工业富联市值超越贵州茅台 A股风向变了
2026-06-22 3362802
2026-06-22 0
最近做知识库、合同归档、研发文档分析的团队越来越多,Claude 这类长上下文模型也经常被拿来做批量文档处理。我平时跟进模型和工具更新时,会参考工具整合站点库拉leadhi.cn 这类AI模型聚合平台,快速看不同模型、应用方案和接入方式。但真正落到工程里,大家最关心的不是“能不能读长文档”,而是“批量处理时延迟能不能压下来”。

所谓批量文档处理,常见场景包括:把几十份 PDF 转成结构化摘要、从多份接口文档里抽取字段、对历史会议纪要做归类、从项目资料中生成问答知识库。
Claude 的优势在于长上下文理解能力较稳,尤其适合处理篇幅长、结构不统一、语义关系复杂的资料。但如果直接把所有文档一股脑丢进去,延迟会明显上升,成本也不容易控制。
延迟压缩的核心,不是单纯“让模型快一点”,而是减少无效输入、降低重复推理、优化任务拆分。
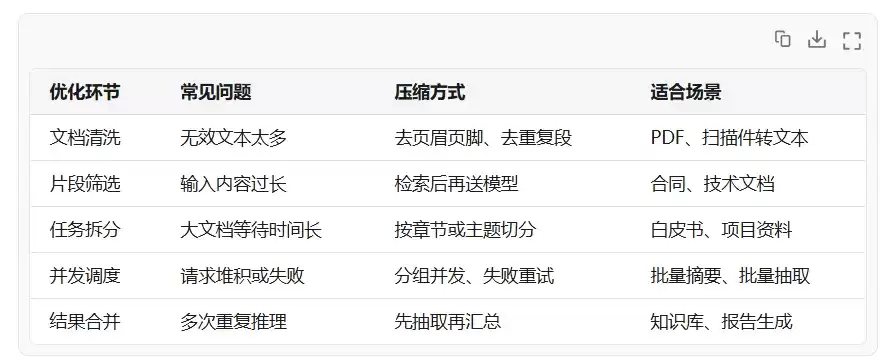
可以把整个流程拆成四层:文档预处理、片段筛选、批量调度、结果合并。
第一步是文档预处理。不要把原始文档直接交给模型。实际项目里,PDF 页眉页脚、目录、版权说明、重复表格会占用大量上下文。先做清洗,把无效内容去掉,再保留标题、正文、表格说明和关键字段。
第二步是片段筛选。Claude 可以吃长文本,但不代表每次都应该喂满。比如用户只想提取“付款条款”,就没必要把全文都送进去。更好的方式是先用关键词、向量检索或规则匹配找候选片段,再让 Claude 做语义判断和总结。
第三步是批量调度。批量任务不要全部串行,也不要无限并发。串行太慢,并发过高又容易带来失败重试。比较稳的做法是按文档大小分组,小文档合批,大文档拆段,并设置重试和超时策略。
第四步是结果合并。很多延迟浪费发生在重复总结上。比如 30 份文档都要抽取“项目背景、风险点、关键时间”,可以先单文档抽取,再做一次总表合并,而不是每次都让模型重新理解全部资料。
这里有一个容易忽略的点:延迟压缩不能只看单次请求耗时,还要看端到端耗时。
比如单个请求从 20 秒降到 12 秒,看起来不错。但如果因为拆分太细,产生了 50 次请求,整体时间反而更长。所以工程上要平衡“上下文长度”和“请求数量”。
我的经验是,Claude 更适合承担后半段的语义理解任务,而不是前半段的粗筛任务。前面可以用规则、搜索、embedding 或轻量模型做召回,后面再让 Claude 做判断、归纳和结构化输出。
一个比较实用的流程是:
先将文档解析为 Markdown 或纯文本,再按标题层级切分。每个片段保留文档名、章节名和页码。然后用检索方式找出相关片段,交给 Claude 输出 JSON 结构。最后由程序合并结果,生成表格、摘要或问答条目。
提示词也会影响延迟。很多人喜欢写很长的要求,其实会增加模型理解负担。批量任务的提示词应尽量稳定、短句化、字段化。例如:“只基于输入内容回答;缺失字段填 null;不要补充未出现的信息;输出 JSON。”
这样做的好处是结果更容易解析,也更适合自动化流水线。
从趋势看,长上下文模型正在从“单次大输入”转向“检索增强 + 分层处理”。未来批量文档处理不会只依赖某一个模型,而是由解析器、检索模块、调度系统和大模型共同完成。
结论很简单:Claude 的长文档理解能力适合做高质量抽取和总结,但要想在批量场景里降低延迟,关键是把无效内容挡在模型之外,把重复推理压到最少。真正好用的方案,不是让模型一次读完所有东西,而是让它只处理最值得处理的部分。