高端赛事日转播海报
2026-07-01 3374667
2026-07-01 0
上一篇讲了复制集的拓扑:一个 Primary 写、多个 Secondary 备。但留了个关键问题没回答:Secondary 到底是怎么「拿到」Primary 的数据的。是 Primary 把每个文档推过去,还是 Secondary 主动拉?
答案是后者,而且拉的不是文档本身,而是操作(oplog)。理解 oplog,才能理解复制的延迟从哪来、为什么新加入的节点要做全量初始化、以及为什么 Secondary 落后太多会「掉队」。这篇就讲清楚 oplog 这个复制的真正载体。
Oplog(Operation Log)是 Primary 上一个特殊的集合 local.oplog.rs,它记录 Primary 上发生的每一个写操作。Secondary 通过**长轮询(long polling / tailing)**从 Primary 拉取 oplog,在本地重放,从而保持数据同步。
复制链路的完整形态:
关键认知:复制是异步的、基于操作日志的。Secondary 不是实时镜像 Primary,而是「追」oplog。这就天然会有延迟——下一篇专门讲复制延迟。

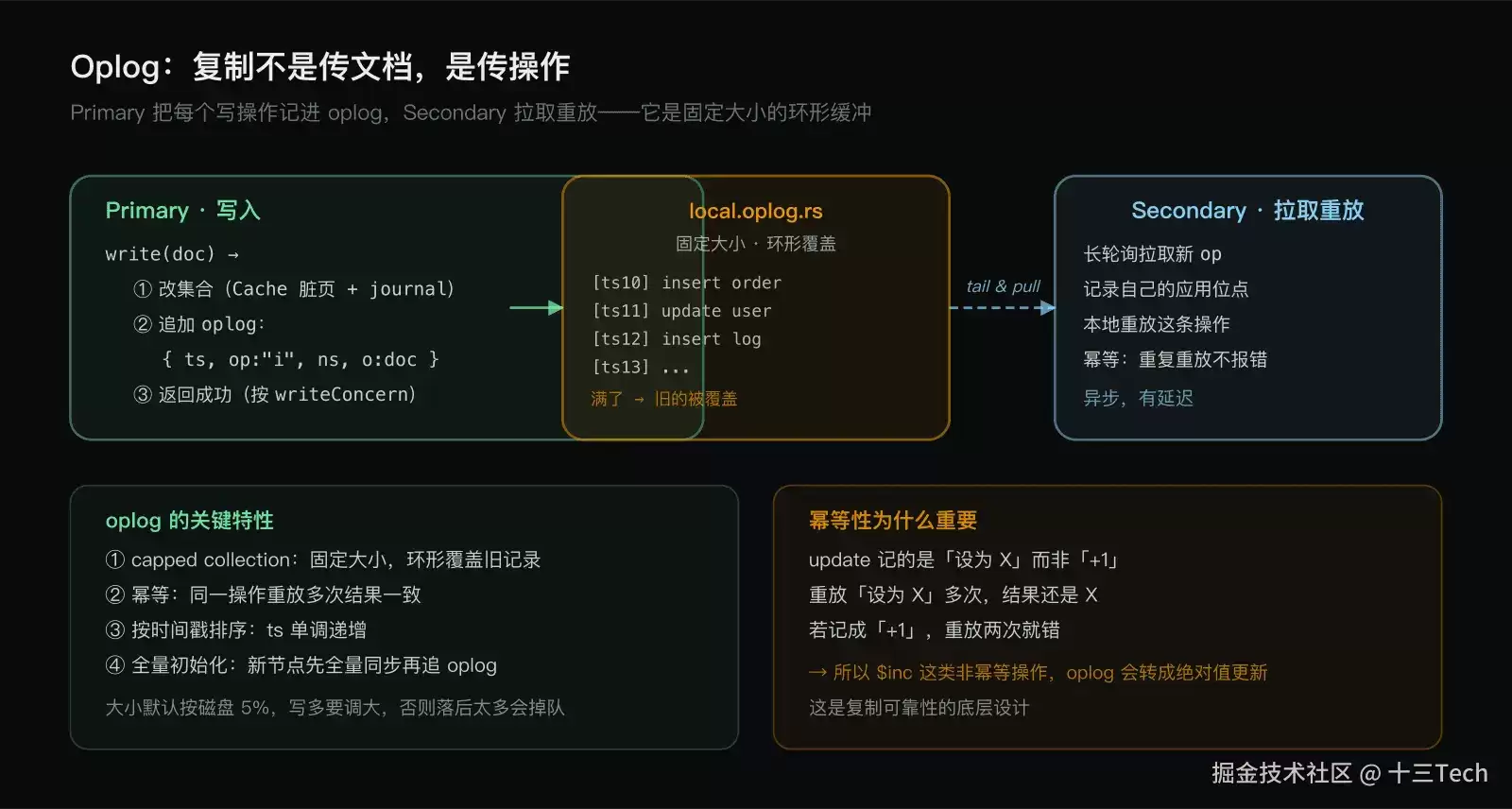
Oplog 是一个 capped collection(固定大小集合),大小固定(WiredTiger 默认按空闲磁盘空间的 5%,下限 990MB、上限 50GB)。它像一个环形缓冲:写满了,最旧的记录会被新的覆盖。
这个设计的好处是 oplog 不会无限增长。但带来一个重要后果:如果 Secondary 落后太多,落后到要拉的 oplog 已经被覆盖了,它就没法靠拉 oplog 追上。这时 Secondary 必须全量重新初始化——从 Primary 完整拷贝一遍数据,再开始追 oplog。全量初始化是个重操作,大集合上很慢。
所以 oplog 大小要和写入速率匹配:写入越快、Secondary 可能离线越久,oplog 就要越大。监控 oplog 的「时间窗口」(最早记录到最新记录的时间跨度),能判断 Secondary 能容忍多长时间的离线。
Oplog 的每条记录是一个操作,结构大致是:
复制代码{
ts: Timestamp, // 操作时间戳,单调递增
op: "i" | "u" | "d", // insert / update / delete
ns: "db.collection", // 命名空间
o: { ... } // 操作内容
}
幂等性是 oplog 设计的关键。所谓幂等,就是同一条操作重放多次,结果和重放一次一样。这一点对复制必不可少,因为 Secondary 在网络抖动、重试、崩溃恢复时,可能重放同一条 oplog。
为了保证幂等,oplog 记录 update 时,会转成绝对值更新而不是相对更新。比如应用执行 {$inc: {count: 1}}(count 加 1),oplog 记的不是「count 加 1」,而是算出更新后的绝对值,记成「count 设为 X」。这样 Secondary 重放时是「设为 X」,无论重放几次结果都对。
这个设计牺牲了一点灵活性(oplog 要记录完整的新值),换来了复制的可靠性。理解了幂等性,就理解了为什么复制是可靠的、不怕重试的。
一个全新的 Secondary 加入复制集时,本地没有数据,光靠拉 oplog 不行(oplog 只记录增量)。它需要全量初始化(initial sync):
全量初始化在大集合上很慢(要拷所有数据),期间会增加 Primary 的负载。所以加节点要错峰,避免在高峰期拉数据。也有一些优化手段,比如从已有的 Secondary(而不是 Primary)拷贝,分摊负载。
oplog 占用不算在业务数据里。oplog 在 local 数据库,是独立的。但它确实占用磁盘,规划容量时要算进去。
oplog 大小可以在线调整。用 replSetResizeOplog 可以在不重启的情况下扩大或缩小 oplog(下限 990MB)。早期没估准不必重做部署,但调整仍属运维操作,规划时建议一次估够。
oplog 的写入也是写入。Primary 每个写操作除了改集合,还要追加 oplog,所以复制集的 Primary 写入开销比单机大(多了 oplog 追加)。
Secondary 的延迟本质是 oplog 追不上。下一章会展开,但根源就是 oplog 产生的速度 vs Secondary 重放的速度。
下一篇讲复制延迟,看清 Secondary 为什么会跟不上。