梦幻西游175级盘丝洞装备搭配
2026-07-01 3375293
2026-07-01 0
编者按:大模型推理的性能瓶颈往往隐藏在 Prefill 与 Decode 的交错调度、多卡间的数据同步、以及 Continuous Batch 的动态编排之中——而要真正“看见”这些问题,离不开请求级别的可观测能力。在沐“蜥”芯生,开源共创——SGLang 技术交流 MeetUp 上,龙蜥社区 SGLang 开发者苏峰和龙蜥社区智算联盟委员常怀鑫分享了《从全链路可观测到智能分析:AI 性能分析范式的演进与实践》的主题演讲。两位嘉宾在演讲中回顾了其在龙蜥社区孵化并向上游贡献的 SGLang Tracing 可观测性建设历程,并结合具体案例探讨如何利用 AI Agent 实现 SGLang 框架的性能优化。以下为本次演讲全文:
当前推理引擎在部署时会面临很多性能问题——不管是线上服务还是部署新模型、研发新实例,我们经常遇到这样的情况:测试指标偏高、请求中止或超时;又或者 CPU 和 GPU 资源没有打满,但吞吐再也提升不上去。这些都是典型的性能问题。

要分析上述问题,完善的可观测性是基石。在此之前,SGLang 有三类观测手段:
第一种是日志。 一般我们用日志来看整体的健康度,但它的输出比较碎片化,而且不是所有信息都会输出,所以用日志来分析问题通常需要做大量的后处理。
第二种是 Metrics。 一般用于线上健康度观测,呈现形式类似于折线图或直方图,是聚合的统计数字。它偏向宏观观测,会丢失请求的个体信息,也没有办法把请求的执行过程关联起来。
第三种是 Torch Profiler。 这应该是我们离线分析性能问题最常用的手段,非常好用。但最大的问题是它非常重——采集几十秒就会产生 GB 级的数据,没办法长时间采集。对于偶发性问题,采集到它的概率其实不大。另外一个缺点是它不区分请求,以函数调用栈的方式呈现,不管 batch 里有多少请求,我们看到的其实就是一次 batch 里一个 forward 的结果。
但我们平时最直观想看到的是:到底是哪个请求慢了?它在哪个阶段变慢了?我们理想的可观测体系,缺的就是对请求的 Tracing 能力。而在一些比较成熟的互联网业务中,Tracing 基本是必要功能。
Tracing 的本质是建立全链路关联。一方面,它让我们看清单个请求内部各阶段的执行顺序和动作;另一方面,针对大模型场景中因请求随机到达导致的调度打断问题,Tracing 还需进一步延伸至请求间关系的观测。这意味着,我们不仅要关注单点性能,更要深入分析请求之间是如何互相影响的。
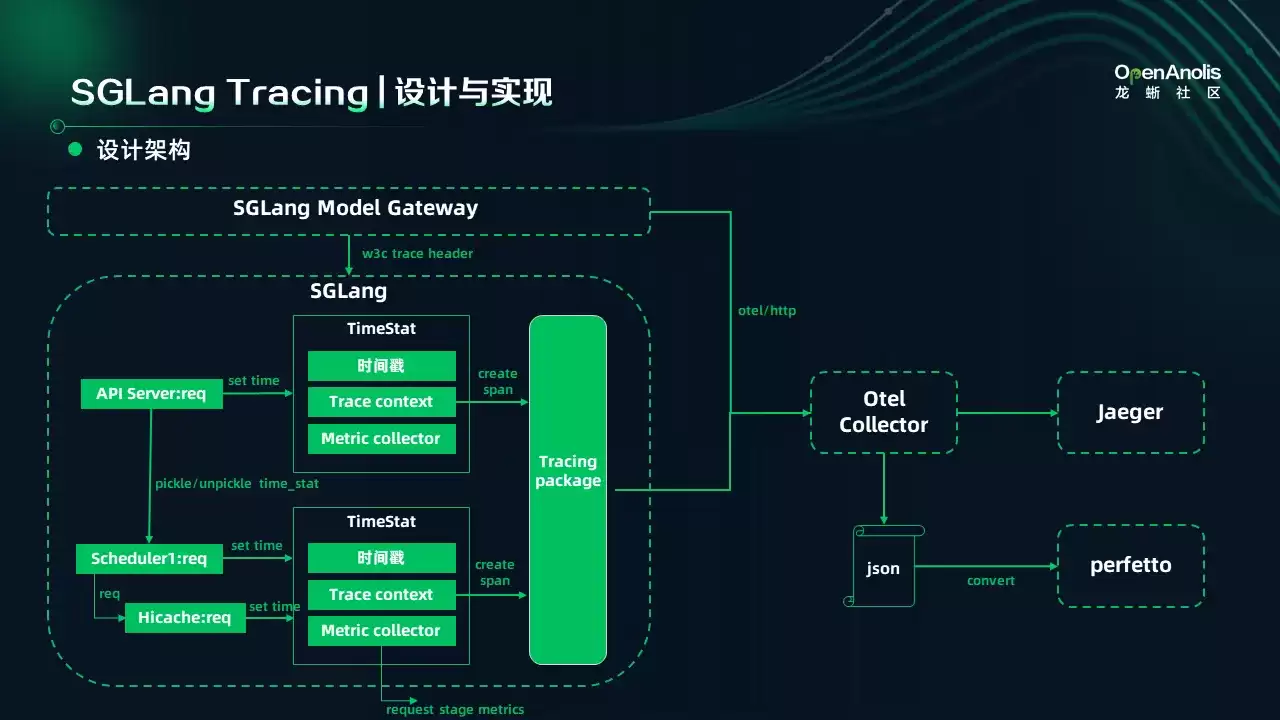
对于 SGLang 来说,实现这样一套能力有三个挑战:
第一,多请求并发。 它不同于互联网的多协程方式。OpenTelemetry 原生支持多协程自动管理 Tracing 上下文,在协程切换调度时自动保存和恢复上下文。但在 SGLang 里,多请求并发是以 Batch 的形式一起执行的,所以需要我们手动管理每个请求的 Tracing 上下文。
第二,Continuous Batch 机制。 每一轮 Batch 可能有新请求加入,也可能有请求终止,所以我们要跟踪的点分散在整个代码仓库中,不好管理。
第三,并发方式多样。 我们有 TP、DP、PP、PD 等并行方式,除了想看请求的细粒度执行过程,还想看并行执行的过程。
SGLang Tracing 基于 OpenTelemetry 官方 API 构建,通过封装一层 Tracing Package 进行上下文管理,并对接成熟的生态体系。数据可导出至 OpenTelemetry Collector,进而接入 Jaeger 或 Zipkin 等前端可视化工具。
针对大模型推理场景,SGLang 还提供了文件导出与离线分析方案。虽然原生支持单请求观测,但通过离线脚本将数据转换为 Perfetto 格式,用户可在单一视图中全局查看所有请求,从而直观洞察请求间的相互影响。
SGLang Tracing 的核心实现集中于 TimeStats 类。社区对时间戳采集机制进行了重构,将所有相关逻辑统一收敛至该类中,使其能够集中支撑日志、Metrics 和 Tracing 三大可观测性能力。
在 TimeStats 内部,系统负责创建 Tracing Context。当某个执行阶段完成时,通过回溯前序时间戳即可生成 Span,同时实现了从 Tokenizer 到 Scheduler 的上下文转移。这种集中式设计的优势在于解耦与低侵入性:只要宏观执行阶段和时间戳类型保持不变,无论 SGLang 主体代码如何重构,Tracing 模块均无需修改;且在功能关闭时,对主推理流程完全无感。
我们设计了三层的 Span 架构来应对上述所说的挑战:
这个三层 Span 结构还允许上层系统把 Tracing Context 传播下来,这样可以把 SGLang 的 Tracing 和上层系统(如 Dynamo 调用 SGLang 时生成的 Span)关联在一起。
单请求视图: 通过导出到 Jaeger,可以看到单个请求的完整执行过程,包括各个阶段的 Span 和时间信息。
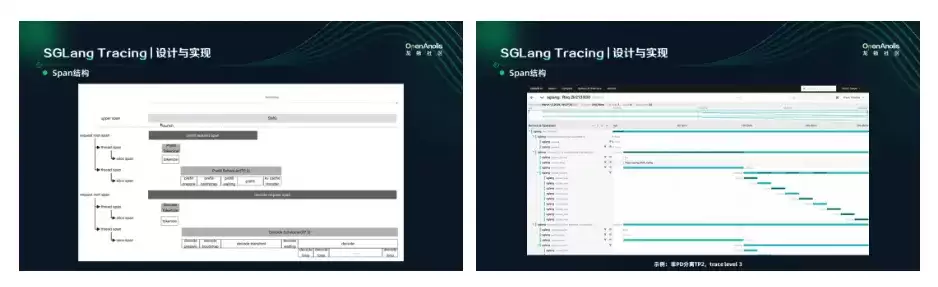
多请求视图: 通过离线脚本转换成 Perfetto 格式,呈现两层结构——第一层是 SGLang 的各个线程,每个线程底下把所有请求的执行 Span 排列出来,并通过 Link 的方式串联,从而得到所有请求的执行流。
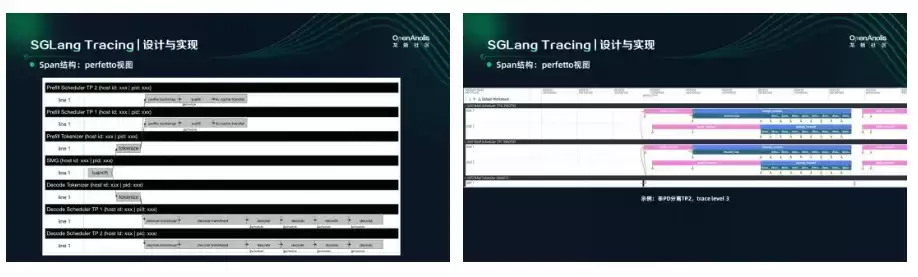
实际效果展示中,我们用非 PD 分离部署,以 TP 方式部署,包含三个进程:一个 Tokenizer 和两个 TP Rank。这里两个请求并发执行,在每个线程底下可以看到两行,通过统一的时间轴可以看到两个请求是怎么一起执行的——比如 Prefill 是分开 forward 的,而 Decode 是一起 forward 的。
随着 AI 技术的演进与智能体浪潮的兴起,可观测性已成为性能分析领域不可或缺的基础支撑。若以“手”与“脑”作比,可观测体系如同灵巧的“手”,负责数据采集与呈现;而 Agent 则扮演着“大脑”的角色,主导分析与决策。基于这一可观测基础,我们开展了一系列性能分析与优化实践。后续,基于 Agent 的实践 skill 预计会上线到龙蜥社区,敬请期待。 接下来,将通过四个具体案例——包含三个性能分析案例与一个性能优化案例——为大家分享我们的探索与经验。

在实际工作中,我们反复面临一项核心任务:在特定配置下(如 DeepSeek V4 部署于 H20),寻找满足 SLA 约束的最优 QPS 及其对应参数。若完全依赖人工,这一过程极为耗时——工程师需反复启停服务、手动调整 QPS 并凭经验猜测,单次测试往往耗时 20-30 分钟,且全程需要深度介入。
如今,通过引入自动化技巧并将测试方法固化,Agent 已能在十余分钟内快速定位特定配置下的 SLA 最优解。例如,在 H20 平台上以 TP8 配置运行 DeepSeek V4 时,Agent 已成功输出相应的测试结果。
但在实践中我们也发现,直接依赖 Skill 或 Agent 执行仍存在不确定性。例如对于 max_running_requests、QPS 等具体参数,Agent 的初始理解可能与工程师的精确意图存在偏差。因此,当前更高效的模式是“人机协同”:先通过数轮交互对齐认知,将确定性逻辑固化为脚本,再由 Agent Skill 串联剩余流程。这种方式既保留了人的精准判断,又充分发挥了 Agent 的执行效率,最终实现事半功倍的效果。
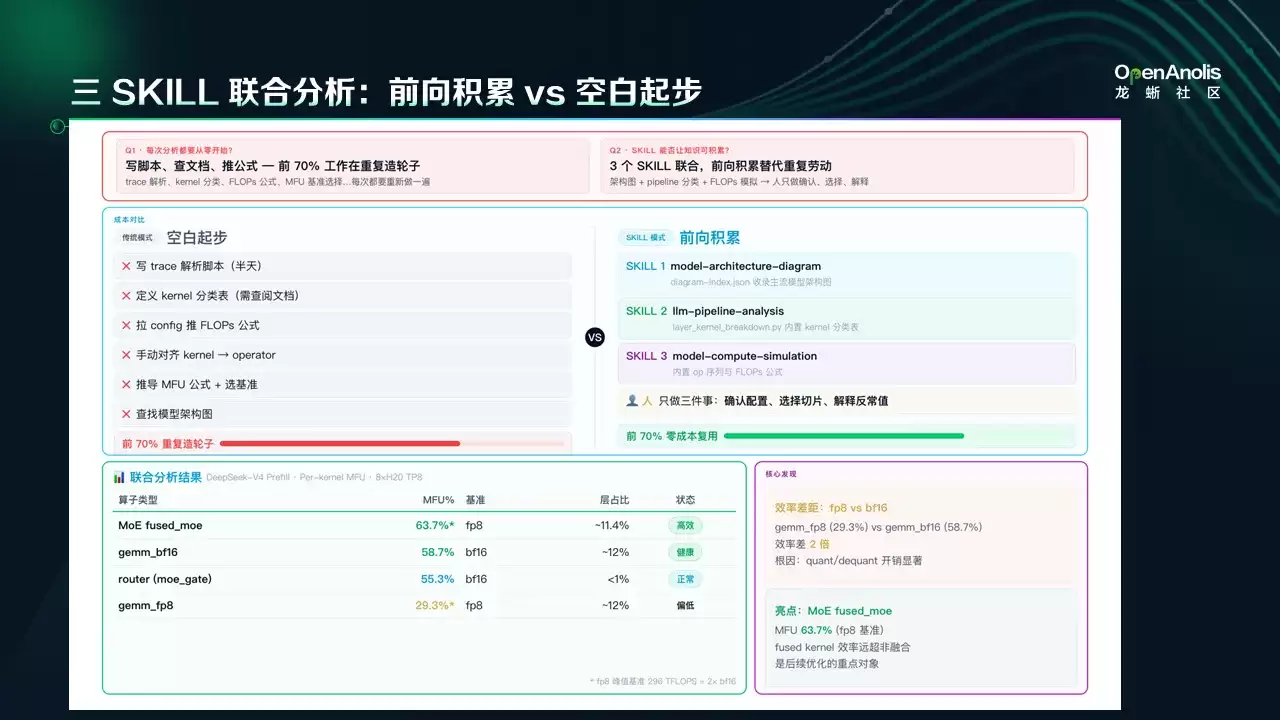
这个实践的场景是:在实际测试运行过程中,我们想知道当前的性能瓶颈在哪里,不同算子有没有达到比较好的 MFU 和资源利用率。
在应用这些 Skill 之前,这一过程主要依赖人工操作。工程师需手动处理海量数据,并结合模型结构进行复杂分析,不仅流程繁琐,且难以沉淀和复用经验。借助 Agent 智能体,我们通过协同调用以下三个 Skill 来高效完成这一任务:
1、Model Architecture Skill: 主要展示具体模型的模型结构详情,数据来源于上游的开源项目。
2、Pipeline Analyzer Skill: 从 Torch Profiler 数据中逐步分析——选择合适的 Profiler Batch、Profiler Layer,并对 Layer 里的算子做具体分析。
3、Model Compute Simulation Skill: 分析 Layer 内部的数据流。结合数据流和基本知识,这个 Skill 可以计算出每个算子的实际输出张量类型以及大概的 MFU 估算。
三个 Skill 联合之后,输出结果有多个层次:模型结构、Torch Profiler Trace 中的 Batch 和 Layer 执行结果,以及算子的具体信息。在分析的 Case 中,对于 Fused MOE 算子,已经能看到主要算子的 MFU 执行情况,大模型也能给出一些自己的理解和判断。

我们经常面临这样的咨询问题:一个新模型能不能在特定的硬件平台(比如 H20)上跑起来?跑起来之后显存是否充足?
Prefill 阶段的显存占用一般大家不太担心,关键在于 Decode 阶段——需要比较高的 Batch Size 把核心算子的 MFU 撑起来。这时候显存有可能达到瓶颈,所以核心问题是:对于具体的输出模式,大概能达到多高的并发度?能不能达到比较好的 MFU?
容量估算 Skill 是做一些前置的评估工作。这个 Skill 首先采用了一些静态数据和动态数据相结合的方式,也提取了一些极限数据。它把显存使用分成核心几类:权重、KV Cache 使用、框架运行时的主要动态内存。有了这些划分之后,结合具体场景下每个 Token 或每个请求的显存占用情况,就能估算出在具体配置下大概能达到多少请求并发度。根据经验,在 H20 或其他卡上达到 200 或以上的并发度,就能达到比较好的使用效果。
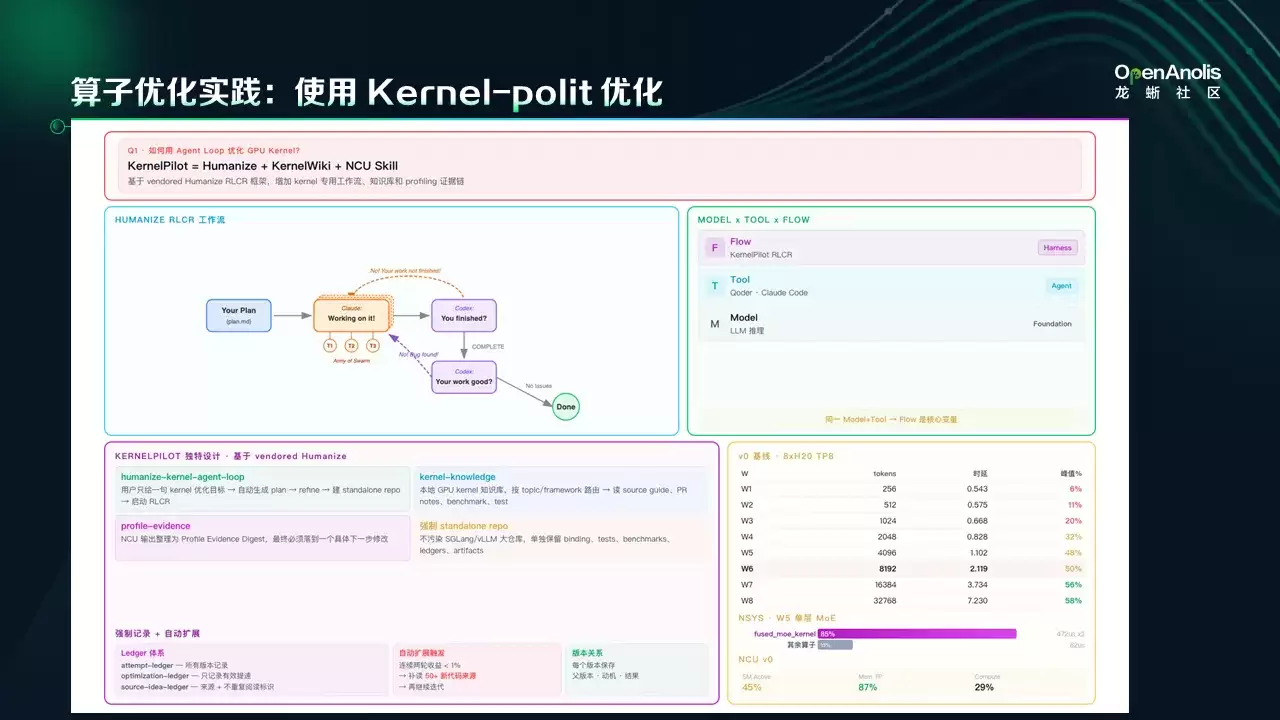
除了上述性能分析工作之外,我们也对算子的优化/调优进行了实践,采用了开源项目 Kernel-Pilot。与前述性能分析 Agent 不同,Kernel-Pilot 的独特之处在于其精心设计的三重架构:
1、Humanizer: 基于 Agent Flow 的架构,核心理念是做长时间运行或复杂任务时,直接用简单的 Flow 通常比较难达到好的结果,所以通过 Agent Loop 或 Multi-Agent 架构让任务自动长时间运行来达到比较好的优化效果。架构上用了三个 Agent:模型优化 Agent(使用 Claude)、Code Review Agent 和状态判断 Agent(后两者使用 Codex)。
2、Kernel Knowledge: 从以往的网页等来源提取的 Kernel 优化知识。
3、NCU Skill: 使用 NVIDIA Nsight Compute (NCU) 进行分析的能力。
此外,实践中特别强调了 Workload Set 的概念,即在优化前需明确定义工作负载。我们以 Fused MOE Kernel 为例,针对不同 Input Sequence Lengths 进行调优尝试。
最终效果显著:经过约三轮迭代,系统实现了最终优化。若仅使用简单单一 Flow,可能在第一轮即输出结果并停止;但得益于 Code Review 及其他 Codex Agent 的介入,流程继续深入迭代两轮,并结合 NCU 的分析数据发现了新的优化点。最终,通过对 MOE相关配置的调整,在不同 Workload 下平均提升了约 20% 的性能。
在当下进展与未来工作方面,目前 TP、DP、PP、PD 分离等场景基础 tracing 能力已顺利合入,近期重点完成了 SD/EPD 分离等架构支持,以及 PD 分离场景下 Mooncake backend Tracing 功能。当前正在进行的工作包括深化 KV Cache 在 L1-L3 间的数据传输跟踪、推进 eagle V2 版本的 PR Review,并针对大 Batch Size 下 OpenTelemetry 异步导出带来的性能开销问题进行优化,以避免影响主体流程的时间窗口;后续计划重点解决组件覆盖不全、Span 属性颗粒度粗及 Trace Level 设置随意等问题,系统性重构 Trace 配置,并开发后端直接导出 Perfetto 格式的功能,以替代现有的离线脚本转换方式,进一步提升可观测性的易用性与性能。
PPT获取链接:https://docs.openanolis.cn/document/detail/rpzigrnb
视频回放链接:https://openanolis.cn/video/1644028478456791807
—— 完 ——