(规则/外部API/LLM judge)
注意:
Reward 不是独立模块—它集成在 env_step 内,实现方式完全灵活(规则/外部服务/LLM judge)
PRM 可通过多轮环境实现—每个 step 返回中间 reward,累加到轨迹中
整个 Rollout 是异步的—SampleGroup 并发、env_step 可调外部网络、SGLang 请求并发
所有组件共享同一组 GPU—通过 offload + memory occupation 管理实现时分复用
在 OpenClaw-RL 中,Rollout 是Policy Serving + Environment 的交叉。
Rollout = 在环境中执行策略,生成完整轨迹的过程 = Policy的推理输出 × Environment的状态转移
Rollout的完整循环如下:
Environment提供 State(t)(用户消息)↓Policy Serving 执行推理 → Action(t)(模型回复)↓Environment 接收 Action(t) → Environment 提供 State(t+1)(用户下一条消息)↓重复,直到 session 结束
在 OpenClaw-RL 的硬件架构中,GPU 4-5 的名称是 "SGLang Rollout Engine"。但它实际负责的是 rollout 的 Policy Serving 侧:
→ 接收 HTTP 请求(用户消息)
→ 运行 LLM 推理,生成 token
→ 返回模型回复
rollout 的 Environment 侧(用户行为)在 GPU 之外:
→ 用户什么时候发消息? → 外部世界决定
→ 用户发什么内容?→ 外部世界决定
→ 用户是否继续对话?→ 外部世界决定
┌──────────────────────────────────────────────────────────────┐│ Rollout(概念上) ││ ││ ┌─────────────────┐ ┌───────────────────────┐││ │ Policy Serving │ │ Environment│││ │ GPU4-5│ + │ 真实用户(外部) │││ │ LLM 推理生成回复 │ │ 提供state、接收 action │││ └─────────────────┘ └───────────────────────┘││ │└──────────────────────────────────────────────────────────────┘
OpenClaw-RL 总体模块交互架构图 (Combine 方法)如下,可以从中找到Rollout相关内容。

在代码层面,Slime用一个函数封装了rollout的全部逻辑:
# openclaw-rl/openclaw_rollout.pydefgenerate_rollout_openclaw(args, rollout_id, data_buffer, evaluation=False): """Slime 的 rollout function:标准rollout(主动生成):rollout_engine.generate(prompts) → 直接调LLM生成轨迹= Policy Serving(GPU4-5)自己完成整个rolloutEnvironment是静态的(题目数据集)OpenClaw的被动rollout:等待_sample_queue.get()→ 从真实用户对话中取已完成的轨迹= PolicyServing已经完成了(对话已结束)= Environment已经交互过了(用户消息已收到)这里只是“收集“已经发生的rollout"""whilelen(samples) < batch_size:sample=_sample_queue.get(block=True)#被动等待returnsamples
-disable-rollout-global-dataset的含义就是:
告诉Slime:“不需要你主动用LLM生成rollout"
"我的rollout由真实用户+Policy Serving联合产生,你只管拿已完成的样本“
具体如下图。
Slime 训练框架调用: generate_rollout_openclaw(args, rollout_id, data_buffer) | | passive rollout: | 不主动生成, 等待真实对话产生数据 ▼ +---------------------------------------+ | worker.resume_submission()| <- 开启 submission_enabled Event |_drain_output_queue() | <- 等待 rollout_batch_size=16组 +---------------------------------------+ | | ▼ (数据由异步 FastAPI handler 填入)
OpenClaw-RL的rollout是被动rollout。generate_rollout_openclaw()等待真实用户发消息,而非主动从prompt池中选择问题生成回答。这意味着系统对rollout allocation(选什么问题训练)几乎没有控制权,由用户决定。
优势:
训练数据 = 真实用户对话,天然分布对齐,无train-deploy distribution gap
用户多样性天然提供entropy保障和batch内reward方差
无需维护prompt数据集
劣势:
无法做curriculum learning(由简到难)
无法增大group size G(每turn只有一条用户消息)
无法做dynamic sampling(不能要求用户“换个问题再问")
Rollout allocation 几乎完全失控
概念上:Rollout = PolicyServing + Environment 两者的交互过程,不专属任何一方
架构上:GPU 4-5标记为“Rollout Engine",但只承担了Policy Serving(推理)侧的工作
代码上:generate_rollout_openclaw是被动收集器,真正的rollout在FastAPI服务器处理用户请求时已经完成

关键设计要点
| 机制 | 实现方式 |
|---|---|
| next_state 滞后 | turn N 的 next_state = turn N+1 请求里 messages 的最后一条 |
| PRM 异步 | asyncio.create_task + done_callback 触发提交 |
| at-least-one | session 全为 score=0 时,首个 turn 强制 loss_mask=1 |
| 权重同步暂停 | submission_enabled Event 控制,同步中返回 503 |
假设我们session含有三轮。
turn1→[buffered, waiting next_state]turn2→ flush turn1(next_state=turn2.messages[-1]) → PRM(turn1) fireturn3→ flush turn2(next_state=turn3.messages[-1]) → PRM(turn2) firesession_done=True → flush last_turn(next_state=None) → force_no_prm
下图展示了 rollout 的 3-turn 示例。


关键时序:next_state的"延迟到达“机制
Turn 1发生时:
用户发消息M1→SGLang生成R1→返回给用户
此时:R1的next_state还没有(用户还没回复)
→_pending_records[session_id] ={response_text: R1} ,等待Turn 2
Turn 2发生时(用户发M2=Turn1的next_state):
用户发消息M2 → _handle_request()被调用
→ messages[-1]=M2=Turn 1的 next_state ← 此刻才可用!
→ _flush_pending_record(session_id,M2)被调用
→ _fire_prm_scoring(R1,next_state=M2)被触发(异步)
→ 同时SGLang生成R2→返回给用户
→ _pending_records[session_id]={response_text:R2},等待 Turn 3
PRM评估R1的结果异步返回:
→ _submit_turn_sample(turn_data_1,prm_result_1)
→ output_queue.put(Sample(loss_mask=..., reward=score_1))
这个设计导致:每个 turn的 reward来自下一个HTTP请求到达的时刻,而非当前请求结束的时刻。这是OpenClaw Rollout 中最独特的工程设计。
At-Least-One Guarantee 的作用是:防止整个session贡献零梯度,确保即使最"平庸"的session也有一个turn进入训练,=Reinforce-Ada"强制至少一个梯度"的session级版本。
At-Least-One Guarantee 是最直接的零梯度修复。
具体如下:第一个被 PRM 评过(has_next_state=True)但 score=0 的 turn → 强制 loss_mask=[1],参与训练 → 至少每个 session 贡献一个样本。
# _submit_turn_sample() 中的核心逻辑:exclude =nothas_next_stateorscore ==0.0# 正常情况:score = 0 → exclude=True → loss_mask=[0,0,...,0]# 但是!特殊保障:ifexcludeandhas_next_stateandself._session_effective.get(session_id,0) ==0:exclude =False# ← 强制参与训练! # "at-least-one guarantee"# openclaw_api_server.py:615-622# 使用 _session_effective 计数器追踪每个 session 的有效样本数# 首个 has_next_state 但 score=0 的 turn → 强制 exclude=Falseifexcludeandhas_next_stateandself._session_effective.get(session_id,0) ==0:exclude =False# ← 强制参与训练! # "at-least-one guarantee"# 之后 self._session_effective[session_id] += 1
情景:整个 session 的所有 turn 都 score=0
详述:用户发了 5 条消息,但每次都是中性反馈(score=0) → 所有 turn loss_mask=[0] → 这个 session 对训练没有任何贡献 → 分母增大但分子不变 → rollout_batch_size 难以填满 → 训练停滞
问题逻辑:all loss_mask=[0] → 整个session 贡献零梯度
At-Least-One 触发:
records[0]["loss_mask"]=[1]强制打开第一个turn 的门
reward不变=0.0
此时的梯度情况:
loss_mask=[1](门打开了)
reward=0.0 → advantage由GRPO的批内归一化决定
→ 在训练 batch 中,与来自其他 session的+1/-1样本一起归一化
→ 这个0.0 reward的样本advantage ≈ 0(在均值附近)
→ 贡献的梯度接近但不等于零
at-least-one的真正价值:
确保Policy不会在这类对话上“完全不见光“
即使效果微弱,也让这种回复参与了分布的锚定
→ 防止Policy在这类对话上悄悄退化
loss_mask=考试是否交卷
0=这次不参加考试(完全不影响成绩)
1=参加考试(成绩会影响最终评价)
advantage=这次考试得了几分(正分/负分)
正值=这次考得好,鼓励这种答题方式
负值=这次考得差,惩罚这种答题方式
~0=这次成绩平平,基本没有反馈
at-least-one=“就算这次内容不好,也必须交卷"
强制loss_mask=1,哪怕advantage=0
至少这次答题留下了记录,不会被系统彻底忽视
两种方式理论上都产生零梯度(在kl-coef=0时)
实践中loss_mask=0更优:
效率:直接跳过这些token的梯度计算(节省计算)
语义清晰:明确表达“这个turn没有学习价值,不参与训练“
与--kl-coef=0.0一致:如果有KL惩罚,advantage=0的token仍会通过KL term产生梯度,loss_mask=0彻底排除,避免这种副作用
Binary RL的具体问题:训练饥饿(training starvation)
设想一个极端场景:
Session A: turn1→ score=0,turn2→ score=0,turn3→ score=0Session B: turn1→ score=0,turn2→ score=0- → output_queue中全是loss_mask=[0]*T 的样本- → Slime收到rollout_batch_size个样本- → 前向传播正常,但 ∂L/∂θ ≈0(所有token都被mask掉)- → 实际上没有任何参数更新- → 占用了一次完整的 rollout+forwardpass+backwardpass,什么也没学
at-least-one 的修复:
# openclaw_api_server.pyifexclude and has_next_state and self._session_effective.get(session_id,0) ==0:exclude=False #强制 loss_mask=[1] # 但reward保持0.0!
注意:被promote的样本reward仍是0.0,所以advantage ≈ 0,梯度实际上接近 0。它解决的不是“学到有用信号”,而是确保:
output_queue 里每个 session 至少有一个非ABORTED 样本(Slime 的sample状态机要求)
防止Slime内部因为全 mask=0 的batch触发边界异常
根本原因:两种“零贡献“的本质不同。关键区别:Binary RL的零贡献样本会“占据“批次槽位但静默无效;OPD/Combine则完全不产生样本。
Binary RL的零贡献路径:
score=0 → exclude=True → loss_mask=[0]*T → 样本进入output_queue,但不产生梯度↑ 样本在批次中"占位",Slime看得到,但无梯度流动
OPD/Combine的零贡献路径:
hint被拒绝 &eval=0→ 样本根本不进入output_queue(直接丢弃)↑样本对Slime来说不存在
OPD 的信号结构:
| 情形 | 是否进入队列 | advantage |
|---|---|---|
| hint 接受 | √ | teacher_lp - rollout_lp ≠ 0(几乎必然) |
| hint 拒绝 | ×(丢弃) | N/A |
OPD 样本要么有真实的 per-token 教师信号(即使 reward=0, advantage 也非零),要么根本不进队列。没有“占位但无梯度"的中间状态。
Combine 的信号结构:
| 情形 | 进队列? | OPD 项 | RL 项 |
|---|---|---|---|
| OPD+RL | √ | ≠ 0 | ≠ 0 |
| OPD-only | √ | ≠ 0 | = 0 |
| RL-only | √ | = 0(数值对消) | ≠ 0 |
| 丢弃 | × | N/A | N/A |
进入队列的样本,至少一个信号项非零(这是 dispatch 逻辑保证的)。
设计选择的对称性
Binary RL的“批次污染"问题:存在 → at-least-one作为“最低保证“
OPD/Combine的等价保证:dispatch逻辑本身就确保“进队列=有信号“ → 问题从根源上消除,无需at-least-one
Binary RL的 at-least-one是在loss_mask二元门控机制下的补丁,而OPD/Combine 绕开了这个机制(始终 loss_mask=[1],通过 advantage 对消来“关掉“不需要的信号),所以补丁也就不再需要。
AsyncRolloutWorker = 线程边界 + 开关 + 数据渡口
AsyncRolloutWorker 是Slime(Policy Training)与 FastAPI Server(Policy Serving)之间的线程边界管理器,它不做推理、不做打分,但控制着Policy Serving的“营业时间",控制着两侧的生命周期和数据流转,并通过output_queue把FastAPI 异步世界里生产的样本,安全地传递给Slime同步训练世界。
具体功能如下:
启动和管理
API服务器管理
启动控制:负责启动和管理 OpenClawAPIServer 实例
生命周期管理:控制 API服务器的运行状态和资源分配
配置传递:向API服务器传递必要的运行时参数
样本队列管理
输出队列创建:创建queue.Queue()作为样本传输通道
队列监控:监控队列大小和样本积压情况
超时检测:实现30秒无进展警告机制
训练批次收集/协调
批次收集:等待足够数量的样本后触发训练
提交控制:管理样本提交的暂停/恢复机制
进度跟踪:显示收集的样本数量和耗时统计
提交控制(暂停/恢复)

Slime的主循环(训练)是同步代码
FastAPI需要异步事件循环
AsyncRolloutWorker 把FastAPI server 启动在独立线程中,两侧互不阻塞
#worker_thread_func跑在独立线程defworker_thread_func(self):asyncio.run(self.continuous_worker_loop()) # asyncio.run()创建独立事件循环 # FastAPI/httpx异步请求全在这个线程里
continuous_worker_loop()本身只是一个 sleep(1.0)的keepalive 循环—真正的数据生产在 FastAPI的 requesthandler 里,不是在这个loop里。
defpause_submission(self):self._submission_enabled.clear()#关闸 →FastAPI 返回 503 self._server.purge_record_files()#清理临时记录defresume_submission(self):self._submission_enabled.set()#开闸→FastAPI正常接受请求
threading.Event 是跨线程安全的信号量
Slime 主线程通过这个事件控制FastAPI线程的“营业状态“
weight sync 期间=paused=503;rollout 收集期间 =resumed=正常
queue.Queue是Python标准库中线程安全的FIFO,是FastAPI线程和 Slime 主线程之间唯一的共享数据结构。
#FastAPI 线程写入(async)awaitasyncio.to_thread(self.output_queue.put,(sample.group_index,[sample]))#Slime主线程读取(同步)defget_completed_groups(self)->list[tuple]:whileTrue:completed.append(self.output_queue.get_nowait())
AsyncRolloutWorker 是OpenClaw-RL框架中的异步轨迹收集工作者,负责管理整个 rollout数据收集流程的生命
OpenClawAPIServer:作为生产者,生成训练样本并放入队列
AsyncRolloutWorker:作为消费者管理者,提供队列并协调消费过程
Slime训练器:作为最终消费者,从队列中获取样本进行训练
AsyncRolloutWorker(顶层控制)↓ 创建并管理OpenClawAPIServer(数据生产)↓ 提交到SampleQueue(数据传输)↓ 消费于SlimeTrainer(模型训练)
队列创建:AsyncRolloutWorker 在初始化时创建self.output_queue =queue.Queue()
队列共享:将output_queue作为参数传递给OpenClawAPIServer
样本提交:OpenClawAPIServer 调用 self.output_queue.put((group_index,[sample]))
队列消费:Slime训练器通过rollout_worker.get_output_queue()获取队列并消费
提交开关:AsyncRolloutWorker 维护_submission_enabled 状态_
暂停信号:训练开始前调用pause_submission()禁用提交
恢复信号:权重更新后调用resume_submission()启用提交
API服务器响应:OpenClawAPIServer在提交前检查提交状态
记录清理:AsyncRolloutWorker 调用purge_record_files()清空记录文件
状态重置:确保新策略开始时的数据一致性
API服务器配合:OpenClawAPIServer响应清理请求并重置内部状态
AsyncRolloutWorker 初始化
创建输出队列:self.output_queue=queue.Queue()
设置提交状态:self.submit_enabled=True
初始化统计变量:样本计数、时间戳等
OpenClawAPIServer初始化
接收队列引l用:从AsyncRolloutWorker获取output_queue
初始化内部状态:_turn_counts,_pending_records 等字典
启动FaStAPI服务:准备接收用户请求
数据生产流程
用户请求到达:OpenClawAPIServer处理请求并生成样本
样本构建完成:调用_submit_turn_sample()创建Sample对象
队列提交:执行 self.output_queue.put((group_index,[sample]))
队列监控:AsyncRolloutWorker检测队列大小变化
批次收集流程
队列检查:AsyncRolloutWorker 定期检查output_queue.qsize()
批次判断:当队列大小达到值时准备训练批次
提交暂停:调用pause_submission()防止新样本干扰当前批次
批次提取:训练器从队列中提取完整批次
权重更新协调
训练开始:AsyncRolloutWorker暂停样本提交
记录清理:调用 OpenClawAPIServer 的 purge_record_files()
状态重置:清空所有待处理的回合记录和状态权重加载:新策略模型加载到 SGLang服务
恢复运行
提交恢复:AsyncRolloutWorker 调用resume_submission()
新会话开始:OpenClawAPIServer使用新策略处理后续请求
数据一致性:确保新旧策略数据不混合
正常对话流程
用户请求 → OpenClawAPIServer(生产样本) → output_queue → AsyncRolloutWorker (监控队列) → SlimeTrainer (消费训练)
权重更新流程
训练批次完成 → AsyncRolloutWorker.pause_submission() → purge_record_files() → 权重更新 →AsyncRolloutWorker.resume_submission() → 新策略生效
异常处理流程
unter(line队列积压警告 → AsyncRolloutWorker发出30秒超时警告 → 管理员介入或自动扩容 → 恢复正常处理
这种设计确保了OpenClaw-RL能够在保证用户体验的同时,高效地收集和处理强化学习训练数据,体现了解耦设计和异步处理的现代系统架构思想。
阅读原文