文档转Markdown-HTML转markdown-docx转markdown API接口介绍
2026-06-26 3368437
2026-06-26 0
向量搜索、图遍历还是网络搜索 -- 本文介绍如何用 LangGraph 让智能体为每个问题选择合适的工具。
语义搜索、向量数据库迁移、Graph RAG。这些系统有一个共同缺陷——都是 Pipeline,固定执行序列,问题进、答案出,不论输入是什么。
真实问题并不符合这个假设。
"我们的退款政策是什么?" 需要向量搜索。
"顶级客户和这家供应商之间有什么关联?" 需要图遍历。
"美联储今早宣布了什么?" 需要网络搜索。
Pipeline 只能处理其中一种。Agent 三种都能做,而且能自己决定用哪种。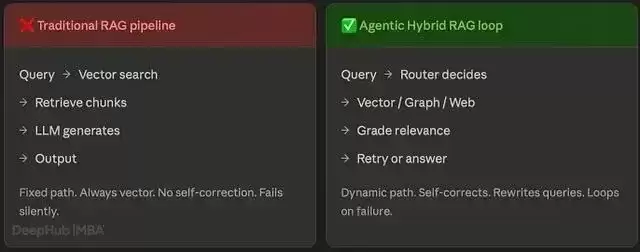
思维转变:传统 RAG 是一个函数——输入 → 输出。Agentic RAG 是一个状态机——它有记忆、能做决策、可以回溯,只有在对答案有把握时才会终止。
Agent 与 Pipeline 的区别体现在四种能力上: 路由实际效果演示:
路由实际效果演示:
"公司的数据留存政策是什么?"——Vector(向量搜索)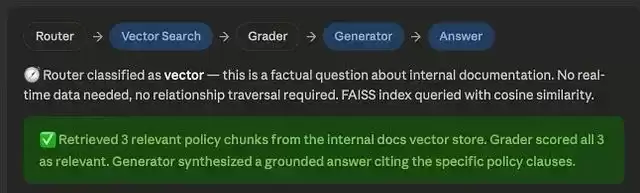 "排名前 3 的客户与哪些供应商有关联?"——Graph(图搜索)
"排名前 3 的客户与哪些供应商有关联?"——Graph(图搜索)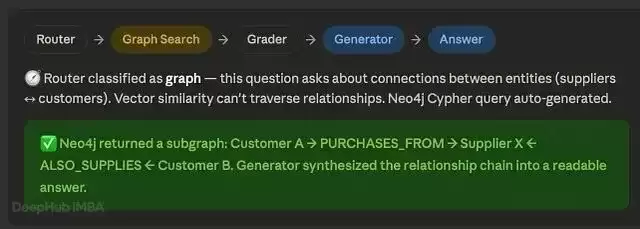 "美联储今天关于利率的最新公告是什么?"——Web(网络搜索)
"美联储今天关于利率的最新公告是什么?"——Web(网络搜索)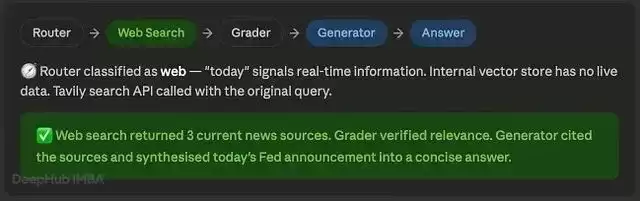 "340 的 15% 是多少?"——DirectLLM(直接调用 LLM)
"340 的 15% 是多少?"——DirectLLM(直接调用 LLM)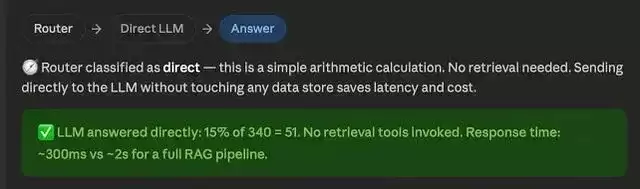
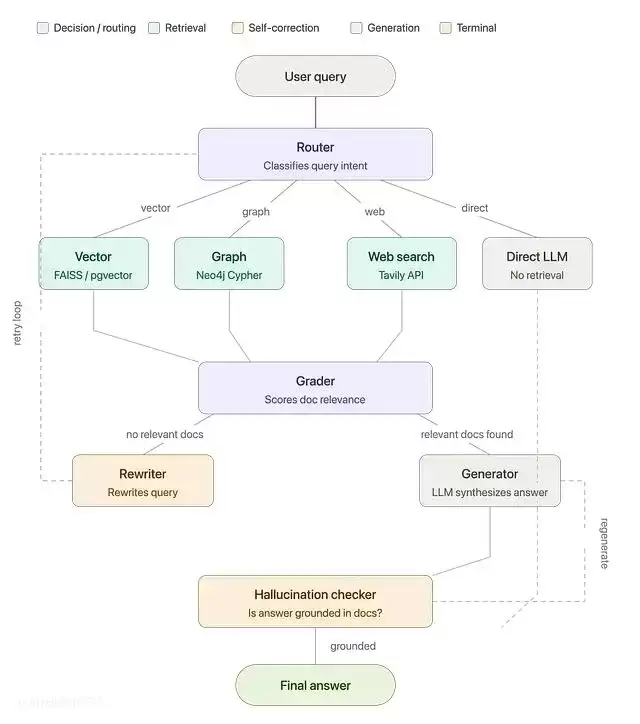
LangGraph 将 Agent 建模为有向图,节点是函数,边是决策。与 LangChain 的关键差异在于:边可以形成循环。Agent 能不断重试、改写、自我纠错,直到生成一个有把握的答案。
Router:入口节点
Router 是 Agent 的决策中枢。它接收原始查询通过结构化 LLM 调用(
with_structured_output
)将其分为四类:vector、graph、web 或 direct。分类结果在 LangGraph 中成为一条条件边,决定接下来运行哪个检索节点。每次查询、每次改写后都会经过 Router。
Retriever:Vector / Graph / Web
三个检索节点占各自槽位:Vector(FAISS/pgvector 余弦相似度)、Graph(Neo4j 自动生成 Cypher)、Web(Tavily API)。每个节点返回一组 Document 对象,路由决策决定哪个节点被激活。在改写循环中,Router 可能切换到不同的检索器。
Grader:相关性评估
Grader 逐一评估每个检索到的文档:相关或不相关,每份文档各触发一次结构化 LLM 调用。判断逻辑如下:至少 1 个文档相关 → 路由至 Generator;全部不相关且
rewrite_count < 3
→ 路由至 Rewriter;全部不相关且已改写 3 次 → 路由至 web 兜底。这是整个自我纠错机制的核心。
Rewriter:检索失败时的查询修复
检索失败后 Rewriter 启动,接收原始查询(或之前的改写版本),要求 LLM 重新表述——更具体的词语、不同的同义词、更清晰的范围。每次改写后
rewrite_count
递增,上限 3 次,防止无限循环。改写完成后重新路由回 Router。
Generator:LLM 生成答案
Generator 只接收被评为相关的文档,用严格的 Prompt 综合生成有依据的答案:"仅根据以下上下文作答。"答案和来源文档存入 Agent 状态,供后续幻觉检测使用,不相关的文档完全隔离在外。
Hallucination Checker:最终验证
Hallucination Checker 拿到生成的答案和来源文档,判断"答案中的每一个论断是否都有上下文支撑"。如果是 → 返回答案(END);如果否 → 以更严格的 Prompt 路由回 Generator 重新生成。这个节点专门拦截那些表面自信、实则错误的输出。
 Router 节点:对查询进行分类
Router 节点:对查询进行分类
LLM 将输入问题分类为四类之一:
vector_search
(文档事实查询)、
graph_search
(关系查询)、
web_search
(实时信息)或
direct
(LLM 已知的内容)。这是 LangGraph 中的条件边,输出结果决定下一个运行的节点。
Retriever 节点:执行对应工具
三个工具作为 LangGraph 节点接入:FAISS/pgvector 用于语义相似度,Neo4j Cypher 用于图遍历,Tavily/SerpAPI 用于实时网络结果。每个节点返回带有相关性元数据的文档列表。
Grader 节点:文档是否真正相关?
LLM 对每个检索到的文档打分:相关或不相关。若所有文档均不通过,边路由至 Rewriter;若足够多的文档通过,则路由至 Generator。
Rewriter 节点:修复查询,重新尝试
检索失败时,LLM 将原始查询改写得更具体,或切换检索策略,然后循环回第 2 步。最多重试 3 次,之后回退到网络搜索。
Generator 节点:综合生成答案
LLM 基于检索到的文档生成有依据的答案,答案和来源文档存入 Agent 状态,供幻觉检测使用。
Hallucination Checker:最终关卡
LLM 验证:答案中的每个论断是否都有检索文档支撑?如果是 → 返回答案;如果否 → 以更严格的 Prompt 循环回 Generator。这一机制消除了"自信却错误"的答案。
第 1 步——定义 Agent 状态
from typing import TypedDict, List, Literal
from langchain_core.documents import Document
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.graphs import Neo4jGraph
from pydantic import BaseModel
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# ── Agent 状态——在所有节点间持久保存 ────────────
class AgentState(TypedDict): question: str route: str # vector | graph | web | direct documents:List[Document] generation: str rewrite_count: int grade_results: List[str]
# ── 工具初始化 ──────────────────────────────────────────────
embeddings = OpenAIEmbeddings()
vector_store = FAISS.load_local("faiss_index", embeddings)
vector_retriever = vector_store.as_retriever(search_kwargs={"k": 4})
neo4j_graph = Neo4jGraph(url="bolt://localhost:7687", username="neo4j", password="password")
web_search = TavilySearchResults(max_results=3)
第 2 步——Router 节点
class RouteDecision(BaseModel): route: Literal["vector", "graph", "web", "direct"] reasoning: str
router_llm = llm.with_structured_output(RouteDecision)
ROUTER_PROMPT = """You are a query router for a hybrid RAG system.
Classify the query into ONE category:
- vector: factual questions answerable from internal documents (policies, reports, product info, static knowledge)
- graph: questions about relationships between entities (how X connects to Y, who knows whom, supplier chains)
- web: requires real-time or current information (news, stock prices, today's events, recent releases)
- direct: simple calculations or general knowledge the LLM already knows
Query: {question}"""
def router_node(state: AgentState) -> AgentState: decision = router_llm.invoke(
ROUTER_PROMPT.format(question=state["question"]) ) print(f"→ Router: {decision.route} | {decision.reasoning}") return {**state, "route": decision.route}
# 条件边——路由到对应的检索节点
def route_edge(state: AgentState) -> str: return state["route"] # "vector" | "graph" | "web" | "direct"
第 3 步——三个 Retriever 节点
# ── Vector 检索器 ────────────────────────────────────
def vector_node(state: AgentState) -> AgentState: docs = vector_retriever.invoke(state["question"]) return {**state, "documents": docs}
# ── Graph 检索器(Neo4j,LLM 自动生成 Cypher)──────────────
from langchain.chains import GraphCypherQAChain
graph_chain = GraphCypherQAChain.from_llm( llm=llm, graph=neo4j_graph, verbose=True, allow_dangerous_requests=True
)
def graph_node(state: AgentState) -> AgentState: result = graph_chain.invoke(state["question"]) doc = Document(page_content=result["result"], metadata={"source": "neo4j_graph"}) return {**state, "documents": [doc]}
# ── Web 搜索检索器 ─────────────────────────────────
def web_node(state: AgentState) -> AgentState: results = web_search.invoke(state["question"]) docs = [Document(page_content=r["content"], metadata={"source": r["url"]}) for r in results] return {**state, "documents": docs}
# ── 直接调用 LLM(无需检索)────────────────────────────────
def direct_node(state: AgentState) -> AgentState: answer = llm.invoke(state["question"]).content return {**state, "generation": answer, "documents": []}
第 4 步——Grader、Rewriter、Generator 和 Hallucination Checker
# ── Grader ───────────────────────────────────────────────
class GradeDoc(BaseModel): score: Literal["relevant", "irrelevant"]
grader_llm = llm.with_structured_output(GradeDoc)
def grader_node(state: AgentState) -> AgentState: grades = [] for doc in state["documents"]:
result = grader_llm.invoke( f"Question: {state['question']}nDocument: {doc.page_content[:400]}n" "Is this document relevant to answering the question? Score: relevant/irrelevant"
)
grades.append(result.score) return {**state, "grade_results": grades}
def grade_edge(state: AgentState) -> str: relevant = sum(1 for g in state["grade_results"] if g == "relevant") if relevant > 0:
return "generate" elif state["rewrite_count"] < 3:
return "rewrite" else:
return "web_fallback" # 三次失败后的最终兜底
# ── Rewriter ─────────────────────────────────────────────
def rewriter_node(state: AgentState) -> AgentState: rewritten = llm.invoke(
f"The query '{state['question']}' returned no relevant results. "
"Rewrite it to be more specific and searchable. Return only the rewritten query." ).content print(f"→ Rewriter: '{state['question']}' → '{rewritten}'") return {**state, "question": rewritten, "rewrite_count": state["rewrite_count"] + 1}
# ── Generator ────────────────────────────────────────────
def generator_node(state: AgentState) -> AgentState: context = "nn".join(d.page_content for d in state["documents"] if "relevant" in state.get("grade_results",[])) answer = llm.invoke(
f"Answer using only the context below.nnContext:n{context}nnQuestion: {state['question']}" ).content return {**state, "generation": answer}
# ── Hallucination Checker ────────────────────────────────
class HallucinationCheck(BaseModel): grounded: Literal["yes", "no"]
halluc_llm = llm.with_structured_output(HallucinationCheck)
def hallucination_node(state: AgentState) -> AgentState: context = "nn".join(d.page_content for d in state["documents"]) result = halluc_llm.invoke(
f"Context:n{context}nnAnswer:n{state['generation']}nn"
"Is the answer fully supported by the context? grounded: yes/no" ) return {**state, "hallucination_check": result.grounded}
def halluc_edge(state: AgentState) -> str: return "end" if state.get("hallucination_check") == "yes" else "regenerate"
第 5 步——连接图结构并运行
# ── 构建 LangGraph 状态机 ────────────────────────────────
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("router", router_node)
workflow.add_node("vector", vector_node)
workflow.add_node("graph",graph_node)
workflow.add_node("web", web_node)
workflow.add_node("direct", direct_node)
workflow.add_node("grader", grader_node)
workflow.add_node("rewriter", rewriter_node)
workflow.add_node("generator", generator_node)
workflow.add_node("hallucination",hallucination_node)
# 入口节点
workflow.set_entry_point("router")
# router → 检索器(条件边)
workflow.add_conditional_edges("router", route_edge, { "vector": "vector", "graph": "graph", "web": "web", "direct": "direct",
})
# 检索器 → grader
for node in ["vector", "graph", "web"]: workflow.add_edge(node, "grader")
# grader → 生成 / 改写 / web 兜底
workflow.add_conditional_edges("grader", grade_edge, { "generate": "generator", "rewrite":"rewriter", "web_fallback": "web",
})
# rewriter → 回到 router
workflow.add_edge("rewriter", "router")
# generator → hallucination 检测
workflow.add_edge("generator", "hallucination")
# hallucination 检测 → 结束或重新生成
workflow.add_conditional_edges("hallucination", halluc_edge, { "end":END, "regenerate": "generator",
})
workflow.add_edge("direct", END)
# 编译并运行
agent = workflow.compile()
result = agent.invoke({ "question":"What is our data retention policy for EU customers?", "rewrite_count": 0, "documents": [], "grade_results": [], "generation": "", "route": "",
})
print(result["generation"])
通过引入 LangGraph 构建状态机,我们将传统的“单向直通车”式 RAG 成功升级为了具备记忆、决策和自我纠错能力的智能体系统。这种混合 Agent 架构彻底打破了单一 Pipeline 的局限:它不仅能通过 Router 扮演决策中枢,针对不同问题智能分发最匹配的检索工具(向量相似度、图谱关联、网络实时数据或直接调用大模型);更重要的是,它建立了一套严密的自校验闭环。
借助 Grader 的相关性过滤和 Rewriter 的查询修复,系统在面对检索失败时可以主动寻找替代方案;而最后的 Hallucination Checker 拦截一切缺乏上下文支撑的“自信妄想”。这种架构让 AI 像人一样,在不确定中不断试错、交叉验证,直到确信无疑才交付结果。
https://avoid.overfit.cn/post/6f3ab183695548b3bef0e96109eaa37fBy Sivasundharam