AI 智能体项目费用
2026-06-27 3369958
2026-06-27 0
GLM 5.2作为开源大模型中的高性能代表,凭借7440亿总参数、400亿激活参数与100万tokens上下文窗口,在长文本推理、智能体任务与复杂代码生成场景表现突出。其MIT开源协议支持完全自托管,可实现数据隐私可控、成本灵活优化,但超大参数量带来极高硬件门槛,需根据量化版本匹配对应硬件,并选择vLLM、SGLang等推理框架搭建服务。本文从硬件选型、vLLM与SGLang部署、成本盈亏测算三大核心维度,提供零门槛自托管全流程实战指南,覆盖企业生产与个人调试场景,帮助精准落地与成本控制。
GLM 5.2提供BF16、FP8、Q4_K_M GGUF、UD-IQ2四种量化版本,磁盘占用与硬件要求差异显著,需根据场景选择适配方案,避免显存溢出或性能浪费。阿里云部署AI Agent:OpenClaw/Hermes Agent全网最简单,只需两步,详情访问阿里云OpenClaw/Hermes一键部署专题页面 了解。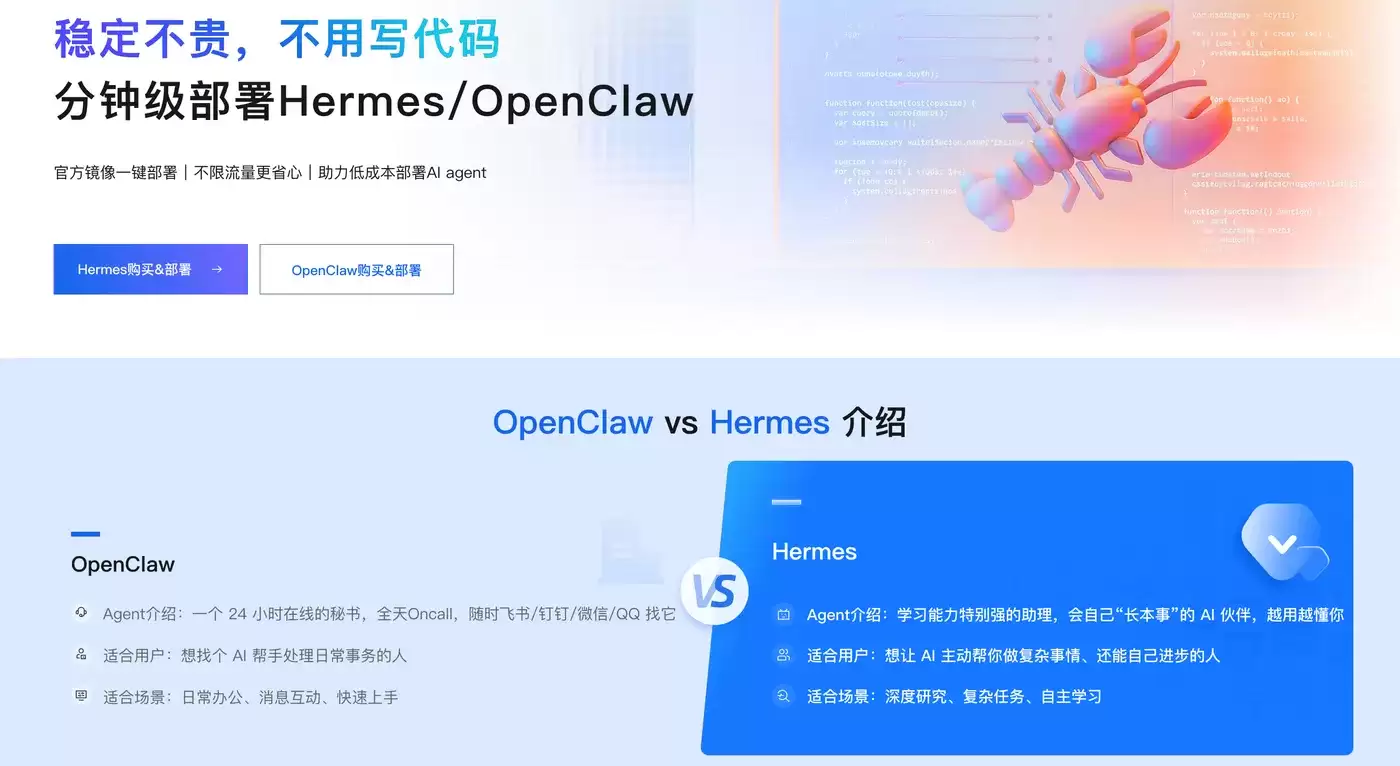


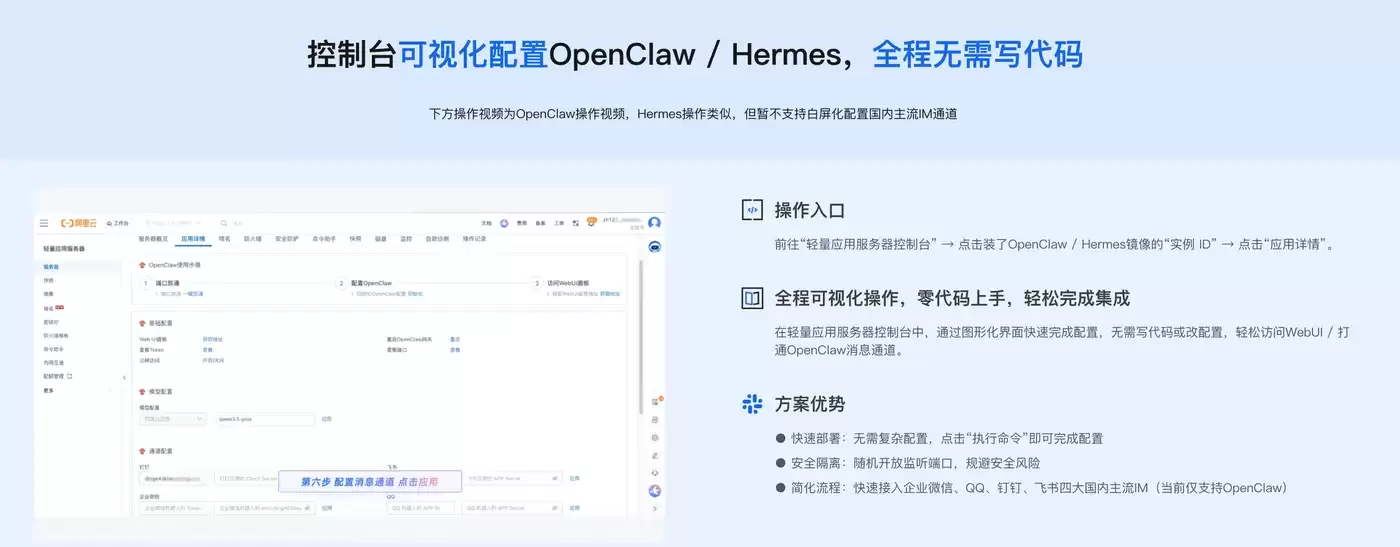
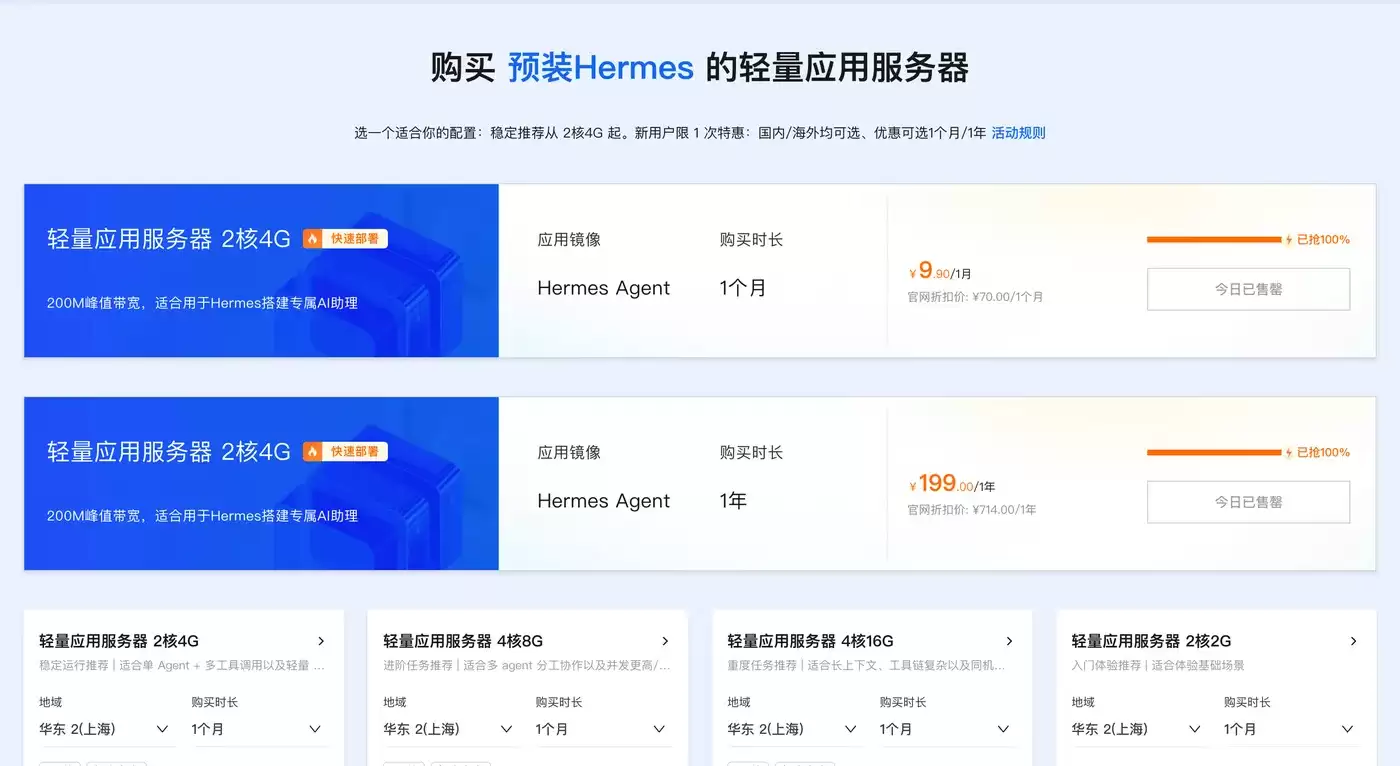
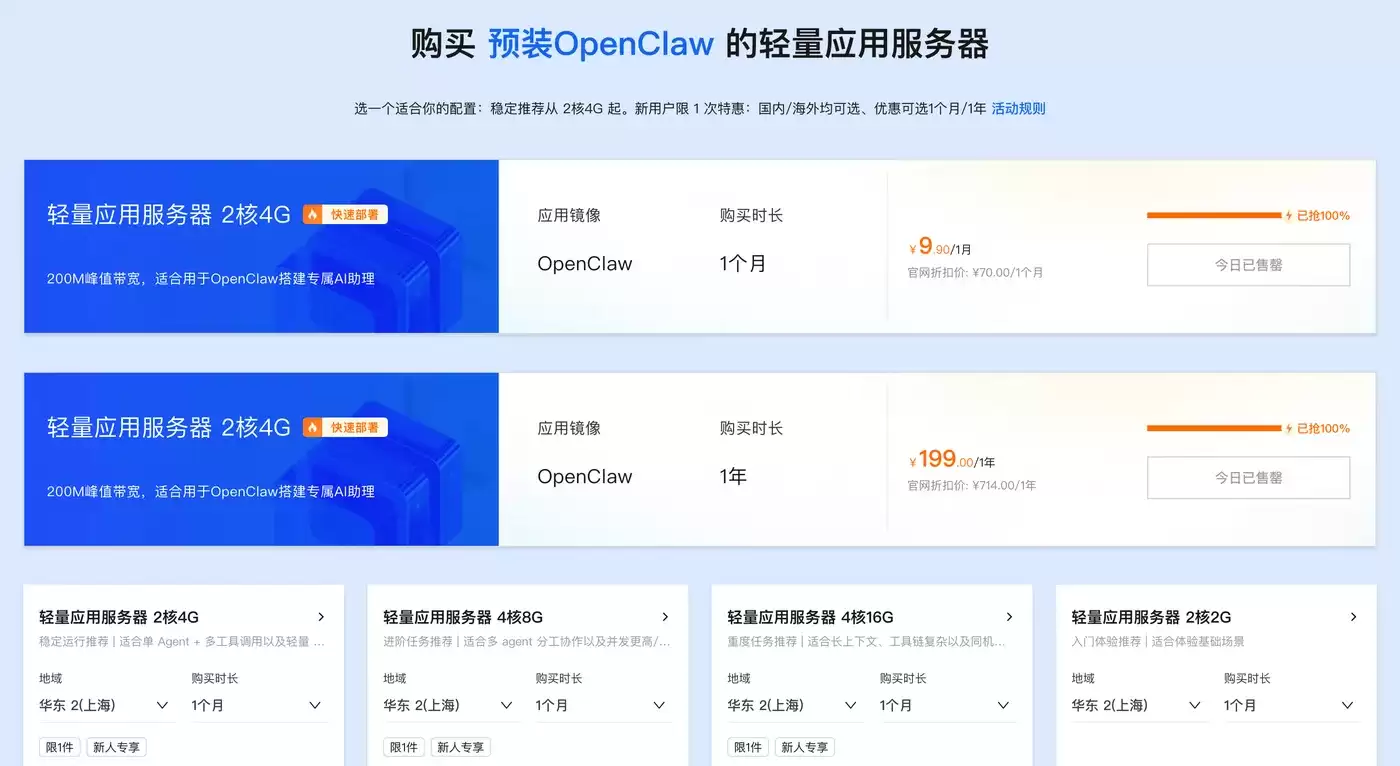
 Token Plan Token最便宜/支持多模型切换:访问订阅阿里云百炼Token Plan AI大模型服务 。支持多模型切换,用于多模态模型灵活调用,实现多模型、多工具、多场景下的额度共享与统一管理,兼顾灵活性、稳定性与安全性,大幅降低企业使用大模型的门槛与成本。
Token Plan Token最便宜/支持多模型切换:访问订阅阿里云百炼Token Plan AI大模型服务 。支持多模型切换,用于多模态模型灵活调用,实现多模型、多工具、多场景下的额度共享与统一管理,兼顾灵活性、稳定性与安全性,大幅降低企业使用大模型的门槛与成本。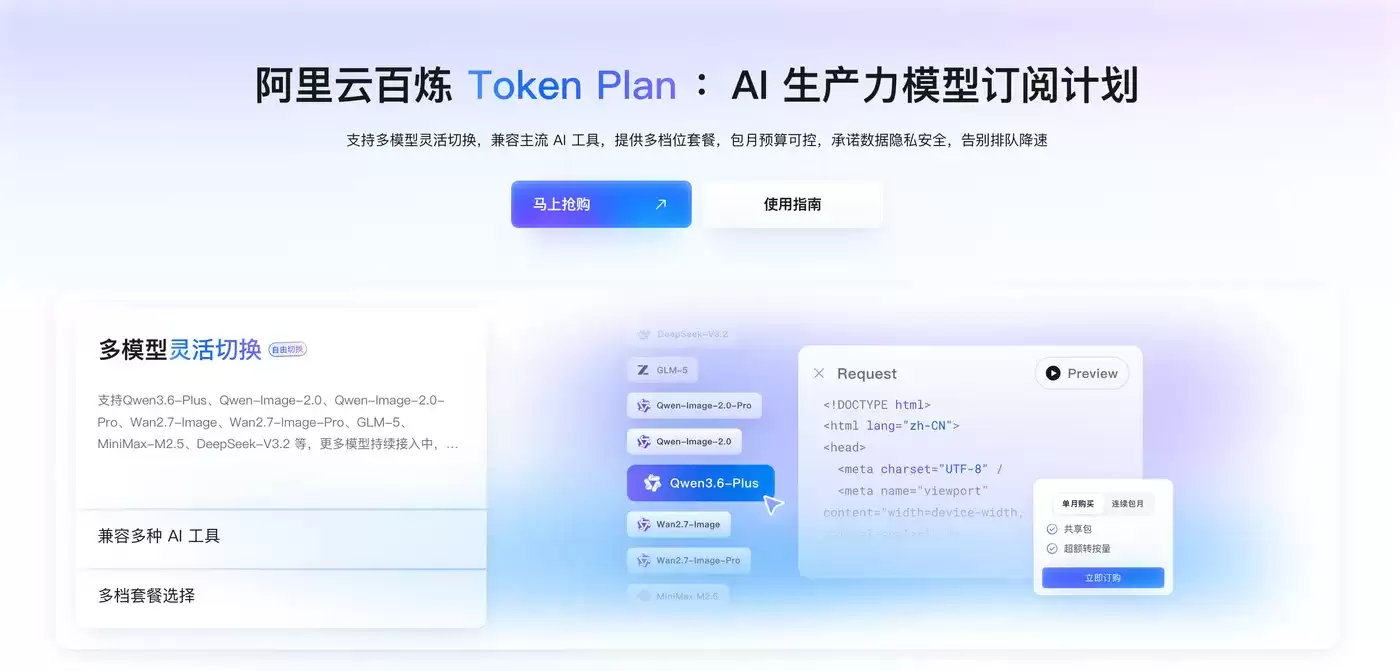



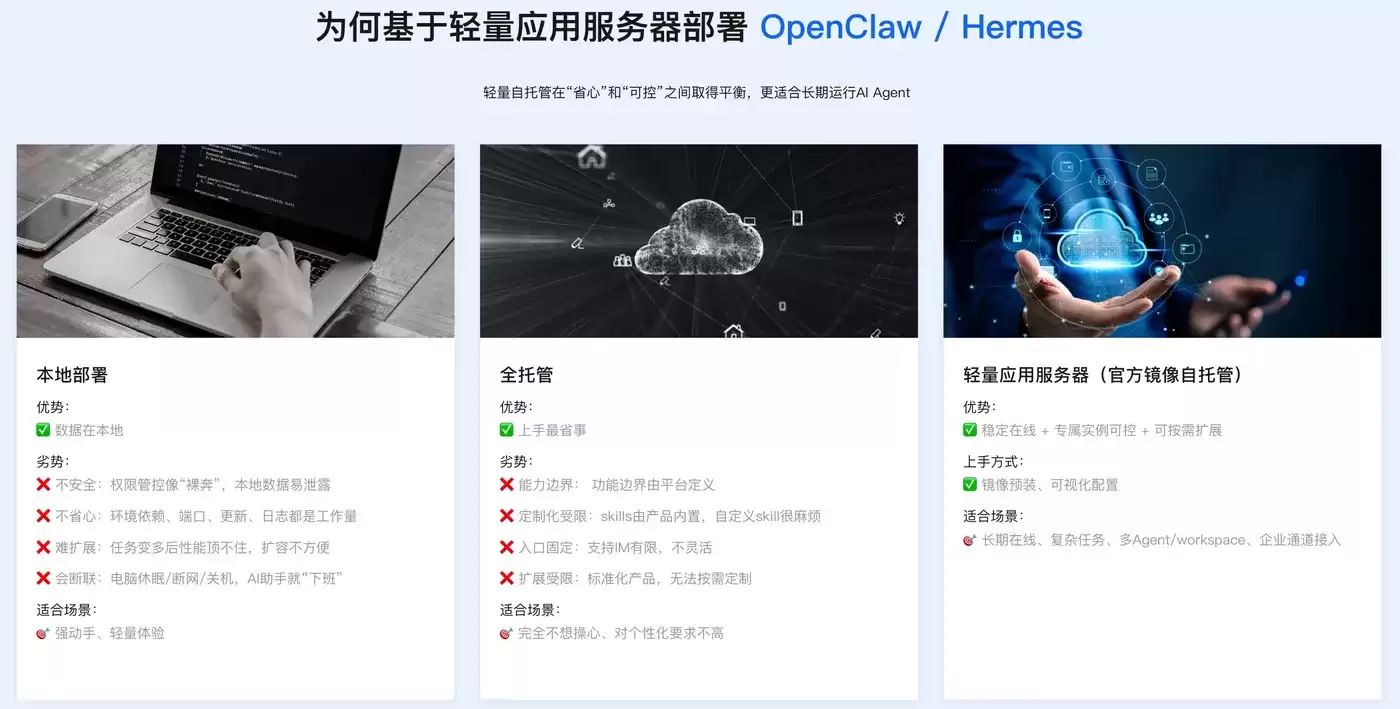
除GPU外,需配置不低于1TB的高速SSD存储模型权重,内存≥256GB(生产场景建议512GB),网络带宽≥10Gbps以保障模型下载与推理效率,避免IO瓶颈影响服务稳定性。
vLLM是当前最主流的大模型推理框架,支持Prefill-Decode分离、Prefix Caching等高级特性,GLM 5.2从v0.23.0版本开始支持,适合通用生产场景部署,以下为完整实战步骤。
# 创建独立虚拟环境
python3 -m venv glm52-vllm
source glm52-vllm/bin/activate
# 安装vLLM与模型下载工具
pip install vllm==0.23.0 huggingface-hub
# 从HuggingFace拉取FP8模型,10G网络约40分钟完成
huggingface-cli download zai-org/GLM-5.2-FP8
--local-dir /data/models/glm52-fp8
--local-dir-use-symlinks False
# 校验文件占用,确保磁盘空间充足
du -sh /data/models/glm52-fp8
vllm serve "zai-org/GLM-5.2-FP8"
--tensor-parallel-size 8 # 8卡张量并行,适配8×H200节点
--max-model-len 262144 # 最大上下文长度,匹配模型能力
--kv-cache-dtype fp8 # KV缓存FP8量化,显存占用减半
--enable-prefix-caching # 复用系统提示词缓存,提升吞吐
--port 8000 # 服务端口
--gpu-memory-utilization 0.8 # GPU显存利用率,避免OOM
--tool-call-parser glm47 # 工具调用解析器,适配GLM 5.2
--reasoning-parser glm45 # 推理模式解析器,支持复杂逻辑
# 调用接口测试,返回OK代表服务正常
curl -s http://localhost:8000/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "zai-org/GLM-5.2-FP8",
"messages": [{"role":"user","content":"输出OK作为返回结果"}],
"max_tokens": 16
}' | jq -r '.choices[0].message.content'
若返回OOM,降低max-model-len至131072重新启动;若模型加载失败,检查GPU驱动与CUDA版本(推荐12.1+)。
SGLang内置RadixAttention,在多轮代码智能体、百万文档RAG场景吞吐比vLLM提升3倍,适合Hermes、OpenClaw等长任务智能体后端,推荐FP8权重部署。
# 创建独立虚拟环境
python3 -m venv glm52-sglang
source glm52-sglang/bin/activate
# 安装SGLang与依赖
pip install sglang==0.5.13.post1 huggingface-hub
python3 -m sglang.launch_server
--model-path zai-org/GLM-5.2-FP8
--tp-size 8 # 8卡张量并行
--max-model-len 262144 # 最大上下文长度
--kv-cache-dtype fp8 # KV缓存FP8量化
--enable-prefix-caching # 前缀缓存优化
--port 8001 # 服务端口(与vLLM区分)
--tool-call-parser glm47 # 工具调用支持
--reasoning-parser glm45 # 推理模式支持
--speculative-algorithm EAGLE # speculative解码,提升速度
--speculative-num-steps 3# speculative步骤,平衡速度与质量
使用与vLLM相同的curl命令测试,端口改为8001,返回OK代表服务正常;长上下文场景可通过输入百万tokens文档测试吞吐与响应速度。
自托管GLM 5.2的核心优势是数据隐私可控与长期成本优化,但前期硬件投入高,需测算盈亏平衡点,避免盲目部署。
max-model-len、减少gpu-memory-utilization、切换更低量化版本(如从FP8改为Q4_K_M)。GLM 5.2自托管是企业实现大模型私有化部署、数据隐私可控的最优选择,但需精准匹配硬件与量化版本,选择vLLM(通用生产)或SGLang(长上下文智能体)部署框架,并严格测算成本盈亏平衡点。对于日均请求超3000次的企业生产场景,自托管可大幅降低长期成本;个人调试可通过Mac Studio M3 Ultra运行轻量量化版,满足基础研发需求。部署过程中需关注显存优化、推理效率与成本控制,结合场景选择最优方案,实现GLM 5.2的高效落地与价值最大化。