AI 智能体项目费用
2026-06-27 3369958
2026-06-27 0
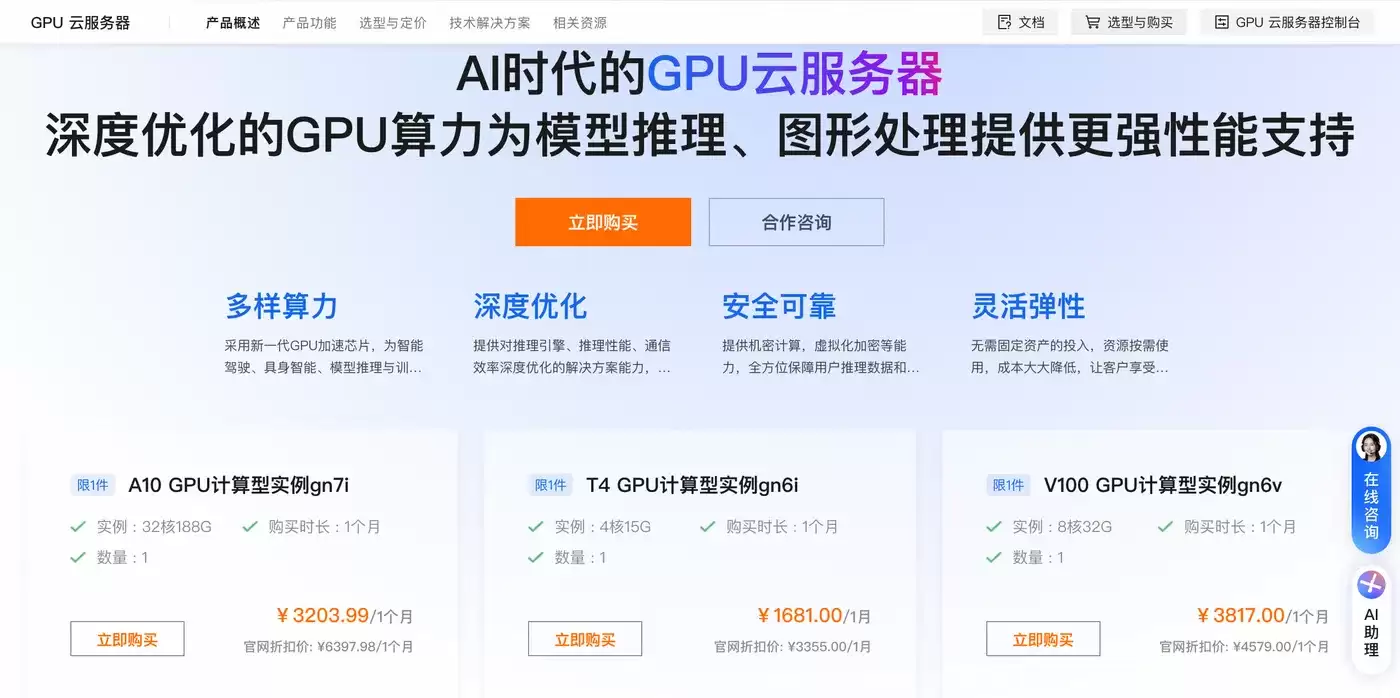
DeepSeek-V4-Pro作为旗舰级大语言模型,采用稀疏混合专家架构,总参数量达1.6万亿,具备百万级上下文、复杂推理与多步任务编排能力,广泛应用于科研、企业级AI服务与智能体开发场景。本地部署受限于硬件门槛与算力成本,阿里云GPU云服务器提供弹性算力与稳定环境,可快速完成模型部署与推理服务搭建。本文从硬件选型、环境配置、模型部署到服务验证,提供保姆级全流程指南,零基础用户也能顺利完成部署。
部署DeepSeek-V4-Pro需满足严苛硬件要求,阿里云GPU云服务器提供适配机型,确保模型稳定运行。
sudo yum update -y
sudo yum install -y gcc gcc-c++ make git wget unzip
# 安装NVIDIA驱动
sudo sh NVIDIA-Linux-x86_64-550.54.04.run
# 安装CUDA
sudo sh cuda_12.9.0_535.104.05_linux.run
# 配置环境变量
echo 'export PATH=/usr/local/cuda-12.9/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.9/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
nvidia-smi
nvcc -V
vLLM是部署DeepSeek-V4-Pro的推荐框架,支持高效推理与分布式部署。
pip install vllm>=0.20.1
git clone https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
python -m vllm.entrypoints.openai.api_server
--model ./DeepSeek-V4-Pro
--host 0.0.0.0
--port 8000
--tensor-parallel-size 8
--dtype auto
sudo vim /etc/systemd/system/deepseek-v4-pro.service
[Service]User=rootWorkingDirectory=/root/DeepSeek-V4-ProExecStart=python -m vllm.entrypoints.openai.api_server --model ./DeepSeek-V4-Pro --host 0.0.0.0 --port 8000 --tensor-parallel-size 8 --dtype autoRestart=always
[Install]WantedBy=multi-user.target
启动并设置开机自启:
```bash
sudo systemctl daemon-reload
sudo systemctl start deepseek-v4-pro
sudo systemctl enable deepseek-v4-pro
curl http://localhost:8000/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "deepseek-v4-pro",
"messages": [{"role": "user", "content": "解释DeepSeek-V4-Pro的核心架构"}]
}'


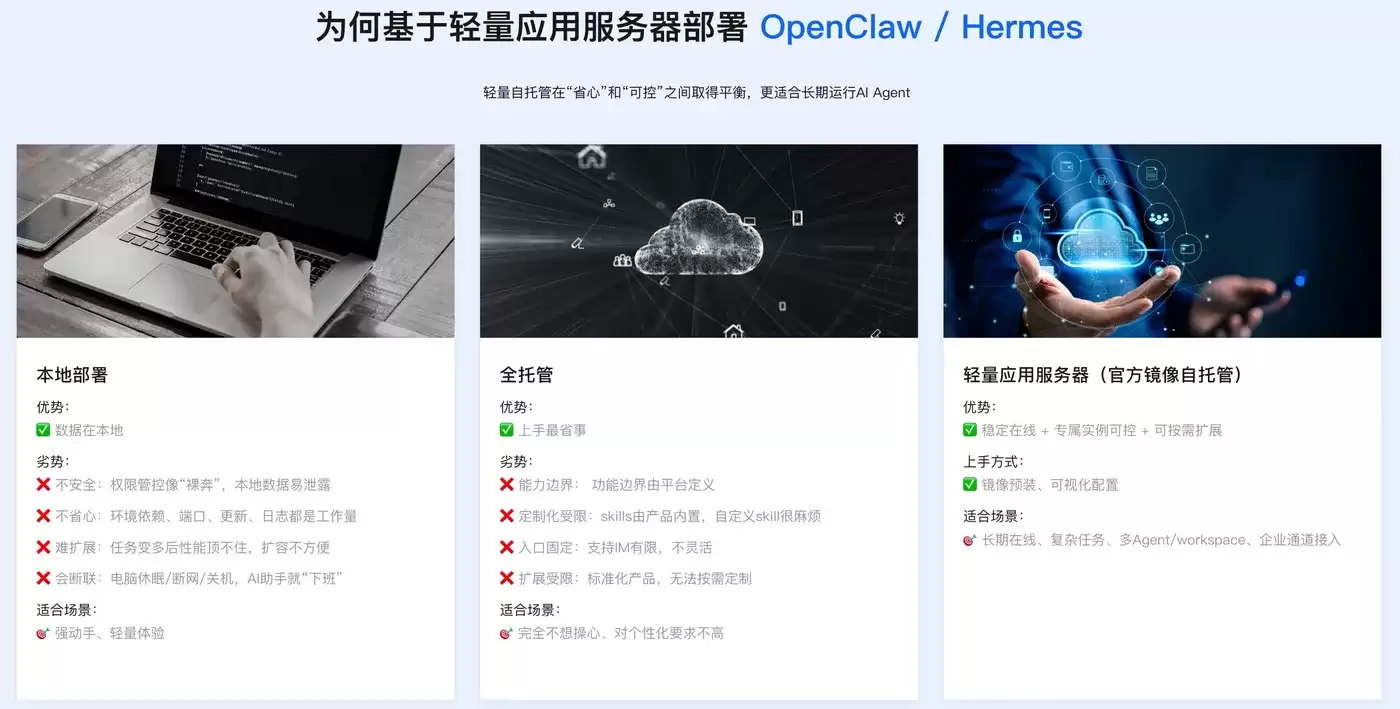
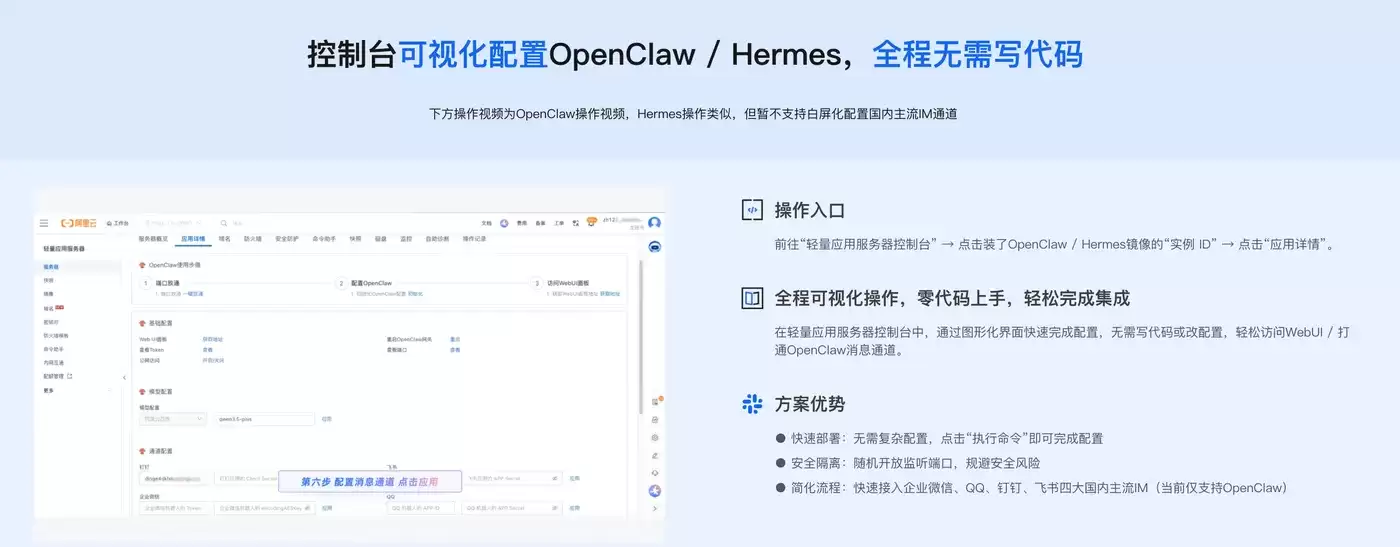
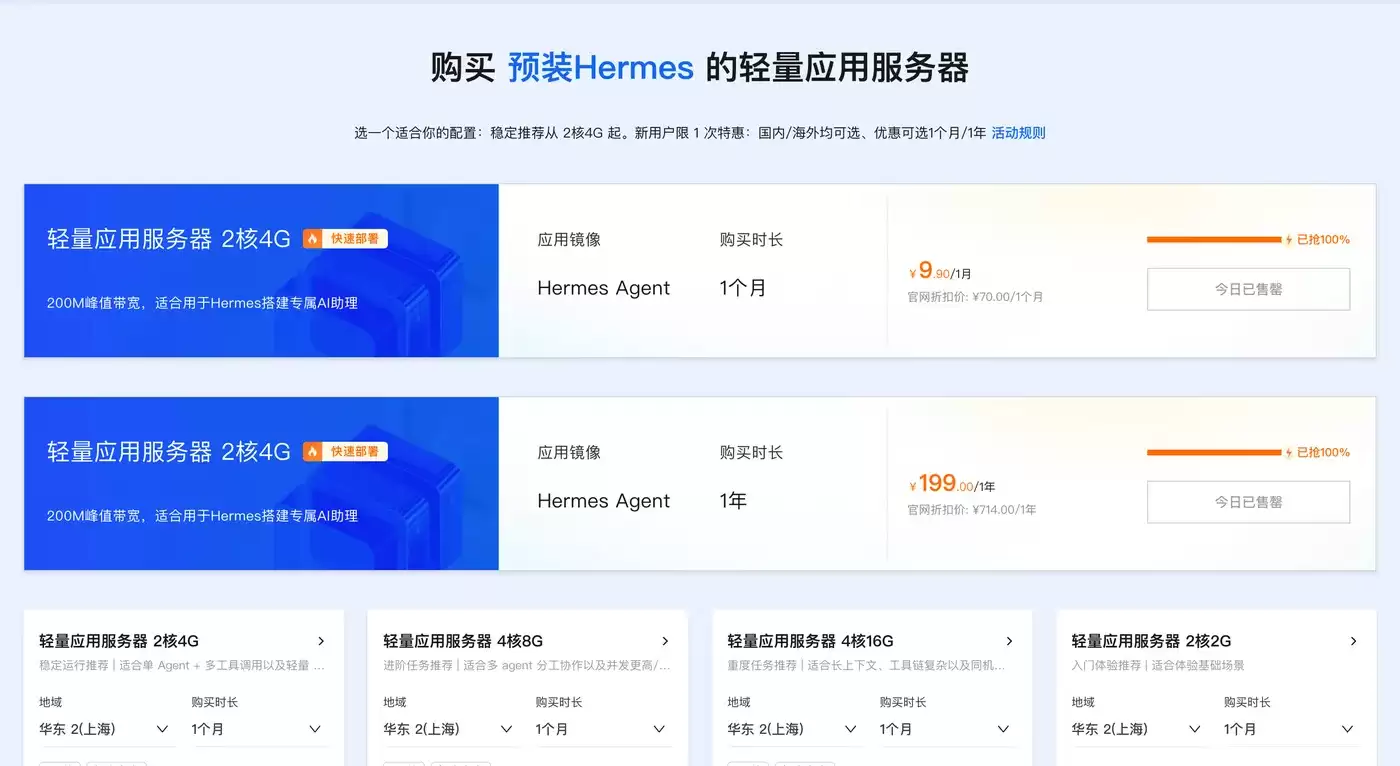
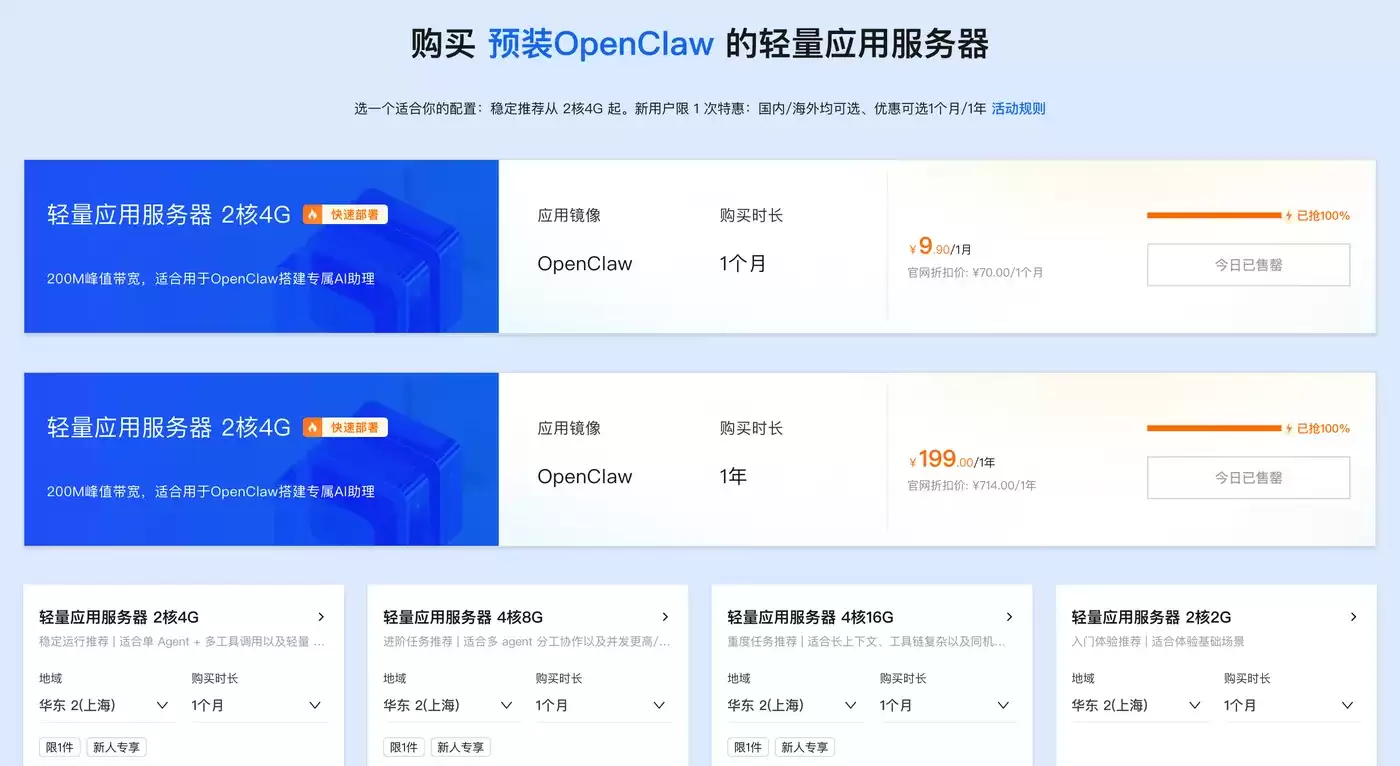
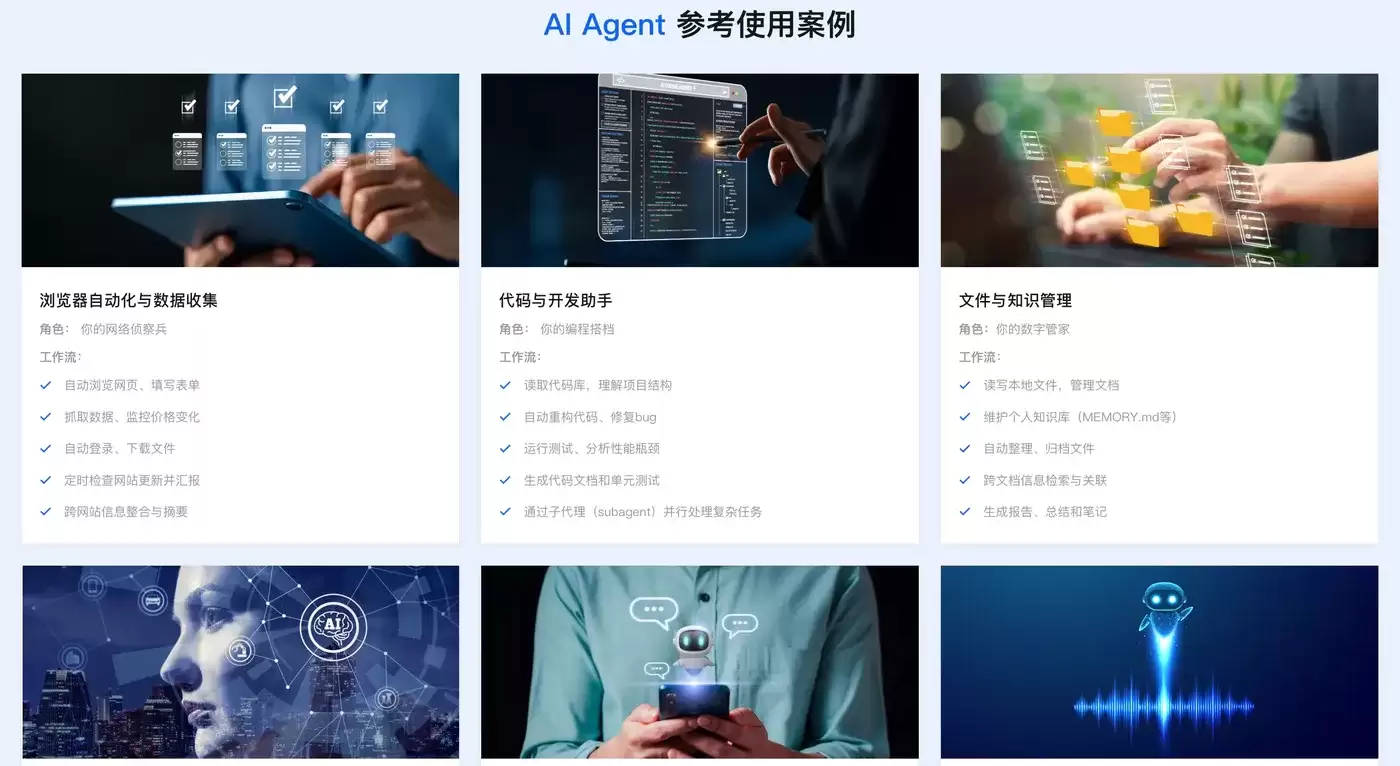
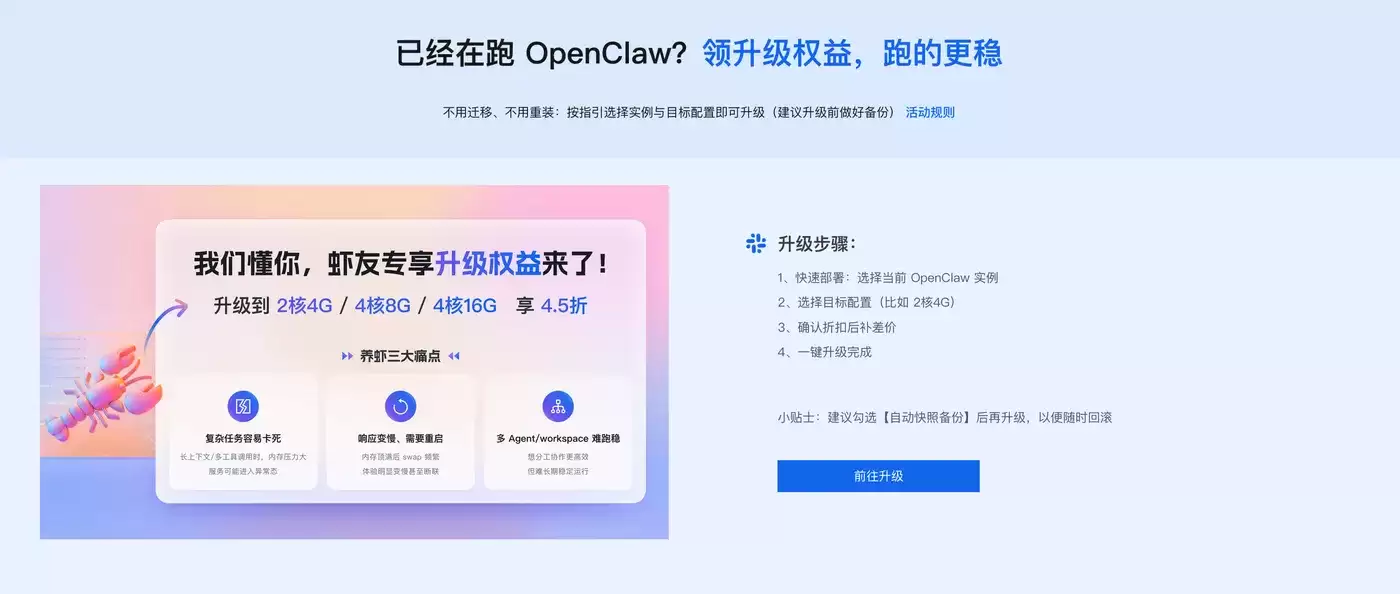 Token Plan Token最便宜/支持多模型切换:访问订阅阿里云百炼Token Plan AI大模型服务 。支持多模型切换,用于多模态模型灵活调用,实现多模型、多工具、多场景下的额度共享与统一管理,兼顾灵活性、稳定性与安全性,大幅降低企业使用大模型的门槛与成本。
Token Plan Token最便宜/支持多模型切换:访问订阅阿里云百炼Token Plan AI大模型服务 。支持多模型切换,用于多模态模型灵活调用,实现多模型、多工具、多场景下的额度共享与统一管理,兼顾灵活性、稳定性与安全性,大幅降低企业使用大模型的门槛与成本。



阿里云GPU云服务器为DeepSeek-V4-Pro部署提供了弹性、稳定的算力支撑,通过保姆级流程可快速完成从实例创建到服务上线的全流程操作。从硬件选型、环境配置到模型部署与优化,每一步都有明确指引,降低了大模型部署的技术门槛。该方案适用于个人开发者测试、企业级AI服务搭建与科研场景,结合阿里云的弹性扩展与安全能力,可高效释放DeepSeek-V4-Pro的强大推理能力,满足复杂AI任务需求。