如何通过WebSocket订阅全球股票实时行情
2026-06-29 3372549
2026-06-29 0
工程师说"写个删除按钮",AI 给了个蓝色实心按钮——颜色、大小、位置都对,但语义错了。设计师想说的是"这是高危操作,点了会丢数据",AI 没听到这层意思。规范写在文档里,AI 读不到;设计师圈图发群里,AI 看不到。当 AI 从"执行指令"变成"理解意图",语义一致性成了最大的隐性成本。
把设计规范写成代码格式(Schema-As-Code),就是要给设计意图加一个语义锚点:输入是"什么场景下用什么情绪、什么边界不可突破",输出是机器可读的约束契约——编译进 Prompt、变成校验规则、绑定到组件 Props。让 AI 在生成之前,先知道"不能做什么"。
但在这之前,我们需要先回答一个问题:设计意图在哪里偏离了?
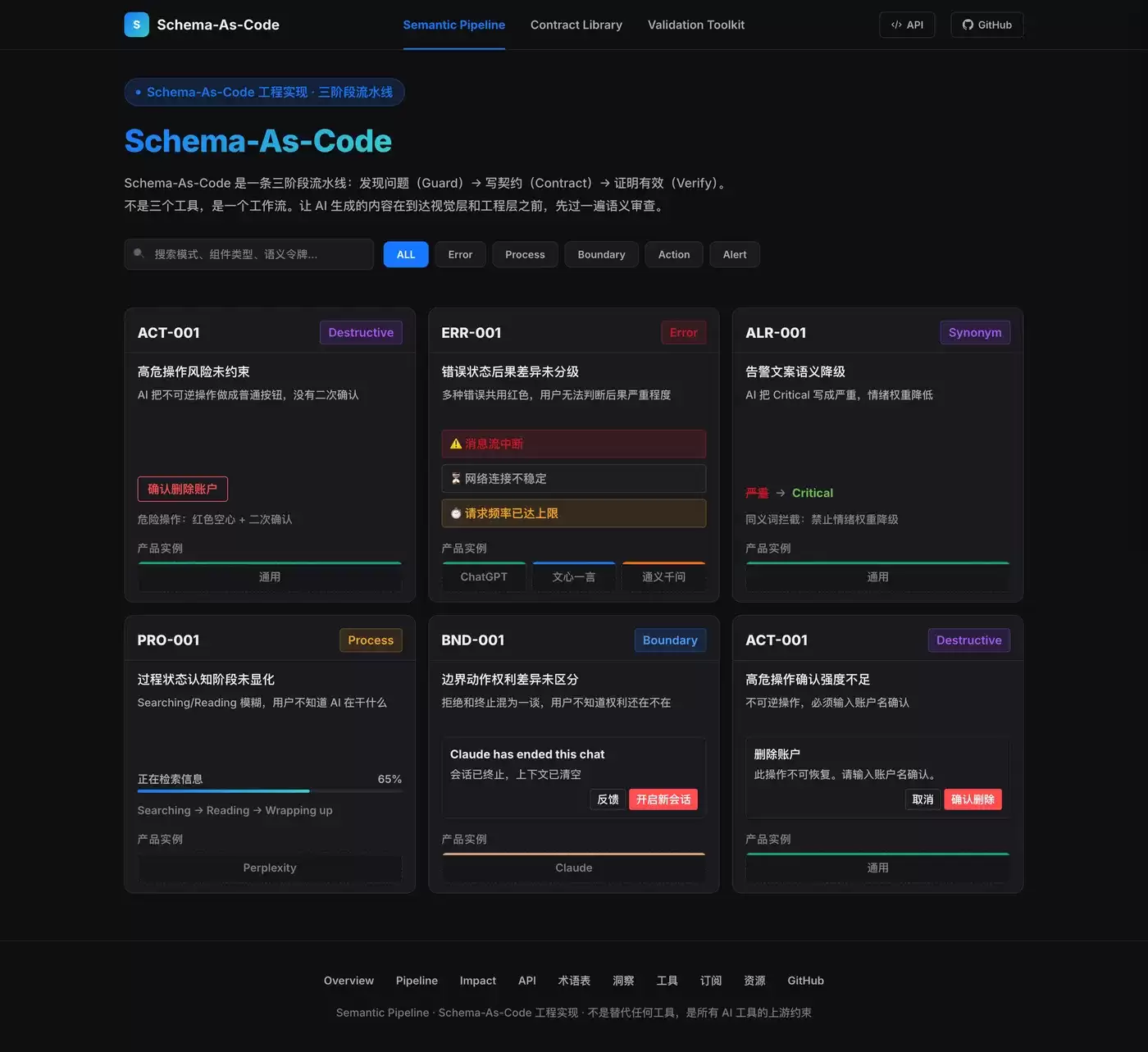
我观察了 8 类 AI 产品的界面生成结果,发现它们共享同一套组件语义偏差模式。这些偏差不是某个产品的 Bug,而是 AI 概率性生成的内禀属性。
当 AI 从"执行指令"变成"理解意图"时,语义一致性成了最大的隐性成本。
组件语义快照(Component Semantic Snapshot):一种结构化的界面证据收集方法。不是截图,而是带有语义标注的界面记录,包含 6 个标准字段:
字段 | 说明 | 示例 |
snapshot_id | 快照唯一编号 | SNAP-202506-001 |
product | 产品名称 | ChatGPT / 文心一言 / 通义千问 |
component_type | 组件类型 | 错误状态 / 过程状态 / 边界动作 / 操作按钮 / 告警状态 |
screenshot | 界面截图(含标注) | 红色框标注语义问题区域 |
user_confusion | 用户困惑描述(原话或推断) | "看到红色就刷新,结果只是限流" |
context | 触发场景 | 快速发送 5 条消息后触发 |
产品类型 | 典型组件 | 语义偏差表现 |
通用对话(ChatGPT / Claude) | 错误状态、边界动作 | 多种错误共用红色,拒绝与终止混为一谈 |
搜索增强(Perplexity / 秘塔) | 过程状态 | Searching / Reading / Wrapping up 模糊,用户不知道 AI 在查资料还是编答案 |
国产大模型(文心一言 / 通义千问 / Kimi / 豆包 / 讯飞星火) | 错误状态 | 流式中断、网络错误、限流、服务异常四种后果共用红色 |
AI 编程(Claude Code / Cursor / Copilot) | 操作按钮 | 删除账户按钮做成蓝色实心,缺少二次确认 |
AI 原型(v0 / Framer AI) | 操作按钮、告警状态 | 高危操作未约束,告警文案语义降级(Critical → 严重) |
企业组件库(DevUI / Ant Design) | 错误状态、操作按钮 | 组件用对了,但语义场景用错 |
设计系统(Figma MCP / DESIGN.md) | 视觉规范 | Token 只管颜色,不管场景语义 |
可观测性(LoongSuite / LangSmith) | 运行时追踪 | 事后追踪漂移,但缺少事前拦截 |
关键发现:不是某个产品做错了,而是整个行业在 AI 生成界面时,缺少一层语义约束。
语义偏差不是随机发生的。按组件类型分类后,我们发现漂移模式是可归纳、可命名、可复用的。
AI 生成的界面组件,按用户交互场景分为 5 类:
组件类型 | 用户场景 | 典型漂移 |
错误状态 | 用户遇到故障时看到的 | 后果差异未分级(全部红色) |
过程状态 | AI 干活时显示的进度 | 认知阶段未显化(Searching/Reading 模糊) |
边界动作 | AI 拒绝 / 终止 / 升级时 | 权利差异未区分(拒绝 vs 终止混为一谈) |
操作按钮 | 用户点击执行的 | 高危操作未约束(删除按钮做成普通样式) |
告警状态 | 系统状态提示 | 语义降级(Critical 被写成"严重") |
每个漂移模式被标准化为一张模式卡片(Pattern Card),包含 6 个字段:
字段 | 说明 |
pattern_id | 模式唯一编号(如 ERR-001) |
component_type | 组件类型 |
symptom | 症状描述(用户看到什么) |
root_cause | 根因分析(缺少什么语义令牌) |
evidence | 证据(3-5 个产品截图 + 用户抱怨) |
suggested_contract | 建议契约模板(YAML 文件链接) |
Step 1:识别组件类型
选项 | 说明 |
错误状态 | 用户遇到故障时看到的 |
过程状态 | AI 干活时显示的进度 |
边界动作 | AI 拒绝 / 终止 / 升级时 |
操作按钮 | 用户点击执行的 |
告警状态 | 系统状态提示 |
Step 2:确认用户困惑
选项 | 对应漂移类型 |
不知道多严重 | 后果差异 |
不知道在干什么 | 认知阶段 |
不知道权利还在不在 | 权利差异 |
不知道能不能点 | 操作风险 |
不知道词对不对 | 语义降级 |
Step 3:记录视觉表达
选项 | 典型表现 |
全部红色 | 多种错误共用同一种红色 |
全部灰色 | 所有状态都显示为中性灰 |
没有区分 | 不同性质的操作视觉相同 |
文案模糊 | 只描述现象,不指引行动 |
Step 4:模式匹配
系统根据三个维度的输入,从模式库中匹配对应的模式卡片,输出:
输入:组件类型 + 困惑类型 + 视觉表达 ↓ 匹配:模式库中同时满足三个条件的模式 ↓ 输出:模式 ID + 根因 + 证据 + 建议契约
Semantic Pipeline 的架构是确定性规则做骨架,AI Agent 做血肉。既不是纯 AI 工具,也不是纯规则工具。
语义约束的流转必须遵循 Code-Text-Code 闭环:
阶段 | 形态 | 操作 |
Code | YAML 规则文件 | 设计师用代码格式写约束 |
Text | Prompt 前缀 / 自然语言 | 机器把代码翻译成 AI 能消费的文本 |
Code | JSON / 组件 Props | AI 生成文本后,机器把文本转回代码进行校验 |
关键设计:如果缺少"闸门",Text 阶段的概率性输出会污染整个闭环。Semantic Pipeline 就是这个闭环的校验节点,在 Text → Code 的转换处拦截漂移。
AI Agent 的生成能力受分层控制架构约束,决策空间被划分为两区:
柔性决策域(Model 负责) 承担"如何生成"的优化问题,即参数空间内的搜索与选择:
硬约束边界(Harness 负责) 定义"什么绝对不能发生",即输出空间的禁区:
分治逻辑:模型在 Harness 划定的语义安全空间内行使创造力,Harness 不介入生成细节,但以硬规则封闭输出边界。形成"模型负责优化,Harness 负责合规"的架构契约。
阶段一的判定逻辑遵循四级审查,不是全自动,是人机协同:
阶段 | 执行方 | 动作 | 产出 |
review | 人工 | 审核症状(截图、用户投诉、AI 生成差异) | 症状描述 |
verdict | 系统 | 判决模式匹配(组件类型 + 困惑类型 + 视觉表达) | 模式 ID + 根因推断 |
revise | 人工 | 修正根因(确认或修改系统推断) | 确认后的根因 |
verify | 系统 | 验证入库(检查 6 字段完整性,归档模式库) | 模式卡片 |
设计原则:
阿里云在《构建可审计、可进化的 AI Agent 底座》中提出"约束基建"是 AI 可信底座。核心观点与 Schema-As-Code 完全一致:
与 Schema-As-Code 的关系:
目前验证的 6 个模式,覆盖最常见的语义断层:
模式 ID | 组件类型 | 断层名称 | 症状 | 根因 |
ERR-001 | 错误状态 | 后果差异未分级 | 多种错误共用红色 | 缺少 error_severity 语义令牌 |
PRO-001 | 过程状态 | 认知阶段未显化 | Searching/Reading 模糊 | 缺少 process_phase 语义令牌 |
BND-001 | 边界动作 | 权利差异未区分 | 拒绝和终止混为一谈 | 缺少 boundary_action 语义令牌 |
ACT-001 | 操作按钮 | 高危操作未约束 | 删除按钮做成普通样式 | 缺少 destructive_action 语义令牌 |
ALR-001 | 告警状态 | 语义降级 | Critical 被写成"严重" | 缺少 synonym_firewall 规则 |
FRM-001 | 表单输入 | 校验语义缺失 | 错误提示只说"格式不对" | 缺少 validation_semantic 规则 |
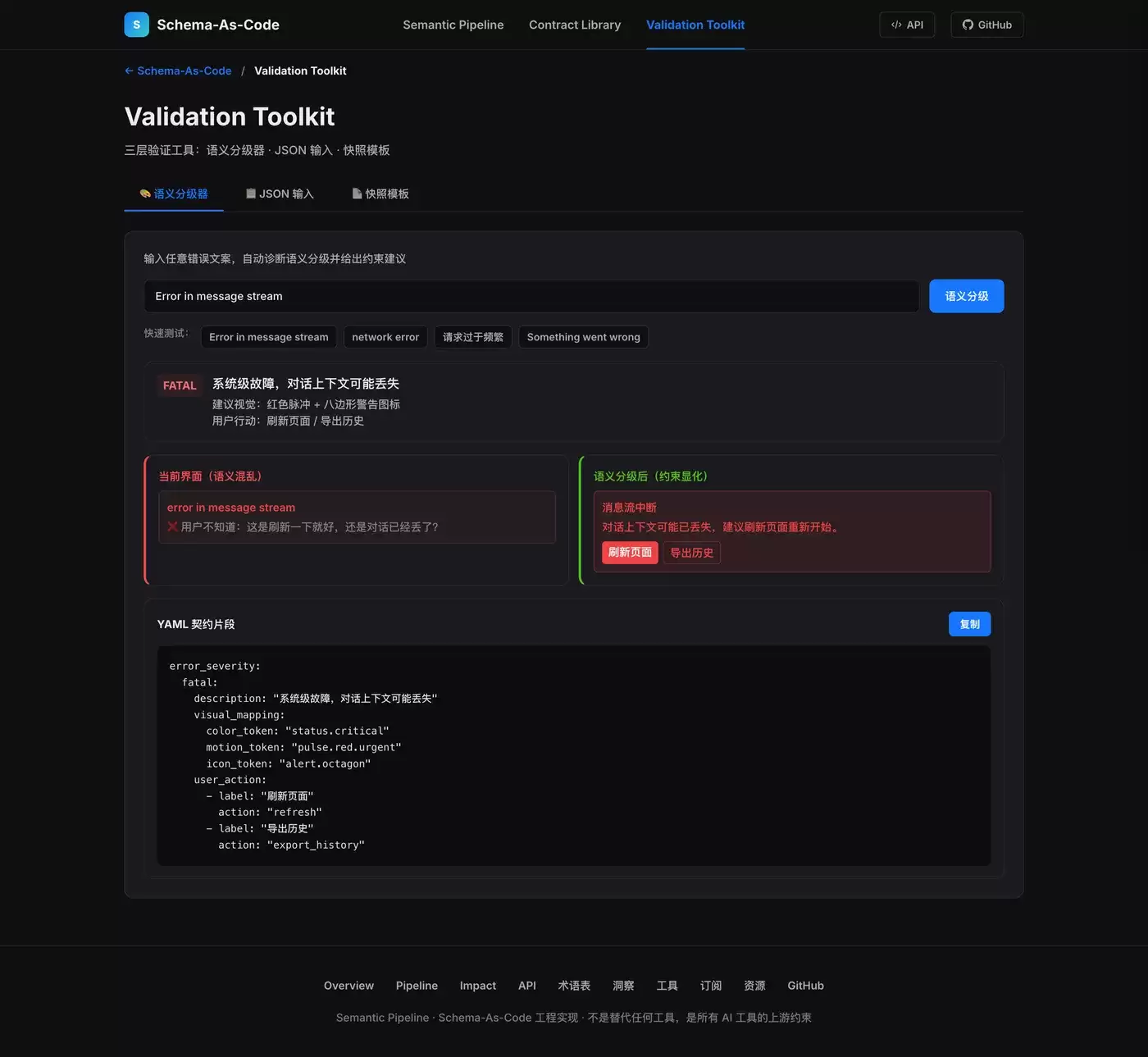
模式卡片:ERR-001 组件类型:错误状态 症状:同一产品内多种错误共用红色视觉语言,用户无法判断后果严重程度 根因:缺少 error_severity 语义令牌,系统无法区分致命错误、网络抖动、 频率限制和部分可用四种不同的错误性质 证据: 产品实例 1:ChatGPT - "Error in message stream"(红色背景条) - "network error"(红色文字) - "Something went wrong"(红色边框卡片) - "Too many requests"(红色文字 + 感叹号) 产品实例 2:文心一言 - "连接断开"(红色提示) - "网络错误"(红色文字) 产品实例 3:通义千问 - "流式输出中断"(红色提示) - "429 Throttling"(红色文字) 用户抱怨: - "看到红色就刷新,结果只是限流" - "不知道对话还在不在" - "Something went wrong 到底是什么意思?" 建议契约:intent/ERR-001.yaml - 定义 error_severity 四级:fatal / transient / retryable / degraded - 每级绑定不同视觉映射和用户行动
根因分析必须是一句话,格式固定:
"这个症状的根因是:缺少 [语义令牌名称] 语义令牌,导致 [具体后果]。"
正确示例:
错误示例(禁止):
Semantic Pipeline 是 设计规范写成代码格式(Schema-As-Code)方法论的工程实现。
它把"把设计规范写成代码格式"这个抽象目标,拆解成一条可执行的流水线:
诊断(Guard)→ 契约(Contract)→ 验证(Verify)。
三阶段不是三个产品,是一个流水线的三个环节。每个环节的产出是下一环节的输入,形成闭环。
功能 | 说明 |
症状录入 | 上传截图、粘贴用户投诉原文、选择组件类型 |
诊断问卷 | 回答 3 个结构化问题,系统自动匹配模式 |
模式匹配 | 展示同类产品的截图证据 + 用户抱怨证据 |
根因确认 | 系统提示"缺少 XX 语义令牌",设计师确认或修正 |
诊断报告 | 输出模式 ID + 症状描述 + 根因分析 + 建议契约模板 |
设计规范写成代码格式(Schema-As-Code)方法论 = 诊断(Guard)+ 契约(Contract)+ 验证(Verify)。本文聚焦阶段一,但三阶段是完整方法论的整体框架。
方法论 | 资产库 | 工程化实现 | 产出 | 用户场景 |
诊断 | 模式库 | Semantic Pipeline | 模式卡片(症状 + 根因 + 证据) | 设计意图在哪里偏离了? |
契约 | 契约库 | Contract Library | YAML 契约 + Prompt 前缀 + 校验规则 | 怎么把设计意图写成机器可读的约束? |
验证 | 验证工具集 | Validation Toolkit | A/B 对比 + 测试报告 + 返工率数据 | 加了约束后,问题真的解决了吗? |
阶段衔接逻辑:
阶段一 Semantic Pipeline 产出:模式卡片(ERR-001) ↓ 根因:缺少 error_severity 语义令牌 阶段二 Contract Library 动作:写 YAML 契约(定义 fatal/transient/retryable/degraded 四级) ↓ 编译为:Prompt 前缀 + 组件 Props 校验规则 + 走查 Checklist 阶段三 Validation Toolkit 动作:跑验证(对比"有契约"和"无契约"的生成结果) ↓ 产出:返工率从 30% 降到 5%
阶段二(Contract Library)的核心任务:
阶段三(Validation Toolkit)的核心任务:
语义漂移发生在全链路,界面是最终呈现面——后端的漂移再隐蔽,最终通过组件暴露给用户。
层级 | 漂移类型 | 界面表现 |
数据层 | 数据标注错误 | 搜索结果显示错误来源 |
业务层 | 业务规则理解偏差 | 价格计算错误 |
策略层 | 推荐策略偏离 | 推荐内容与用户意图不符 |
知识层 | 知识库更新滞后 | 回答包含过时信息 |
界面 | 组件语义偏差 | 按钮颜色、文案、交互错误 |
关键洞察:界面不是漂移的起点,是漂移的最终呈现面。修复界面语义偏差,往往要追溯到上游层级的约束缺失。但反过来,界面层的约束也可以反哺上游——当界面发现异常时,向上游反馈,驱动后端治理。
角色 | 日常工具 | 使用场景 | 操作路径 | 得到什么 |
设计师 | Figma、语雀 | 走查发现某个组件体验不对 | 打开 Semantic Pipeline → 回答 3 个问题 → 匹配模式 | 模式定义 + 同类证据 + 改造方案 |
DesignOps | GitHub、Notion | 规范要更新,不知道怎么同步 | 把规范变更写成 YAML → Git Diff 自动触发影响面分析 | 规范同步从 2 周 → 0.5 天 |
前端工程师 | VS Code、Cursor、Claude Code | AI 生成的代码语义错误多 | 在 Prompt 里贴一段规则前缀(从契约库复制) | 语义返工率从 30% → 5% |
AI 产品 PM | 飞书、Jira | 要上线 AI 功能,担心体验不一致 | 用验证工具跑一遍产品的错误状态 | 风险清单 + 契约模板 |
设计规范写成代码格式(Schema-As-Code)是所有 AI 工具的上游约束方法论。
Semantic Pipeline 是这套方法论的工程实现,把“约束”从理念变成可执行的流水线。
工具类型 | 解决什么 | 不解决什么 | 怎么叠加 |
设计转码(Anima / Builder) | 从图到代码 | 语义漂移 | 导出前校验规则 |
AI 原型(v0 / Framer AI) | 快速验证想法 | 语义一致性 | 生成前 Prompt 前缀 |
AI 编程(Claude Code / Cursor) | 自然语言写代码 | 设计意图约束 | Prompt 上下文注入 |
企业组件库(DevUI / Ant Design) | 符合组件规范 | 语义场景匹配 | Skill 语义映射规则 |
设计系统(DESIGN.md) | 视觉规范机器可读 | 场景语义约束 | 消费 Semantic Token |
可观测性(LoongSuite / LangSmith) | 运行时漂移追踪 | 事前预防 | 设计时约束 + 运行时观测 = 双轨闭环 |
核心定位:
这些工具在形态层(视觉 + 工程)竞争,Semantic Pipeline 在语义层补位。约束的不是"怎么写代码",而是"这个场景下必须表达什么语义、不能突破什么边界"。
指标 | 之前 | 之后 | 变化 |
语义返工率 | 30% | 5% | 前端修 AI 语义错误的时间减少 83% |
规范同步时间 | 2 人周 | 0.5 天 | DesignOps 人肉同步变成代码自动同步 |
走查覆盖率 | 20% | 100% | 机器走查替代人眼抽查 |
线上语义事故 | 占用户投诉 15% | 趋近于 0 | 约束前置,问题在生成前被拦截 |
价值公式:
以前修一个语义错误 10 分钟,100 个错误就是 2 人天。现在写一次规则(YAML),机器自动拦,边际成本趋近于零。
Gap 期局限性声明
当前状态: 架构推演与最小可行原型阶段。YAML 规范、校验逻辑为定义层实现,尚未接入生产级 LLM API 或 CI 流水线。欢迎基于现有思路共建。
关于作者
魏雯,体验架构设计师。
专注于:AI 界面的语义治理。解决的核心问题:让 LLM 生成的界面不偏离设计规范。
10+ 年互联网设计经验。设计系统 / 体验工程 / AI 原生|广州 / 深圳
改成一个通用的Gap 期局限性声明