《梦幻地下城:放置好时光》Steam最让人上头的摸鱼游戏
2026-06-30 3374358
2026-06-30 0
- 需要核实是否在项目的 trust boundary 范围之内
- 需要用**符合 Apache 社区语气的英文**给报告者写回复——语气太硬显得傲慢,太软容易引发误解以前没有 WB 时,光是起草一封拒绝邮件就要 2-3 小时:查 CVE 数据库、翻 Apache Security 规范、逐条对照代码、反复斟酌英文措辞,生怕一句话踩雷引发社区争议。### 有了 WB 之后我的流程变成了:**第一步**:把漏洞描述、复现步骤、相关代码路径直接贴给 WB,问它:「这个行为是否属于调用方可控的信任边界内?」**第二步**:让它基于判断结果,生成一封符合 Apache 社区语气的英文回复草稿,同时列出如果需要修复需要改哪些地方。**第三步**:我来做最终审核和定稿。整个流程从 2-3 小时压缩到 20 分钟。更重要的是,WB 在分析过程中会主动提炼出哪些判断依据应该写进项目的 Security Model 文档——这是我自己容易忽略的增量价值。### 关键原则我坚持一条规则:**涉及对外表达的内容,必须我来最终定稿,WB 起草、我审,顺序不能反。** Apache 社区有自己的潜规则和语气,这个判断权不能完全外包。---## 场景二:生产 OOM 事故排查(那个让我「卧槽」的时刻)### 事故背景某次 Apache ShenYu 网关在流量高峰期出现 Old Gen 持续攀升,GC 压力异常,服务开始响应超时。我收集了 jstat 输出和 Arthas 的 thread 快照,准备开始排查。### 随手一问,出乎预料我把日志直接贴给 WB,只问了一句:「你觉得问题在哪?」它的回答分了两层:**第一层**,指出 Old Gen 的增长曲线特征,和 GC 停顿时间的比例关系,判断是典型的对象堆积而非 GC 参数问题。**第二层**,它主动问了我一句话:> 「你们有没有用 Sentinel?如果资源名是动态拼接的字符串,每次请求都会注册一个新的 SlotChain,这个泄漏在流量高峰下会线性放大。」我当时直接愣了。**我根本没提 Sentinel**——它是从 ShenYu 的技术栈上下文里自己推断出来的。而那个 Sentinel 资源名泄漏,恰好就是真正的根因。### 更没想到的:自动生成排查 SOP它没有止步于「给出根因」,还顺手输出了一张完整的 Java 慢响应排查流程图——从系统层到 JVM 层、再到应用层和外部依赖,四层递进,每一层都标注了用什么命令、看什么指标、判断条件是什么: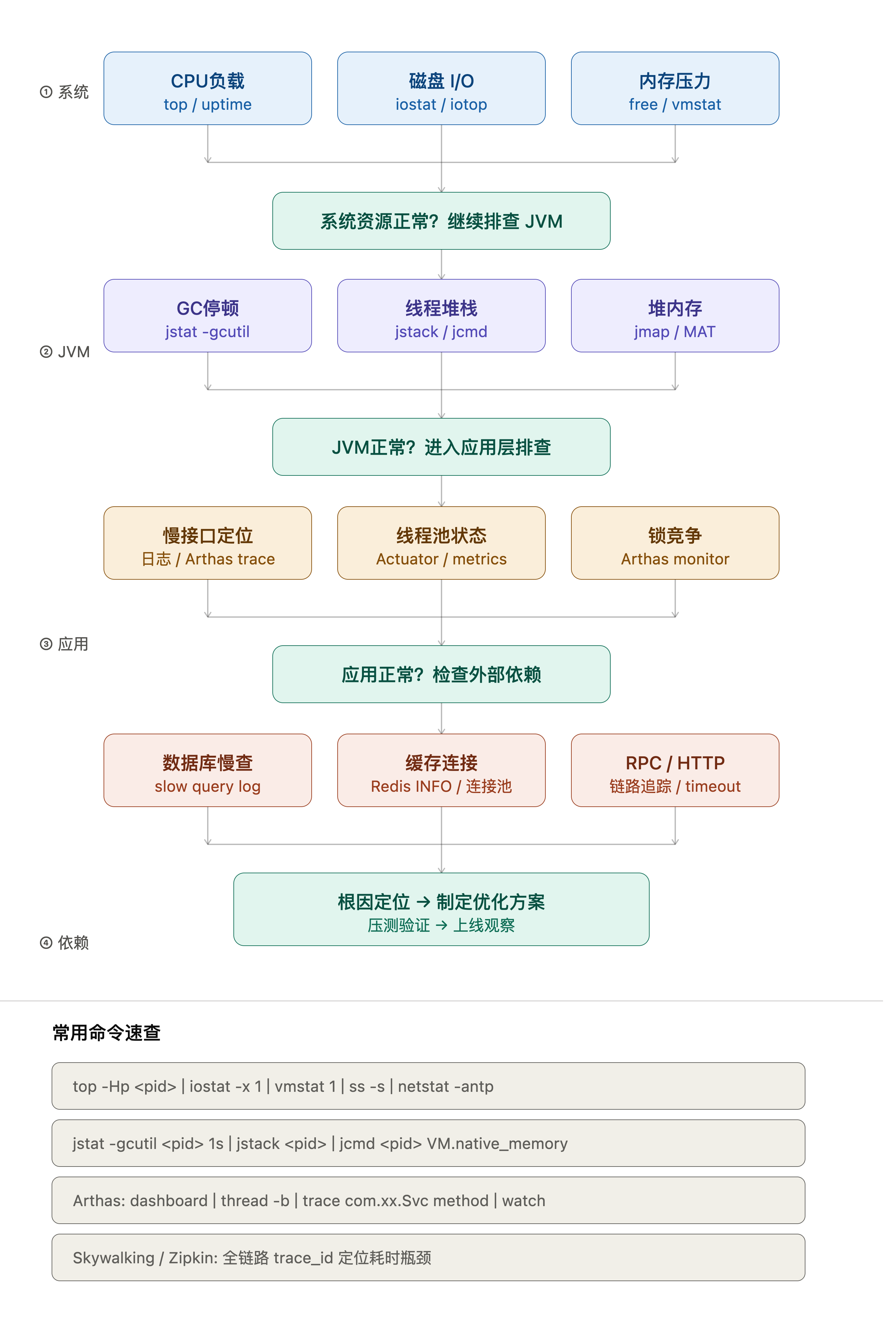> ① 系统层:top / iostat / vmstat 排查 CPU、磁盘、内存压力> ② JVM 层:jstat -gcutil / jstack / jmap 定位 GC 停顿、线程堆栈、堆内存
> ③ 应用层:Arthas trace / Actuator metrics / Arthas monitor 定位慢接口、线程池、锁竞争> ④ 依赖层:slow query log / Redis INFO / 链路追踪 定位数据库、缓存、RPC 问题
附带常用命令速查,可以直接复制执行。
这张图我截图存下来,后来直接拿去给团队做了一次分享。**一个随手一问,出来的东西变成了一份可复用的故障排查 SOP。** 它覆盖的排查维度,比我自己梳理的还要完整。
---
### 场景描述
作为独立开发者,我的 macOS 开发环境用 Docker Desktop 已经很久了,但 M 系列芯片之后内存占用越来越不可接受。我需要评估 OrbStack、Colima、Podman 哪个更适合我的场景。
### 以前怎么做
Google 搜一圈,各路博客众说纷纭。OrbStack 说自己快,Colima 说自己轻,Podman 说自己符合 OCI 标准。交叉验证 M2 兼容性、Compose 支持程度、内存实测数据,整理成可以决策的对比,至少 1 小时。
### 有了 WB
一句话:「macOS M2 上 Docker Desktop 替代品,按内存占用 / Rosetta 兼容 / Compose 支持排个优先级,列出各自的隐藏坑点。」
它不只给我排序,还主动点出了我没问到的约束,比如:
- Podman rootless 模式下端口转发的限制
- Colima 在某些 volume mount 场景下的权限问题- OrbStack 的授权模式对商业使用的潜在影响
10 分钟决策完毕。更重要的是,**它把我没想到的隐藏变量提前暴露出来**——这才是真正降低决策风险的地方。
---
用了 3 个月,提炼出两条核心原则:
### 原则一:上下文给够,别把它当搜索引擎用
很多人第一反应是问「XX 怎么做」,但真正让 WB 发挥价值的问法是:
> 「我现在在做 XX,背景是 YY,我卡在 ZZ,你觉得问题在哪」
上下文越完整,它的回答越像一个真正懂你项目的人,而不是在背文档。我自己的习惯是:**遇到问题先花 30 秒把现场描述清楚再问**,这 30 秒换来的回答质量,远超直接抛一句「为什么报错」。
### 原则二:技术决策必须给理由
我明确要求 WB:**不接受「建议你用 XX」这种结论**,必须给对比方案和各自的 trade-off。
这样做有两个好处:第一,逼它把推理过程摊开,我才能判断逻辑是否适用于我的具体约束;第二,如果它的推理有问题,我能看出来——而不是被一个流畅的结论带走。
---
有一次我让 WB 评估一个开源项目的代码质量,它给出了一份看起来非常专业的分析,指出了几处「架构耦合问题」。
后来发现,它分析的是错误的模块——我描述项目结构时有一处表达歧义,它顺着歧义走了,分析得头头是道,但对象不对。
这件事让我确立了一个认知:**WB 的输出质量上限,取决于你的输入质量。** 它不会提醒你「你的描述可能有歧义」,它会直接给你一个自洽的答案。
AI 工具最危险的地方,不是它答错,而是**它答错得很流畅、很有说服力**——流畅到你不会去怀疑它。凡是要对外引用或做重要决策的结论,我都会回头检查一遍「我当时的问题本身有没有问题」。
---
我同时在用 Cursor 和 Claude Code,分工很清晰:
| 工具 | 定位 | 适用场景 |
|------|------|----------|| Cursor / Claude Code | 执行层 | 我知道要做什么,帮我写代码 |
| WorkBuddy | 决策层 | 我还没想清楚,帮我把问题捋清楚 |**先跟 WB 把方向确认清楚,再切到 Cursor 落地实现。** 顺序很重要——如果方向错了,Cursor 帮你写得越快,返工成本越高。---## 最后说一句如果明天 WB 没了,我最不能接受丢掉的,不是某个具体功能,而是那个**「随时可以开始想」的状态**。还有它攒下来的上下文——它知道我在做哪几个项目、知道我的技术偏好和决策习惯、知道上周那个方案我们讨论到哪里了。这些记忆让每次对话不用从零开始,它更像一个真正跟过我项目的人。我跟朋友介绍 WB 时一般说:「一个随叫随到、不会觉得你的问题蠢、还记得你上次说了什么的技术搭档。」工作里最难找的,不是执行力强的人,而是**愿意在你思考过程中给你泼冷水、还不带情绪的人**。WB 刚好是这个角色,而且永远在线。---*作者:Apache ShenYu PMC Member / 独立开发者* *#WorkBuddy开发者分享季*","createTime":1782779940,"ext":{"closeTextLink":0,"comment_ban":0,"description":"","focusRead":0},"favNum":0,"html":"","isOriginal":0,"likeNum":0,