皮克斯风超市搞笑动画
2026-06-30 3373427
2026-06-30 0
从“文档堆”到“可信知识底座”,一篇讲清企业级知识库的构建全链路,助你避开常见工程大坑。核心内容:1. 明确企业级知识库与“文档堆”的本质区别与核心要素2. 剖析RAG项目从Demo到生产落地的主要挑战与系统工程思维3. 提供从目标定义、知识资产盘点、到全链路架构落地的实用方法
从“文档堆”到“可信知识底座”:一篇讲清目标、方法、架构与落地细节的通俗指南
适用:技术/研发/产品/运营/客服/运维
场景:文档知识库 + AI问答(RAG)
阅读:约12分钟
很多团队说要“做知识库”,最后做成了共享盘、Wiki 或者一个“能搜的文档堆”。这些东西当然有价值,但当你希望它稳定支撑协作、甚至支撑AI问答时,就必须把定义往前推一步:
工程语境里的知识库不是文件的集合,而是一套面向检索与复用的信息系统。至少包含:内容载体、结构与元数据、检索与使用方式、治理机制、反馈闭环。“文档堆”长什么样?有大量资料,但缺少统一命名、缺少版本、缺少负责人;能搜到但无法判断对不对;一更新就“旧答案复活”。
“企业级知识库”长什么样?内容可检索、可定位、可追溯;答案能指向来源;权限可控;上线后可运营、可度量、可持续迭代。
如果你要把知识库接入AI知识助理(RAG),还要额外明确:哪些Agent/应用用哪些知识库,以及“分块、召回、重排”等系统旋钮由谁管理、如何变更。
RAG 的Demo确实很快:把文件丢进向量库,接上大模型,套个聊天界面,三天就能跑起来。真正难的是:你把它交给一线同学用,交给合规部门看,交给运维团队来扛稳定性,才会发现它不是“一个模型问题”,而是系统工程。
一个关键认知:RAG 只是“知识层的一部分”,决定项目成败的,往往是围绕它的工程底盘与控制系统(评估、门禁、监控、迭代机制)。
更具体一点,很多团队会踩的坑常见有五类:分块策略、Embedding 选型、上下文导致的幻觉、数据预处理、反馈闭环。这五类坑,本质上对应了“从内容到系统”的五个薄弱环节。
把企业级知识库当作一条“生产线”会更容易做对:输入是混乱的资料,输出是可检索、可信任、可迭代的组织资产。下面这张图把全链路摊开:从内容盘点到上线运营,缺一环都容易掉链子。
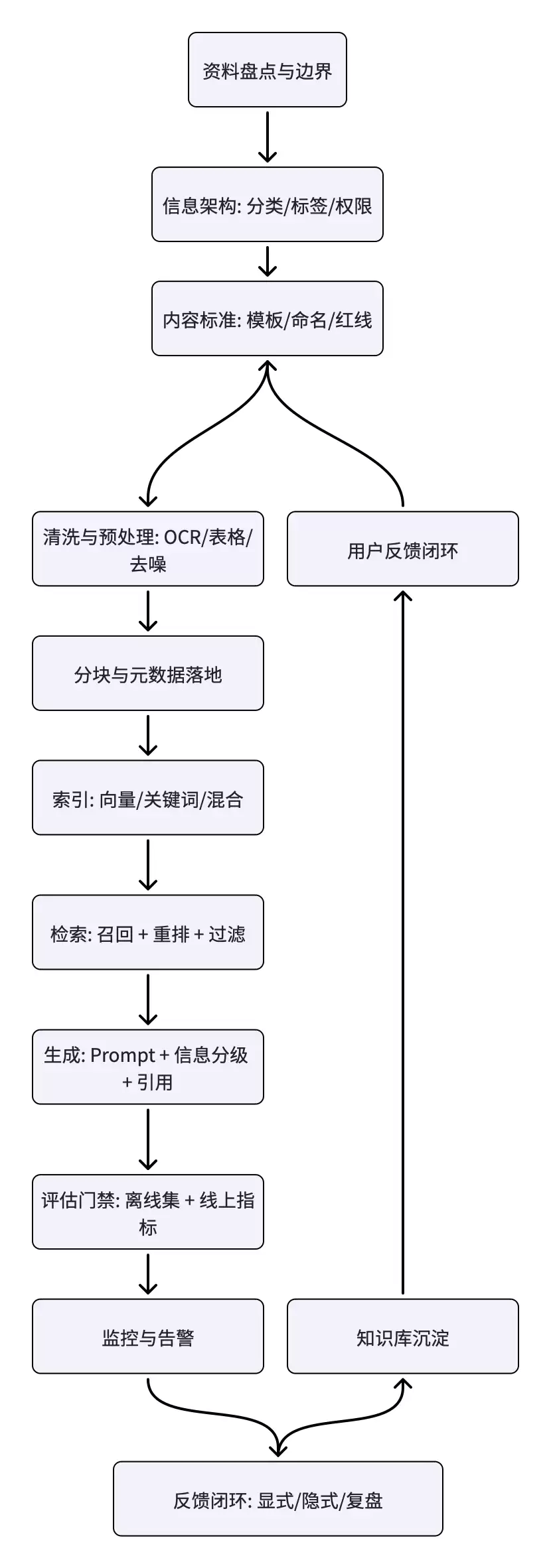
企业级项目最怕“目标模糊”。知识库不是越大越好,而是越“对问题”越好。一个很实用的做法,是先用四个问题把范围锁死:
1、谁用?研发、运维、一线客服、客户、供应商,还是某个业务线?“小建议:把目标写成“TopN问题清单 + 验收阈值”。例如“Top50高频问题准确率≥80%”。这样做评估与迭代都更有抓手。
很多企业做知识库时只盯着“文档”,但真正的价值常常藏在更深处:老师傅的经验、团队默认的习惯、系统里散落的数据。
| 类型 | 典型例子 | 难点 | 建议入库方式 |
|---|---|---|---|
| 显性知识 | 手册、FAQ、制度、架构文档、复盘、会议纪要 | 版本混乱、过期、缺少责任人 | 文档型 + 元数据;高频问题补Q&A |
| 隐性知识 | 排障直觉、经验诀窍、评审判断标准 | 难以写清、很依赖语境 | 案例复盘模板化;用“现象-原因-处理-验证”固化 |
| 嵌入式知识 | 流程习惯、系统配置、规则引擎、表单字段含义 | 散落在系统与配置中 | 把“规则+例外+截图”整理成条目;必要时接API实时查询 |
一句话总结:先把显性知识做成“可检索、可追溯”,再逐步把隐性与嵌入式知识结构化,不要一上来就追求“全公司知识宇宙”。
下面把“知识库构建指南”里的方法,结合企业RAG落地经验,整理成更适合公众号阅读的一套十步法。每一步都尽量给出“做到什么程度算及格”。
输出《范围说明》《指标与验收口径》。把“不能回答什么”写清楚。
至少三层:业务域/系统域 → 流程/模块 → 最小可复用条目,并定义元数据字段。
发布模板、命名规则、质量红线。SOP建议每步配图并写“验证/回滚”。
去重、去过期、补负责人。统一成可维护的主格式(很多团队用Word/Markdown)。
手册/规范走文档型;TopN高频问题走Q&A型。两者通常要结合。
一段只讲一个主题/动作;保留必要上下文;绑定分类、版本、适用范围与Owner。
把“系统旋钮”锁起来:召回、父子分块、重排由管理员统一管控,先把内容做好。
信息分级、引用来源、置信度声明与兜底策略,让回答“可核对”。
离线评测集 + 线上指标。对TopN问题做回归测试,防止“改一处坏一片”。
显式反馈 + 隐式反馈 + 周期复盘。让知识库成为持续演进的资产。
企业资料的真实面貌通常是:格式多、结构乱、扫描件多、表格多、还有大量截图。把“数据处理”当成知识库的地基,地基没打好,后面再高级的检索与模型都救不回来。
推荐做法:先对文档做分类,再走不同处理管线:可编辑文档(Word/Markdown)走结构解析;扫描PDF走OCR;表格单独结构化;图片提取为附件并与段落绑定。
如果你在用知识库平台(如Dify)构建RAG,它通常提供“提取器 + 分块器 + 知识库节点”的流水线式能力,并支持图片作为分段附件、甚至多模态检索(文本+图片一起向量化)。
检索增强的第一性原理很简单:你问的问题,系统要先把最相关的那几段原文找出来。问题是,企业文档的“相关”往往不是一句话能解决的,它需要完整步骤、完整条款、完整上下文。
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 固定长度分块 | 实现简单、参数化 | 破坏语义边界,易漏步骤 | 结构弱、内容短且均匀的文本 |
| 结构化分块 | 保留章节/小节/步骤完整性 | 需要解析文档结构 | 手册、规范、流程、SOP |
| 父子分块(Parent-Child) | 匹配更准、上下文更全 | 索引与检索更复杂 | 条款密集、步骤密集、需要引用依据的场景 |
Owner 负责内容;Reviewer 负责审核;Admin 管系统配置与权限。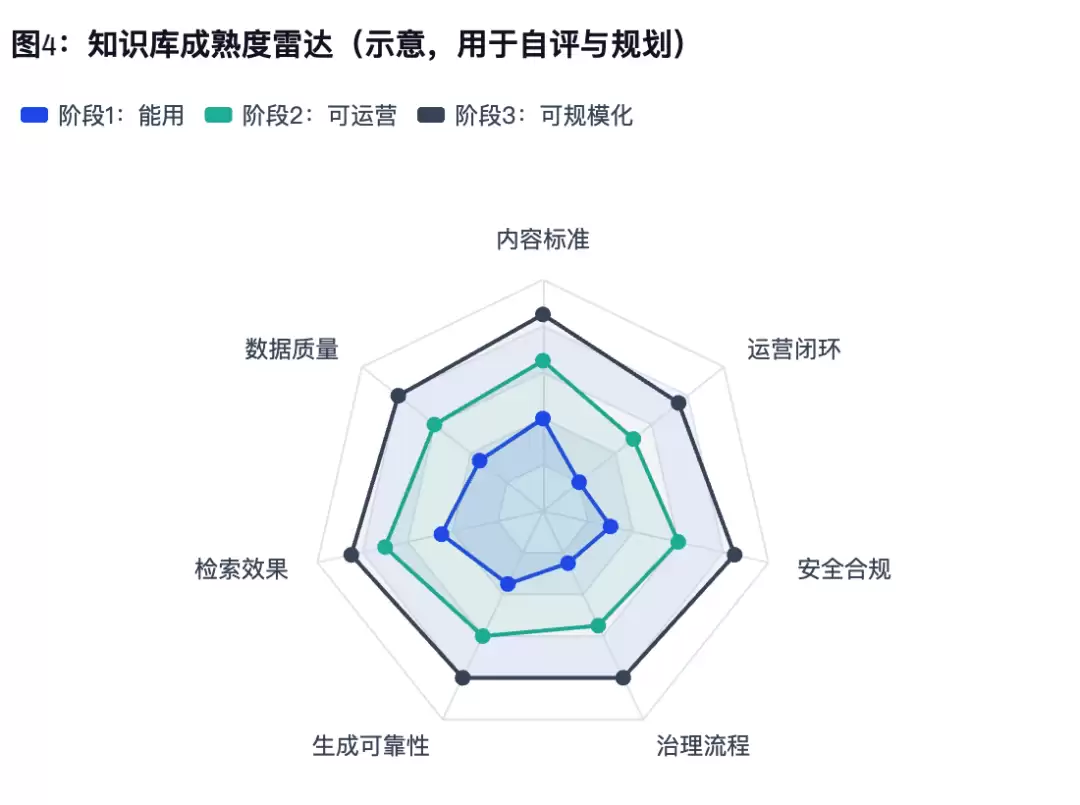
读法:从左到右不是“越高越先进”,而是看你最短的那块板。短板通常优先补:内容标准与数据质量,其次才是模型与参数。
| 阶段 | 目标 | 关键产出 | 验收信号 |
|---|---|---|---|
| 第0阶段(1-2周) | 范围清晰 | TopN问题清单、内容模板、信息架构 | 所有人对“做/不做”一致 |
| 第1阶段(2-4周) | MVP可用 | 核心文档入库、分块策略、基础问答 | TopN问题可稳定命中 |
| 第2阶段(1-2月) | 可运营 | 评测集、指标面板、反馈入口、治理流程 | 问题能定位、能追溯、能闭环 |
| 第3阶段(持续) | 可规模化 | 多知识库分域、领域Embedding、自动化流水线 | 新增业务线复用成本低 |
你可以直接复用的三份模板:
• 《知识库范围说明》:覆盖领域、排除项、风险等级、目标用户。
• 《内容规范》:FAQ/SOP/规范/复盘四类模板 + 命名规则 + 质量红线。
• 《评测与验收》:TopN问题集、指标定义、回归测试流程、门禁策略。

添加微信请备注:企业+职业+昵称
往期热门文章:
五大热门AI Agent 框架
大模型应用分析:腾讯ChatBI提高查询准确性的方法
如何简单计算LLM推理和训练所需的GPU资源
RAG优化策略总结
大白话讲清楚GPT嵌入(Embedding)的基本原理
探索AI大模型(LLM)减少幻觉的三种策略
发现AI领域的创业IDEA,探索ProductHunt的AI创意潮流
如何集成开源DATA+AI项目,落地企业智能化BI
用GenAI重新定义BI,Databricks推出AI/BI数据智能平台
高星、开源!Github上几个开箱即用的RAG项目
让AI Agent像团队一样协作的开源架构CrewAI
从NL2SQL到Data Agent:AI数据分析的演化和实例
拆解多基于LangGraph的多Agent项目设计和技术细节超越文本检索:Graph RAG如何变革LLM内容生成
超越文本检索:Graph RAG如何变革LLM内容生成
RAG总结,分块Chuck的策略和实现
十大零代码AI Agent开发平台