谷歌推出首款Gemini智能音箱:6月25日正式发售
2026-06-25 3367165
2026-06-25 0

欢迎关注Python机器学习AI
本节介绍:分区间置信椭圆散点图比较不同回归模型的预测表现,数据采用模拟数据无任何现实意义,作者根据个人对机器学习的理解进行代码实现与图表输出,仅供参考。 完整数据和代码稍后上传至网站。需要的朋友可关注公众文末提供的获取方式。后台 提供 高效AI工具~!
相关信息
文献配图的重点不是单纯把训练集和测试集分别画出来,而是进一步把最优模型与其它候选模型放在同一数据集和同一坐标体系下进行横向比较。常规回归散点图通常一个画布上同时展示训练集、测试集中预测值与实验值的对应关系,点越接近对角线说明预测越准确——期刊配图:一套代码搞定回归模型性能对比可视化(附代码 );而该图在此基础上,将RF、XGBoost、CatBoost等模型分别与GP-BT进行对比,并通过置信椭圆刻画特定区间内散点的分布范围、集中程度和偏差方向。椭圆越小、越贴近对角线,说明该模型在该区间内预测越稳定、误差越小;椭圆偏离对角线则提示可能存在系统性高估或低估。因此,这种画法不仅能展示整体拟合效果,还能揭示不同模型在局部预测区间内的误差结构和稳定性差异。右侧的真实样本散点图与 RMSE、MAE 柱状图进一步补充了模型在外部数据上的泛化表现
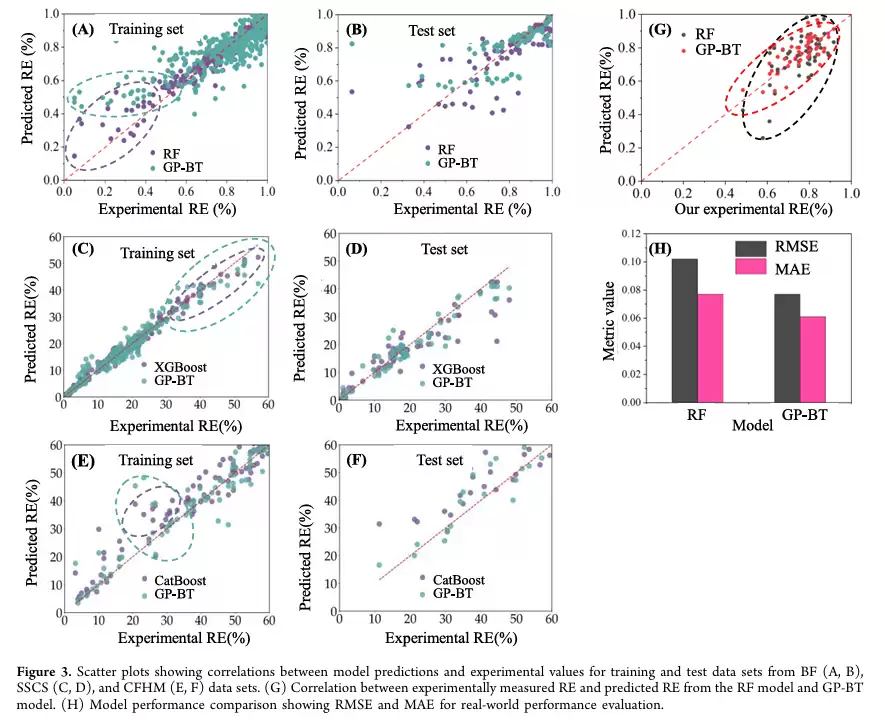
该图是基于模拟数据实现的回归模型对比可视化,用于演示如何在同一测试集上同时展示RF与GP-BT的预测散点、分区间置信椭圆以及整体拟合优度从图中可以看出,散点越接近灰色虚线y=x,说明预测值越接近真实值;RF的测试集拟合优度高于GP-BT,说明在整体测试集上RF的拟合效果更好。进一步观察置信椭圆,RF的紫色椭圆较大且覆盖低值到中值区间,说明该区间内预测结果波动较大,但整体趋势仍较好;GP-BT的青绿色椭圆更扁、更集中,表示其局部预测稳定性较强,但椭圆整体位于y=x上方,说明在该区间存在一定高估倾向
基础代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Times New Roman'
plt.rcParams['axes.unicode_minus'] = False
import warnings
# 忽略所有警告
warnings.filterwarnings("ignore")
path = r"2026-6-11公众号Python机器学习AI.xlsx"
df = pd.read_excel(path)
from sklearn.model_selection import train_test_split
target = 'SR'
X = df.drop(columns=[target])
y = df[target]
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=42
)
from xgboost import XGBRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import GridSearchCV, KFold
# K折交叉验证
kfold = KFold(
n_splits=5,
shuffle=True,
random_state=42
)
xgb_model = XGBRegressor(
random_state=42,
objective="reg:squarederror"
)
xgb_param_grid = {
"n_estimators": [100, 200, 300],
"max_depth": [2, 3, 4, 5],
"learning_rate": [0.01, 0.05, 0.1],
"subsample": [0.8, 1.0],
"colsample_bytree": [0.8, 1.0]
}
xgb_grid = GridSearchCV(
estimator=xgb_model,
param_grid=xgb_param_grid,
scoring="r2",
cv=kfold,
n_jobs=-1,
verbose=1
)
xgb_grid.fit(X_train, y_train)
best_xgb_model = xgb_grid.best_estimator_
print("Best XGBoost parameters:")
print(xgb_grid.best_params_)
print("Best XGBoost CV R2:", xgb_grid.best_score_)
dt_model = DecisionTreeRegressor(
random_state=42
)
dt_param_grid = {
"max_depth": [2, 3, 4, 5, 6, None],
"min_samples_split": [2, 5, 10],
"min_samples_leaf": [1, 2, 4, 8],
"criterion": ["squared_error", "friedman_mse"]
}
dt_grid = GridSearchCV(
estimator=dt_model,
param_grid=dt_param_grid,
scoring="r2",
cv=kfold,
n_jobs=-1,
verbose=1
)
dt_grid.fit(X_train, y_train)
best_dt_model = dt_grid.best_estimator_
print("Best Decision Tree parameters:")
print(dt_grid.best_params_)
print("Best Decision Tree CV R2:", dt_grid.best_score_)
y_pred_xgb = best_xgb_model.predict(X_test)
y_pred_dt = best_dt_model.predict(X_test)
Fitting 5 folds for each of 144 candidates, totalling 720 fits
Best XGBoost parameters:
{'colsample_bytree': 1.0, 'learning_rate': 0.05, 'max_depth': 3, 'n_estimators': 100, 'subsample': 0.8}
Best XGBoost CV R2: 0.8760164066661537
Fitting 5 folds for each of 144 candidates, totalling 720 fits
Best Decision Tree parameters:
{'criterion': 'squared_error', 'max_depth': 5, 'min_samples_leaf': 8, 'min_samples_split': 2}
Best Decision Tree CV R2: 0.8413786537234579
读取数据,确定目标变量划分训练集和测试集,并分别使用5折交叉验证网格搜索优化XGBoost和决策树回归模型,最后得到两个最优模型在测试集上的预测结果
plot_scatter_with_range_confidence_ellipse(
y_test,
y_pred_xgb,
y_pred_dt,
base_name="XGBoost",
gp_name="DT",
base_ellipse_range=(0, 50), # 第一个模型椭圆使用这个区间
gp_ellipse_range=(20, 70), # 第二个模型椭圆使用这个区间
legend_loc="upper left",
save_path="scatter_1.pdf"
)
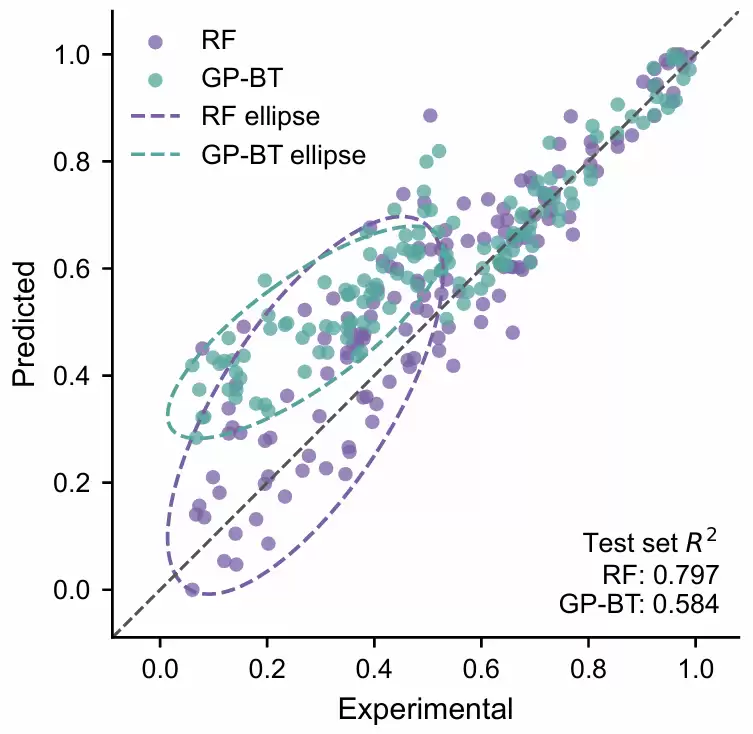
将测试集真实值与XGBoost、DT两个模型的预测值绘制在同一回归散点图中,并分别在指定区间 (0, 50) 和 (20, 70) 上添加置信椭圆,用于直观比较两个模型在不同真实值区间内的预测分布、稳定性和偏差情况
plot_scatter_with_range_confidence_ellipse(
y_test,
y_pred_xgb,
y_pred_dt,
base_name="XGBoost",
gp_name="DT",
base_ellipse_range=(5, 50),
gp_ellipse_range=(50, 100),
base_scatter_color="#9ECAE1", # XGBoost 散点:浅蓝
gp_scatter_color="#FDBE85", # Decision Tree 散点:浅橙
base_ellipse_color="#3182BD", # XGBoost 椭圆:深蓝
gp_ellipse_color="#E6550D", # Decision Tree 椭圆:深橙
legend_loc="upper left",
save_path="scatter_2.pdf"
)
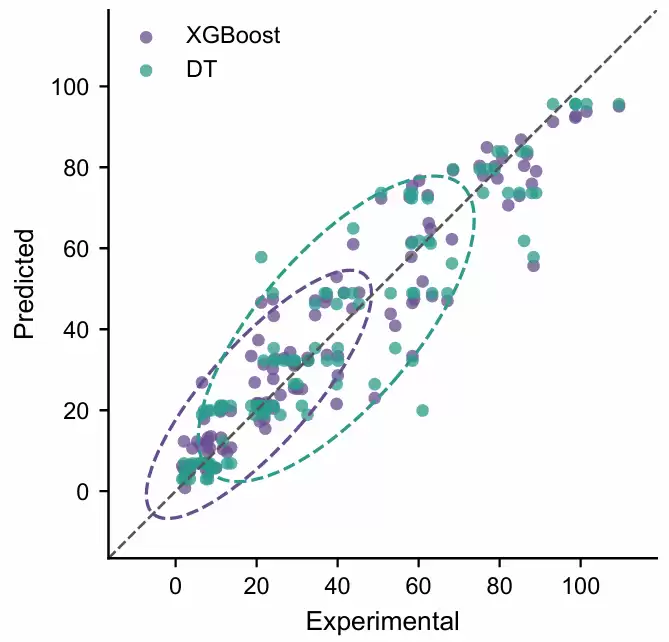
在前一版回归散点图的基础上,进一步将两个模型的置信椭圆区间设置为不同范围,并分别为散点和椭圆单独指定同色系但深浅不同的配色,避免默认“散点与椭圆同色”时区分不明显,从而更清晰地比较XGBoost与DT在不同真实值区间内的预测分布和偏差
plot_scatter_with_range_confidence_ellipse(
y_test,
y_pred_xgb,
y_pred_dt,
base_ellipse_range=(5, 50),
gp_ellipse_range=(50, 100),
base_name="XGBoost",
gp_name="DT",
base_scatter_color="#9ECAE1",
gp_scatter_color="#FDBE85",
base_ellipse_color="#3182BD",
gp_ellipse_color="#E6550D",
legend_loc="upper left",
show_test_r2=True,
save_path="scatter_3.pdf"
)
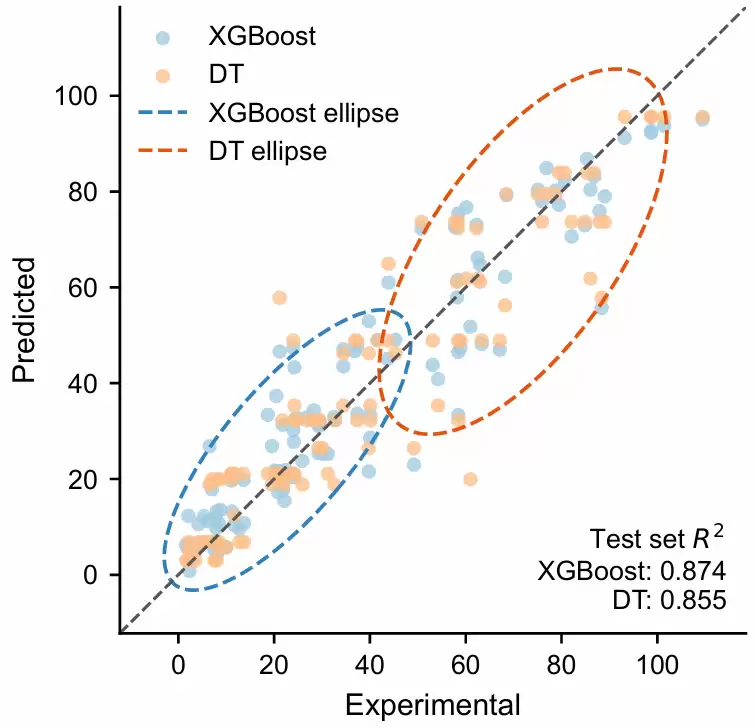
新增show_test_r2=True,作用是在图的右下角自动显示两个模型在测试集上的拟合优度,使散点分布、分区间置信椭圆和整体量化指标能够同时呈现,从而更直观地比较XGBoost与DT的整体预测性能和局部区间误差特征, 具体函数参数可参考网站上传的项目压缩包中的完整代码,读者可根据自己的数据范围、模型名称、配色方案、椭圆区间及是否显示测试集R2等实际需求进行灵活调整
np.random.seed(42)
n_samples = 140
x_low = np.random.uniform(0.05, 0.55, 55)
x_mid = np.random.uniform(0.35, 0.75, 45)
x_high = np.random.uniform(0.60, 1.00, 40)
y_test_demo = np.concatenate([x_low, x_mid, x_high])
y_test_demo = np.sort(y_test_demo)
y_pred_rf_demo = (
0.08
+ 0.95 * y_test_demo
+ np.random.normal(0, 0.12, size=len(y_test_demo))
)
high_mask = y_test_demo > 0.60
y_pred_rf_demo[high_mask] = (
y_test_demo[high_mask]
+ np.random.normal(0, 0.055, size=high_mask.sum())
)
y_pred_gpbt_demo = (
0.28
+ 0.72 * y_test_demo
+ np.random.normal(0, 0.075, size=len(y_test_demo))
)
mid_high_mask = y_test_demo > 0.55
y_pred_gpbt_demo[mid_high_mask] = (
y_test_demo[mid_high_mask]
+ np.random.normal(0, 0.035, size=mid_high_mask.sum())
)
# 限制在 0-1 范围内
y_pred_rf_demo = np.clip(y_pred_rf_demo, 0, 1)
y_pred_gpbt_demo = np.clip(y_pred_gpbt_demo, 0, 1)
plot_scatter_with_range_confidence_ellipse(
y_test_demo,
y_pred_rf_demo,
y_pred_gpbt_demo,
base_ellipse_range=(0.05, 0.45), # RF 椭圆:低值区间
gp_ellipse_range=(0.05, 0.45), # GP-BT 椭圆:中低值区间
base_name="RF",
gp_name="GP-BT",
base_scatter_color="#7B5EA7", # RF 紫色散点
gp_scatter_color="#55A6A0", # GP-BT 青绿色散点
base_ellipse_color="#7B5EA7", # RF 紫色椭圆
gp_ellipse_color="#55A6A0", # GP-BT 青绿色椭圆
legend_loc="upper left",
show_test_r2=True,
save_path="demo_model_comparison.pdf"
)
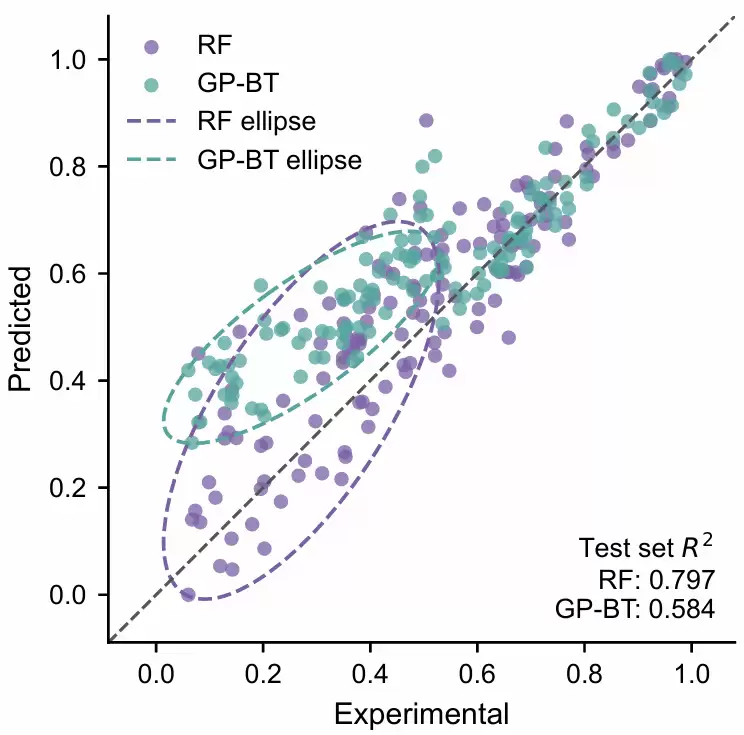
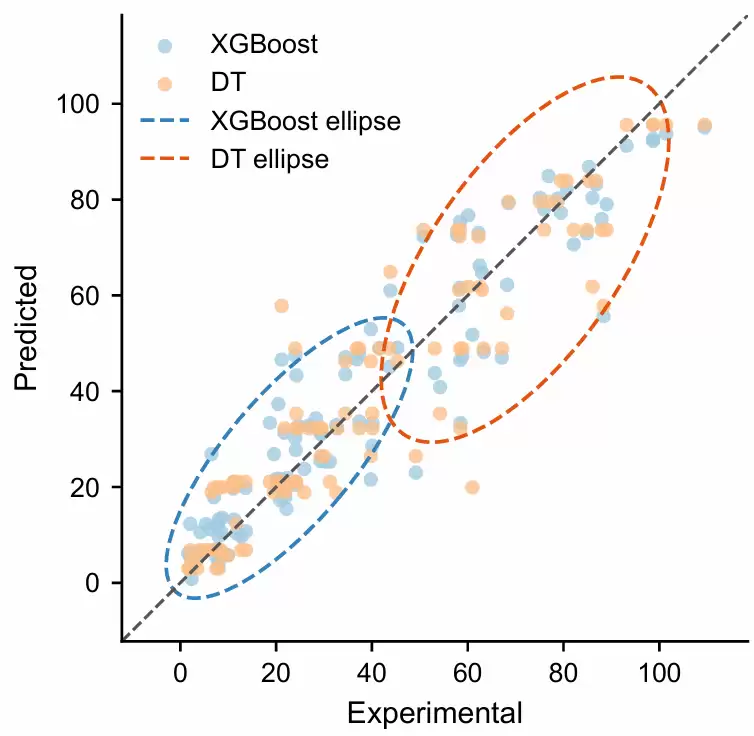
构造一组差异更明显的模拟真实值和两个模型预测值,调用前面定义的置信椭圆回归散点图函数进行可视化;由于实际建模结果中不同模型性能可能接近、椭圆差异不够直观,因此该模拟案例通过人为设置不同误差结构,让RF与GP-BT在局部区间内的预测稳定性、偏差方向和整体拟合优度差异更加清晰可见,展示这个可视化的具体作用
当然,公众号中还有更多机器学习期刊实战技巧,您可以通过历史文章进行检索和阅读,关注公众号,点击“发信息”>“历史文章”即可搜索公众号所有文章信息
该文章案例
在上传的文件中,像往期文章一样,将对案例进行逐步分析,确保读者能够达到最佳的学习效果。内容都经过详细解读,帮助读者深入理解模型的实现过程和数据分析步骤,从而最大化学习成果。
同时,结合提供的免费AI网站进行学习,能够让读者在理论与实践之间实现融会贯通,更加全面地掌握核心概念。
介绍
本节内容到此结束。若需要获取本案例的源码及相关资料,可通过公众号后台私信按钮“ 源码获取 ”了解店铺相关信息。资料中包含代码、注释、数据说明及参考文献,便于读者进一步学习和复现。合集目前包含近400篇资料。更多内容等你探索~~
更新的内容包含数据、代码、注释和参考资料。 作者仅分享案例项目,不提供额外的答疑服务。项目中将提供详细的代码注释和丰富的解读,帮助您理解每个步骤 。 获取 前请咨询,避免不必要的问题。
淘宝店铺

请大家打开淘宝,进入“Python机器学习AI”,获取更多Python机器学习和AI相关的内容 ,希望能为您的学习之路提供帮助!
反馈

如果你对类似于这样的文章感兴趣。
欢迎关注、点赞、转发~
个人观点,仅供参考