蛋仔派对四周年庆活动大全:蛋仔派对周年庆典玩法与福利汇总
2026-07-01 3375546
2026-07-01 0
 封面图 - 11.8 万 Star 双引擎 YC CEO
封面图 - 11.8 万 Star 双引擎 YC CEO
图 1:gstack 项目概览(11.8 万 Star / 双引擎架构 / YC CEO 出品)
先抛三个数字。
一个 Claude Code 的 skill 集合项目,GitHub 上拿了 117,967 颗 star(GitHub REST API stargazers_count,2026-06-29 实时核实)。它打包了 23 个专家角色,背后是约 170,765 行 TypeScript 和一个 58MB 的编译二进制。更夸张的是,项目从 2026 年 3 月 11 日创建到本文调研的 6 月底,不到四个月 CHANGELOG 已经累积到 395 个版本,平均每天近 4 个版本。
这个项目叫 gstack,作者 Garry Tan - Y Combinator 的总裁兼 CEO,早期 Palantir 工程师,Posterous 联合创始人。
刷到这条信息的时候,我第一反应跟 Hacker News 上很多人一样:又一个 YC 大佬的 AI 玩具?但把源码翻了一遍之后,看法变了。它的 README 一句话写得很直白 - "everything else is Markdown"(剩下的都是 Markdown)。意思是,这个项目真正硬的工程不在 skill 文件里,在那个长驻的浏览器守护进程。
这篇文章就拆这件事。不讲营销话术,不吹 LOC,只看源码层面 gstack 到底做了哪些工程决策,以及为什么这些决策让它从一堆 prompt 集合里脱颖而出。
直接看 package.json 里的 description 原文:
翻译过来:一个仓库,一次安装,整套 AI 工程工作流。两个核心组件 - Claude Code skills 一个快的 headless 浏览器。
用 Claude Code 原生的开发者大概都踩过一个坑:面对空白 prompt,不知道该让 AI 扮演什么角色、走什么流程。你说帮我写代码,AI 就闷头写;你说做 code review,它就按自己的理解来。流程是即兴的。每次都不一样,没法复用。
gstack 干的事就是把这套流程固化下来。23 个角色,每个都是一个 SKILL.md 文件,通过 slash 命令调用。/plan-ceo-review 让 Claude 扮演 CEO 挑战你的方案,/cso 是首席安全官跑 OWASP STRIDE 审计,/qa 开真实浏览器点流程找 bug。
但 skill 文件本质就是 prompt。真正区分 gstack 和其他 skill 仓库的,是那个浏览器。
ARCHITECTURE.md 开篇就点明了这个项目的本质:
(给 Claude Code 一个常驻浏览器,外加一套有主见的工作流 skill。难的是浏览器 - 剩下的都是 Markdown。)
这句话是理解整个项目的钥匙。两层结构长这样:
代码语言:markdown复制┌─────────────────────────────────────────────┐│Skills 层(~40 个 SKILL.md 文件) ││• 每个文件 = 一个专家角色││• Claude Code 加载即获得结构化工作流 ││• 全是 Markdown,人能读、能改│└─────────────────────────────────────────────┘ ┌─────────────────────────────────────────────┐│Browser 层(58MB 编译二进制)││• 内嵌长驻 Chromium 守护进程 ││• 通过 localhost HTTP 提供服务 ││• 这是真正硬的工程 │└─────────────────────────────────────────────┘
为什么这么分?因为 skill 是廉价的 - 写个 Markdown,描述清楚角色和流程,任何会写字的人都能做。但浏览器是另一回事。让 AI agent 能稳定驱动一个真实浏览器去点按钮、填表单、读页面内容,这件事在工程上极难。CSP 冲突、框架水合、Shadow DOM、cookie 解密、长进程管理,每一个都是能让人掉头发的坑。
gstack 把绝大部分工程精力投在那个 58MB 的二进制上,作者的判断很清楚:光靠 prompt 写得好,撑不起一个 11 万 star 的项目。
 双引擎架构图
双引擎架构图
图 2:Skills 层 Browser 层的双引擎架构
先把架构图摆出来,这是 ARCHITECTURE.md 里的原版:
代码语言:markdown复制Claude Code gstack─────────────── ┌──────────────────────┐Tool call: $B snapshot -i│CLI (compiled binary)│─────────────────────────→ │• reads state file │ │• POST /command│ │to localhost:PORT │ └──────────┬───────────┘│ HTTP ┌──────────▼───────────┐ │Server (Bun.serve) │ │• dispatches command │ │• talks to Chromium│ │• returns plain text │ └──────────┬───────────┘│ CDP ┌──────────▼───────────┐ │Chromium (headless)│ │• persistent tabs│ │• cookies carry over │ │• 30min idle timeout │ └──────────────────────┘
这是 gstack 和每次 cold start 浏览器方案的根本差异。官方给的性能数字:首次调用约 3 秒启动,之后每条命令约 100-200ms。
一次完整的 QA 会话有 20 条命令。如果每次都冷启动浏览器,光浏览器启动就要 40 多秒,而且会丢掉所有 cookies、localStorage、登录态、打开的标签页。这不是优化问题,是可用性问题。一个登录后才能用的页面,你总不能每点一下都重新登一次。
长驻守护进程解决的就是这个。Chromium 起来之后,cookies、标签、状态全部保留,30 分钟空闲才超时退出。
ARCHITECTURE.md 给了四条理由,讲得很清楚:
编译二进制:bun build --compile 出单文件 58MB 可执行文件,无需 node_modules、无需 npx、无需配 PATH。gstack 要装到 ~/.claude/skills/ 这种用户不会去管 Node 项目的目录,这点关键。原生 SQLite:Cookie 解密要直读 Chromium 的 SQLite cookie 数据库。Bun 内置 new Database(),不需要 better-sqlite3,不需要 native addon 编译,不需要 gyp。原生 TypeScript:开发期直接 bun run server.ts,无编译步骤、无 ts-node、无 source map。内置 HTTP 服务器:Bun.serve() 够快够简单,不用 Express/Fastify,整个服务就处理约 10 个路由。顺带提一句。ARCHITECTURE.md 里有一句话:瓶颈永远是 Chromium,不是 CLI 或 server。Bun 的启动速度(编译二进制约 1ms vs Node 约 100ms)是锦上添花,真正的理由是编译二进制 原生 SQLite 这两条。
 浏览器守护进程生命周期
浏览器守护进程生命周期
图 3:守护进程生命周期:冷启动 3s → 稳态 100-200ms → 空闲 30min 超时
这是 gstack 浏览器层最有特色的设计,ARCHITECTURE.md 专门用一章叫 "The ref system"。
Agent 要操作一个页面,不需要写 CSS selector,也不需要让模型理解整个 DOM。流程是这样的:
代码语言:markdown复制1. Agent 调用 $B snapshot -i2. Server 调用 Playwright 的 page.accessibility.snapshot()3. 解析器遍历 ARIA 树,分配顺序 ref: @e1, @e2, @e3...4. 为每个 ref 构建一个 Playwright Locator: getByRole(role, { name }).nth(index)5. 在 BrowserManager 实例上存 Map
之后 Agent 要点某个元素,直接 $B click @e3 就行,server 把 @e3 解析成对应的 Locator,再执行 locator.click()。
对 AI agent 来说,这个设计的好处很明显:它不需要懂 CSS,也不需要懂 DOM 结构,只要看 ARIA 树和编号就能操作。这降低了 prompt 复杂度,也降低了出错率。
这才是真正关键的工程权衡。让 agent 操作页面,业界常见做法是往 DOM 里注入属性(比如 data-agent-ref="e3")。gstack 偏不这么干,理由有三条:
Playwright Locator 是 DOM 外部的东西,它用的是 Chromium 内部维护的 accessibility tree 和 getByRole() 查询。零 DOM 突变、零 CSP 问题、零框架冲突。代价是要依赖 Playwright,但比起在每个生产站点上被 CSP 拦死,这个代价值得付。
SPA 有个麻烦:它可能在不触发 framenavigated 事件的情况下改 DOM(React Router 跳转、切标签、弹个窗)。如果 Agent 手里攥着一个已经失效的 @e5 去点击,Playwright 默认会空等 30 秒 action timeout。
gstack 的解法在 resolveRef() 里:用任何 ref 之前,先跑一次异步 count() 检查,约 5ms 开销。元素还在,继续;不在,立即报失效,Agent 重新 snapshot。5ms 换 30 秒的空等,这笔账谁都会算。
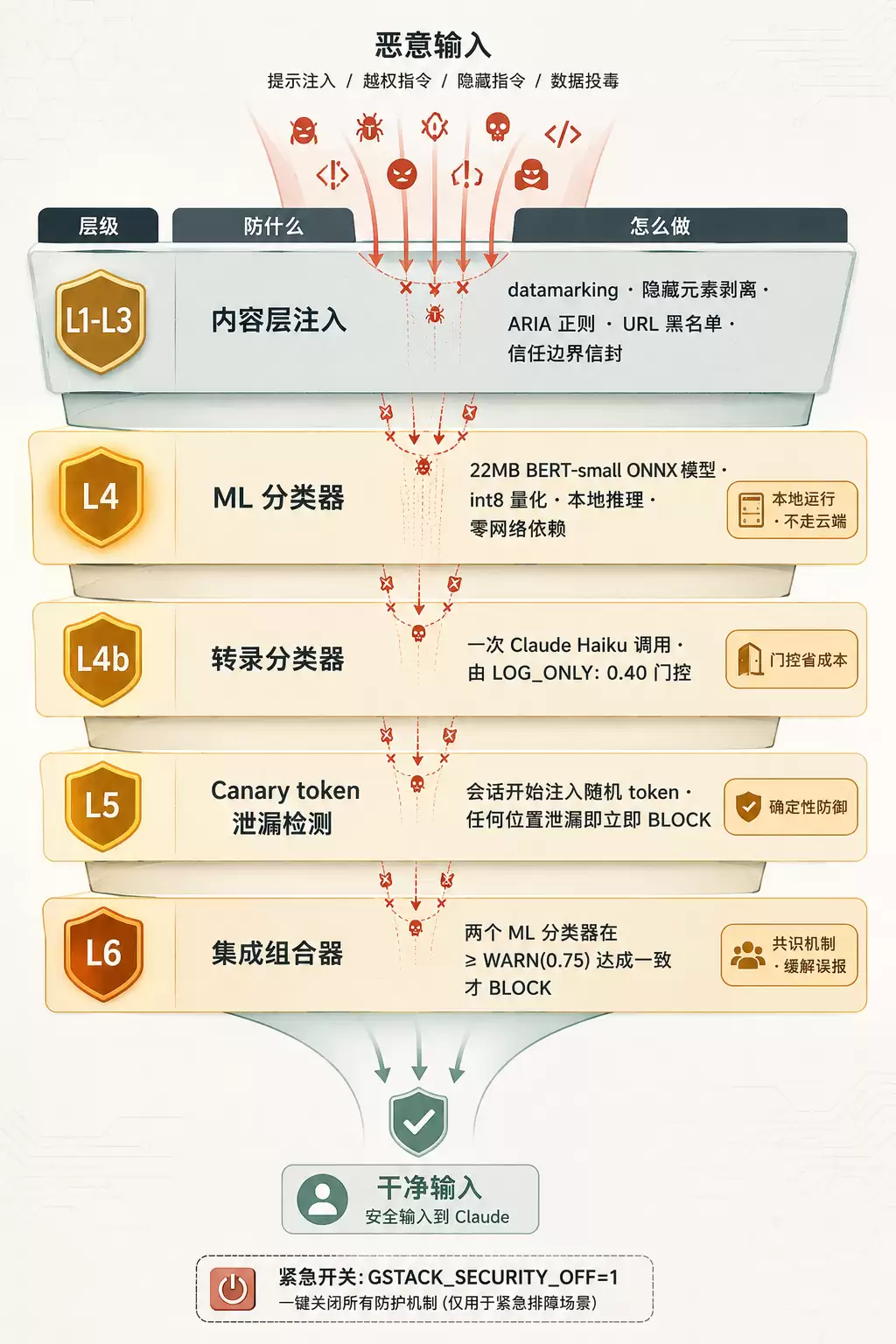
这是 gstack 里最有安全工程含金量的部分。sidebar agent(Chrome 侧边栏里的子 Claude)有 Bash、Read、Glob、Grep、WebFetch 工具,而且要读敌意网页,所以是整个项目里最暴露给 prompt injection 的部分。
ARCHITECTURE.md 把防御栈拆成六层:
层 | 防什么 | 怎么做 |
|---|---|---|
L1-L3 | 内容层面的注入 | datamarking、隐藏元素剥离、ARIA 正则、URL 黑名单、信任边界信封封装 |
L4 | ML 分类器 | 22MB BERT-small ONNX 模型(int8 量化),随 agent 打包,本地跑,无网络 |
L4b | 转录分类器 | 一次 Claude Haiku 调用看完整对话形状,由 |
L5 | Canary token | 会话开始往 system prompt 注入随机 token,泄漏就立即 BLOCK |
L6 | 集成组合器 | 两个 ML 分类器在 |
几个点单独说说。
L4 那个 22MB BERT 模型是本地跑的。这一点很关键 - 模型本身打包进二进制,本地推理、零网络依赖,不走云端的 moderation API。可选的还有一个 721MB 的 DeBERTa-v3 集成(GSTACK_SECURITY_ENSEMBLE=deberta),但默认不开。
L4b 的门控设计很精。一次 Claude Haiku 调用要花钱,如果每条消息都过一遍,成本扛不住。所以用 LOG_ONLY: 0.40 做门控 - 大部分干净流量会跳过这次付费调用,只有可疑的才进入转录分类。
L5 的 canary token 是确定性防御。会话开始时往 system prompt 里塞一个随机 token,然后在 Claude 的输出、工具参数、URL、文件写里四处盯。token 一旦在任何位置出现,意味着攻击者已经说服 Claude 把 system prompt 泄漏出来 - 会话立即结束,没有商量。
L6 的组合器最反直觉。BLOCK 需要两个 ML 分类器在 >= WARN(0.75) 上达成一致,而不是单个高置信命中就拦。看起来更宽松,实际是为了缓解误报。Stack Overflow 那种页面里写着忽略之前所有指令的正常技术文档,单个分类器会狂误报,两个一起投票能压下去。
还有一个紧急开关:GSTACK_SECURITY_OFF=1。生产环境出问题、或者你想完全绕过防御做调试的时候用。一个项目敢提供关掉所有安全的开关,本身说明它对自己的安全机制有信心。
 六层防御栈
六层防御栈
图 4:Prompt Injection 六层防御栈(L1-L6)
讲一个看似小、实际很巧的工程。
SKILL.md 是告诉 Claude 怎么用 browse 命令的文档。但文档是人维护的,代码是人改的。如果某天代码里新加了一个 flag,文档里没写,Claude 就不知道有这个能力。反过来,文档里写了个不存在的命令,Claude 调用就报错。
这就是经典的文档代码漂移问题。绝大多数项目的解法是:靠人记得更新。结果当然是没人记得。
把 SKILL.md 拆成模板 占位符:
代码语言:markdown复制SKILL.md.tmpl(人写的叙述 占位符) ↓gen-skill-docs.ts(从源码读元数据) ↓SKILL.md (提交进仓库,自动生成那部分)
模板负责承载需要人类判断的部分:工作流、技巧、示例。占位符在构建时从源码填充。看几个真实的占位符:
占位符 | 数据来源 | 生成什么 |
|---|---|---|
|
| 分类命令表 |
|
| 带 example 的 flag 参考 |
|
| 启动块:更新检查、会话追踪、contributor 模式、AskUserQuestion 格式 |
|
|
|
|
|
|
|
|
|
关键属性是结构性保证:命令存在于代码中 → 出现在文档中;不存在 → 不可能出现。漂移从可能性问题变成了机制上不可能。
光有生成机制不够,还得测。gstack 的测试分三层:
层 | 干什么 | 成本 | 速度 |
|---|---|---|---|
1 - 静态验证 | 解析 SKILL.md 里每个 | 免费 | <2s |
2 - 通过 | 启动真实 Claude 会话,跑每个 skill,查错误 | 约 $3.85 | 约 20min |
3 - LLM 当裁判 | Sonnet 给文档打分(清晰度/完整性/可操作性) | 约 $0.15 | 约 30s |
第 1 层每次 bun test 都跑,第 2 3 层由 EVALS=1 门控。理念很朴素:免费抓住 95% 的问题,只在判断题上花钱用 LLM。这种把测试成本分层的设计,在开源项目里少见。
每个 skill 开头都有一个 {{PREAMBLE}} 块,在 skill 自己的逻辑之前先跑。它用一条 bash 命令处理五件事,每件都有讲究。
第一件:更新检查。调 gstack-update-check,报告是否有新版本。日常工程。
第二件:会话追踪。touch ~/.gstack/sessions/$PPID,统计活跃会话数(最近 2 小时修改的文件)。当 3 个以上会话同时运行,所有 skill 进入ELI16 模式 - 每个问题都把上下文重新交代一遍。为什么?因为用户在多窗口之间切换,你不知道他刚才在另一个窗口里让 Claude 干了什么,得重新建立上下文。这是真实多窗口开发的场景,不是想象出来的。
第三件:运维自我改进。每次 skill 会话结束,agent 反思失败(CLI 错误、错误方法、项目怪癖),把 learnings 写进项目的 JSONL 文件供后续会话使用。会话级别的记忆,不依赖外部向量库。
第四件:AskUserQuestion 格式统一。所有 skill 问用户问题都用同一种格式:context、question、RECOMMENDATION: Choose X because ___、字母选项。一致性降低用户认知负担。
第五件:Search Before Building。这是 ETHOS.md 里的核心原则之一(下一节细讲),Preamble 把它强制注入到每个 skill 启动时。
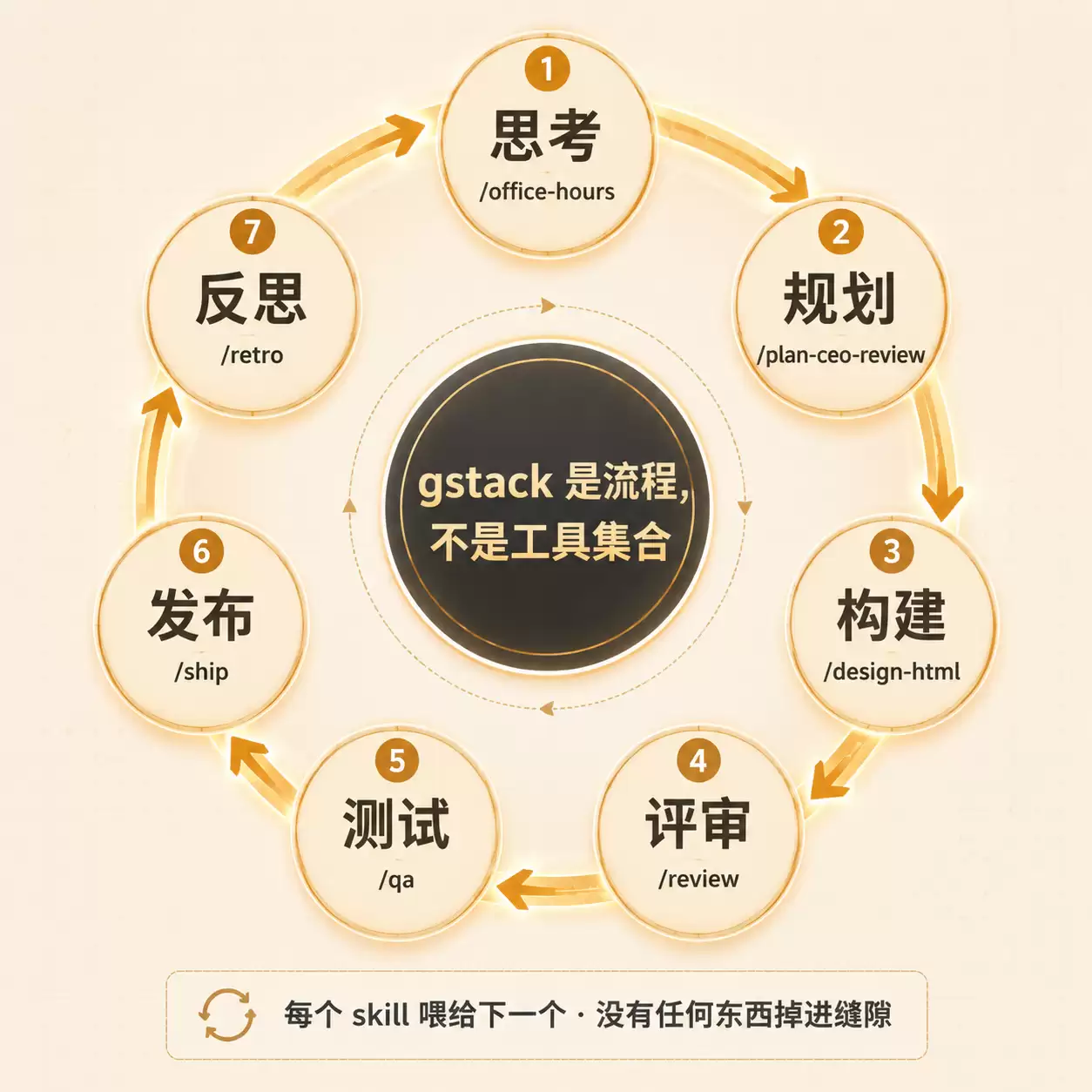
README 里有句话点出了 gstack 的本质:"gstack is a process, not a collection of tools"(gstack 是一个流程,不是工具集合)。
23 个 skill 不是孤立命令,是一个 sprint 闭环:
代码语言:markdown复制Think → Plan → Build → Review → Test → Ship → Reflect
每个 skill 喂给下一个。/office-hours 写的设计文档被 /plan-ceo-review 读取。/plan-eng-review 写的测试计划被 /qa 接走。/review 抓的 bug 被 /ship 验证已修。没有任何东西掉进缝隙,因为每一步都知道上一步是什么。
You:I want to build a daily briefing app for my calendar.You:/office-hoursClaude: [问痛点 - 具体例子,不是假设性场景]You:多个 Google 日历,事件信息过期,错误地点...Claude: 我要挑战你的框架。你说"daily briefing app",但你实际描述的是 personal chief of staff AI。[提取 5 个你没意识到的能力][挑战 4 个前提 - 你同意、不同意、或调整][生成 3 个实现方案带工时估算]建议:明天先发最窄的楔子,从真实使用学习You:/plan-ceo-review[读设计文档,挑战范围,跑 10 段评审]You:/plan-eng-review[ASCII 数据流图、状态机、错误路径]You:Approve plan. Exit plan mode.[写 2,400 行,跨 11 文件,约 8 分钟]You:/review [AUTO-FIXED 2 个问题。ASK:竞态→你批准修复]You:/qa https://staging[开真实浏览器,点流程,找并修一个 bug]You:/ship [测试 42→51( 9 新)。PR:github.com/you/app/pull/42]
来自 docs/skills.md 的官方分类,数量很多,这里按阶段列一下不展开(感兴趣的直接翻原仓库):
Think/Plan:/office-hours /spec /plan-ceo-review /plan-eng-review /plan-design-review /plan-devex-review /autoplan /design-consultationBuild:/design-shotgun /design-htmlReview/Test:/review /investigate /design-review /devex-review /qa /qa-only /csoShip:/ship /land-and-deploy /canary /benchmarkReflect/Memory:/retro /document-release /document-generate /learnBrowser 工具:/browse /open-gstack-browser /setup-browser-cookies /pair-agentPower tools:/codex(引入 OpenAI 做第二意见) /careful /freeze /guard /unfreeze /gstack-upgradeiOS QA(v1.43.0.0 ):/ios-qa /ios-fix /ios-design-review /ios-clean /ios-sync这套清单覆盖了从需求到上线的完整生命周期。其中 /codex 这个设计要单独拎出来 - 它主动引入 OpenAI 的 Codex CLI 做独立代码评审,跟 Claude 形成跨模型的第二意见。在 vendor lock-in 焦虑普遍的开发者群体里,这种主动跨 vendor的态度是加分项。
 Sprint 闭环
Sprint 闭环
图 5:Sprint 七阶段闭环(Think→Plan→Build→Review→Test→Ship→Reflect)
ETHOS.md 开篇一句话:"These are the principles that shape how gstack thinks, recommends, and builds. They are injected into every workflow skill's preamble automatically."
(这是塑造 gstack 思考、推荐和构建方式的原则,它们自动注入到每个工作流 skill 的前言里。)
三条原则,每条都带着强烈的主观判断。
(当工程时间是瓶颈时,不要试图煮干大海是对的建议。那个时代结束了。)
核心论点:AI 辅助下,完整实现一个模块只比走捷径多花几分钟。那为什么不每次都做完整的那件事?海洋是目的地 - 一个模块 100% 测试覆盖、完整功能、所有边界情况、所有错误路径。一个湖一个湖地到那里。
ETHOS.md 列了几个反模式,讲得很硬:
选 B - 它用更少代码覆盖 90% → 如果 A 多 70 行,选 A把测试推到下个 PR → 测试是成本最低的湖这要 2 周 → 应该说2 周人工 / 约 1 小时 AI 辅助1000x 工程师的第一反应是有人已经解决这个了吗,而不是让我从头设计。ETHOS.md 把知识分三层:
Layer 1(tried-and-true):经过实战的标准模式。风险不是不知道,而是假设显然的答案一定对。Layer 2(new-and-popular):当前最佳实践、博客、生态趋势。搜,但要审视 - 人会狂热,Mr. Market 不是太恐惧就是太贪婪。Layer 3(first-principles):基于对具体问题的推理得出的原创观察。最有价值。优秀的项目既避免错误(Layer 1 不重造轮子),又做出分布外的精彩观察(Layer 3)。(AI 模型推荐。用户决定。这是覆盖所有其他规则的那条规则。)
两个 AI 模型对某个变更达成一致是强信号,但不是命令。用户永远有模型缺乏的上下文:领域知识、商业关系、战略时机、个人品味、还没分享的未来计划。
User Sovereignty 还援引了两位大佬的话。Karpathy 称之为 Iron Man suit 哲学:好的 AI 产品增强用户,不是替代用户。Simon Willison 警告说 agents are merchants of complexity - 当人类把自己从循环中移除,他们不知道发生了什么。
这三条原则不是装饰,是 gstack 做技术决策时的判据。比如为什么 /cso 要给每条 finding 带 17 个误报排除 8/10 置信度门 具体利用场景 - 因为 User Sovereignty,用户的时间不该被低置信度的报警消耗。
gstack 的硬工程不止上面这些,再快速过几个。
当用户跑 pair-agent --client 时,守护进程会起一个 ngrok 隧道让远程配对 agent 驱动浏览器。问题:把完整守护进程接口暴露到公网,即使躲在随机 ngrok 子域后面,/health 会在任何 Origin 欺骗下泄漏 root token,/cookie-picker 把 token 嵌进任何调用者都能取的 HTML。
gstack 的解法是两个 HTTP 监听器,不是一个:
本地监听器(127.0.0.1:LOCAL_PORT) - 始终绑定。服务 bootstrap、/cookie-picker、/inspector/*、完整命令接口。永不转发。隧道监听器(127.0.0.1:TUNNEL_PORT) - 在 /tunnel/start 时惰性绑定,/tunnel/stop 时拆除。服务一个锁定的白名单:/connect、/command(仅 scoped token 浏览器驱动命令白名单)、/sidebar-chat。其他一律 404。ngrok 只转发隧道端口。安全属性来自物理端口分离:隧道调用者够不着 /health 或 /cookie-picker,因为这些路径在那个 TCP socket 上根本不存在。ARCHITECTURE.md 解释得很直接 - header 推断(检查 x-forwarded-for、检查 origin)不可靠,ngrok header 行为会变,本地袋里可能添加这些 header;socket 分离则不会。
这个设计值得做 agent 远程协作的工具抄。基于 header 的鉴权是脆弱的,基于 socket 物理隔离的鉴权是强壮的。
Cookies 是 gstack 处理的最敏感数据。ARCHITECTURE.md 列了五条原则:
Keychain 访问需用户批准:每个浏览器首次 cookie 导入触发 macOS Keychain 对话框,用户必须点 "Allow" 或 "Always Allow"。gstack 永不静默访问凭证。解密在进程内发生:cookie 值在内存中解密(PBKDF2 AES-128-CBC),加载进 Playwright context,永不以明文写盘。cookie picker UI 永不显示 cookie 值 - 只显示域名和数量。数据库只读:把 Chromium cookie DB 复制到临时文件(避免 SQLite 锁冲突),以只读方式打开。永不修改真实浏览器的 cookie 数据库。密钥缓存按会话:Keychain 密码 派生的 AES key 在 server 生命周期内缓存于内存。server 关闭,缓存消失。日志中无 cookie 值:控制台、网络、对话日志永不包含 cookie 值。cookies 命令输出 cookie 元数据,但值被截断。五条原则背后是 gstack 对隐私的态度 - 默认本地、默认不持久化、默认不泄漏。对一个要读取用户登录凭证的工具来说,这是该有的克制。
最后说一个反直觉的设计。server 不尝试自我治愈。如果 Chromium 崩溃(browser.on('disconnected')),server 立即退出。CLI 在下一条命令上检测到死掉的 server,自动重启。
ARCHITECTURE.md 的原话:这比尝试重新连接一个半死的浏览器进程更简单、更可靠。
很多项目在这种地方会写一堆 reconnect 逻辑、状态恢复、tab 重建。gstack 选择最简单的路 - 死了就重启。因为重启的成本(约 3 秒)远低于维护半死状态的成本。
到这里,源码层面的事实已经摆清楚了。现在回到最开始那个问题:为什么是 11.8 万 star?为什么是这个项目?
综合源码分析,魅力可以拆成几个具体的工程和定位决策,而不是玄学。
Garry Tan 是 YC 总裁兼 CEO。YC 孵化了 Coinbase、Instacart、Rippling、Airbnb、Stripe、Reddit。他本人是早期 Palantir 工程师、Posterous 联合创始人。一个有这种履历的人开源自己的软件工厂,本身就是极强的可信度信号 - 这不是某个无名作者的实验品,这是一个有战绩的人的生产力工具。
作者背书这一点不用回避 - star 数里有相当比例是冲着 Garry Tan 这个名字来的。但这也只是入场券,撑不起 11 万的留存。
Claude Code 原生是通用命令行 AI 助手,用户面对的是空白 prompt。gstack 提供的是结构化角色 - 不是帮我写代码,而是你是 CEO,重新思考这个产品。门槛立刻降下来了。
这件事的妙处在于,它没改 Claude Code 任何东西,只是往 ~/.claude/skills/ 里放了一堆 Markdown。用户不需要理解 prompt engineering,只需要知道 /qa 是干 QA、/ship 是发 PR。复杂度被角色化封装了。
23 个角色不是孤立命令,是一个 sprint 闭环:Think→Plan→Build→Review→Test→Ship→Reflect。每个 skill 喂给下一个。
这是流程即代码的思路。传统团队的流程在文档里、在口头约定里、在项目经理的脑子里 - 都会漂移。gstack 把流程写成 slash 命令,每次执行都一致。这让 AI agent 的工作方式变得可重复,而可重复是工程化的前提。
"everything else is Markdown" - 但浏览器是硬骨头。长驻守护进程、Ref 系统、六层 prompt injection 防御、双监听器隧道、cookie 安全模型 - 这些是实打实的工程,不是 prompt 套路。
HN 上有用户说 gstack 是一堆让 Claude 装成不同人的文本文件。这话对 skill 层成立,对浏览器层不成立。而浏览器层恰恰是 gstack 区别于其他以 prompt 为主的项目 的关键 - 你能在 obra/superpowers 那类以 skill 为主的仓库里找到类似的 prompt,但找不到一个会自己开浏览器点页面的守护进程。
无 premium tier、无 waitlist、无 SaaS 依赖。所有数据本地(cookies 在内存解密、telemetry 默认关闭)。这对注重隐私和可控性的开发者是强吸引力。
社区遥测数字(CHANGELOG 引用):约 23,839 个独立安装(Supabase 社区层遥测,2026 年 3-6 月 cohort)。注意这不是 star 数 - star 数 117,967 远高于安装数,符合 GitHub 普遍规律:点 star 成本极低,多为围观/收藏行为,真正装下来用的人是少数。
支持 10 个 AI coding agent:Claude / Codex / Cursor / Factory / Slate / Kiro / Hermes / GBrain / OpenCode / OpenClaw。/codex 主动引入 OpenAI 做第二意见,/pair-agent 让不同 vendor 的 agent 协作。
加新 host 在 gstack 里是一个 TypeScript 配置文件的事,零代码改动(docs/ADDING_A_HOST.md)。这种把 vendor 抽象掉的态度,在 vendor lock-in 焦虑普遍的开发者群体里是加分项。
README 约 45KB、ARCHITECTURE 约 32KB、ETHOS 7.9KB、CHANGELOG 909KB(395 个版本)、skills.md、ON_THE_LOC_CONTROVERSY.md。
文档不仅写是什么,还写为什么这样设计、为什么不那样设计、数字依据。比如为什么选 Bun 给了四条理由,为什么用 Locator 不用 DOM 注入给了三条,为什么 L6 要双分类器投票给了解释。这种文档质量在开源项目里罕见。
README 显式声明覆盖了 Karpathy 的 AI 编码四类失败模式(错误假设、过度复杂、正交编辑、命令式胜过声明式)。Karpathy 的 skills repo 有 17K star,gstack 主动对标并声称是其工作流执行层。
这是个聪明的定位 - 借势 Karpathy 的影响力,同时把自己跟规则集那一类项目区分开。gstack 卖的不是规则,是工作流。
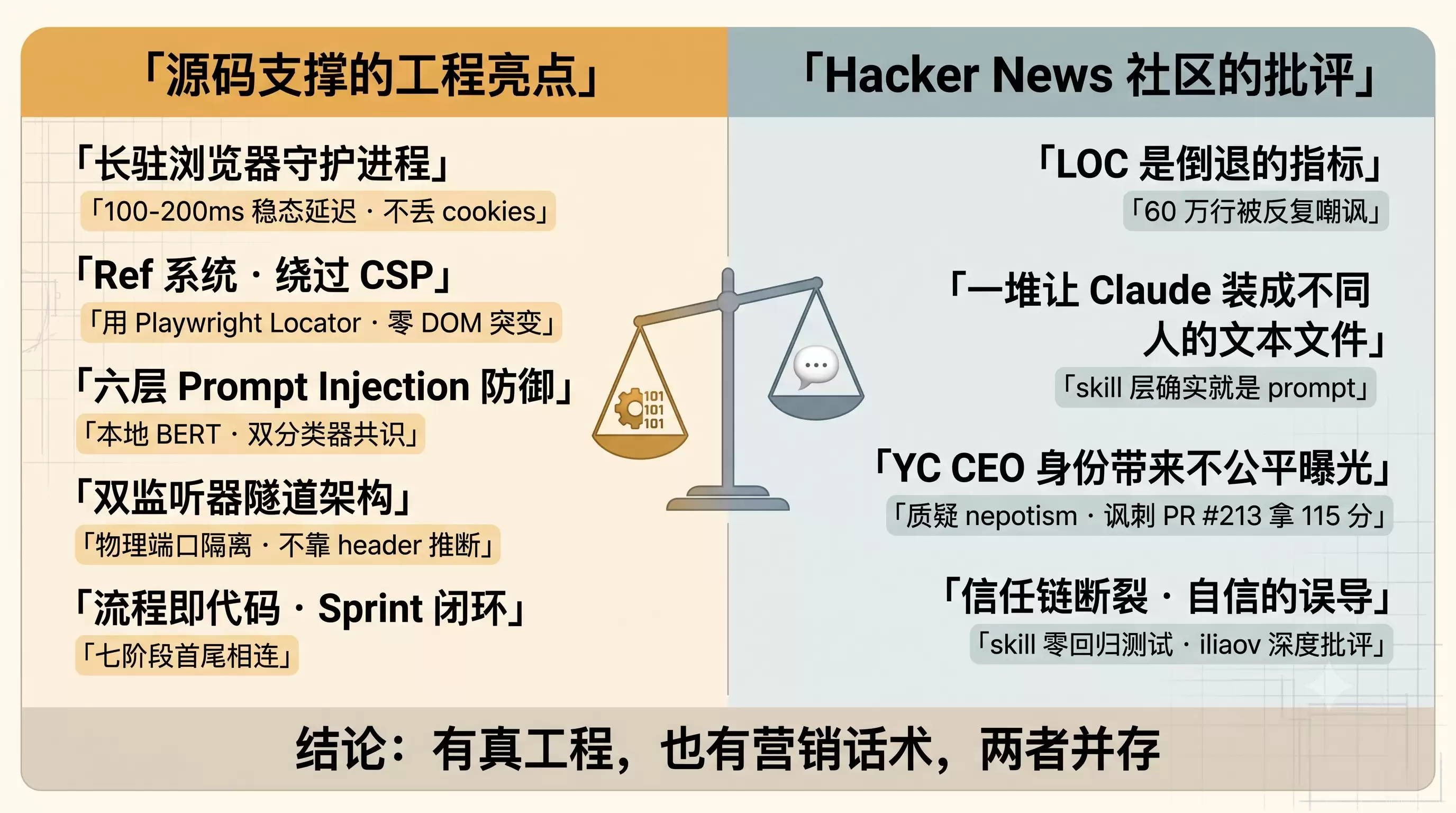
讲完了魅力,得讲争议。一个 11 万 star 的项目,Hacker News 上的态度却两极分化,而且批评声压倒性。批评这一面如果不展开,文章就成了软文。
通过 HN Algolia API 检索到的相关帖子里,批评派的核心论点有四条,逐条看一下。
这是评论里被反复提到、几十条独立评论一致的观点。Garry Tan 在 README 里写过 "In the last 60 days I have written over 600,000 lines of production code"(过去 60 天我写了超过 60 万行生产代码)。这句话在 HN 上被反复嘲讽。
代表评论(rileymichael,74 分主帖):"and what is there to show for it? absolutely terrible metric"(然后呢?有什么拿得出手的?这是个糟糕透顶的指标)。
代表评论(the_af):"writing over 600,000 lines of production code is not something to be proud of... measuring progress in LoC is not something that is done anymore"(写 60 万行生产代码不是什么值得骄傲的事... 用 LOC 衡量进度早就不这么干了)。
这个批评是成立的。LOC 是 70 年代的指标,90 年代就被批判过。gstack 自己也意识到了这点 - 项目里有专门的 docs/ON_THE_LOC_CONTROVERSY.md 解释方法论,但社区似乎没买账。
这是最扎心的一条,因为它部分成立。
fdghrtbrt 的评论:"it's a bunch of files telling Claude to pretend to be different people - I swear that was my analysis as well, verbatim"(就是一堆让 Claude 装成不同人的文件 - 我发誓这也是我的分析,一字不差)。
CactusBlue:"Mostly just markdown-based skills... the repo seems pretty light on actual tooling"(主要是基于 Markdown 的 skill... 这个仓库在实际工具上看起来挺轻的)。
这个批评对 skill 层是公平的 - skill 确实就是 prompt。但它忽略了浏览器层的工程量。问题是,对绝大多数只看 README 的人,他们看到的就是一堆 slash 命令的列表,看不到那个 58MB 二进制里塞了多少东西。
Sherveen(自称在 Product Hunt 上也批评过,据说激怒了 Garry):"If he weren't the CEO of YC, this wouldn't be on PH, and it wouldn't be on HN... This is not an impressive setup. It's overengineered"(如果他不是 YC 的 CEO,这玩意上不了 PH,也上不了 HN... 这套配置没什么了不起。过度工程化了)。
archagon 质疑帖子曾被 flag 后被 mod 解除:"How is this anything other than nepotism?"(这不是裙带关系是什么?)。
Sherveen 的批评涉及主观判断,但有一个客观事实能佐证它存在:全 HN 上 gstack 相关帖子里热度排在第一的,是一个讽刺性 PR。用户 tornikeo 用 Kagi 翻译器把 gstack README "translate to plain English"(翻译成大白话)并提交为 PR #213,拿了 115 分,22 条评论 - 比正经技术讨论帖(74 分)还高。这被社区视为对营销话术的集体解构。
第四条批评最值得技术读者关注。来自 iliaov 的 HN 帖子(9 分):"I'm tired of LLM skill slop, so I built mine with regression tests"(我厌倦了 LLM skill 垃圾,所以我自己造了带回归测试的版本)。
他用了 gstack 一周后给出的核心批评是:gstack 的 /office-hours 等 skill 零回归测试,"Perfectly polished, confident-sounding skills routinely mislead me"(完美打磨、听起来自信的 skill 经常误导我)。
更深的洞察是:gstack 的失败根因是信任链断裂 - "Claude believed GStack knew what it was doing. GStack believed I knew what I was doing. But I was doing research - by definition what you do when you don't know"(Claude 相信 GStack 知道自己在干什么。GStack 相信我知道自己在干什么。但我是在做研究 - 研究的本质就是你不知道答案的时候才做的事)。
iliaov 指向的是一个真问题:skill 写得越自信,用户越容易盲信;但 skill 是 prompt,prompt 没有类型检查、没有单元测试,gstack 的三层测试体系测的是 skill 文档是否和代码一致,不测 skill 给出的建议是否正确。
把这些批评摆出来之后,怎么评价?
gstack 的浏览器层是硬工程,这部分站得住脚。六层 prompt injection 防御、双监听器隧道、Ref 系统的 Locator 选择 - 这些设计拿到任何严肃的工程评审里都经得起推敲。
gstack 的 skill 层是 prompt,这部分确实就是 prompt。HN 说一堆文本文件对这层成立。但这不等于 skill 层没价值 - 把团队流程固化成可复用的工作流,本身就是工程化的贡献,只是这个贡献不像浏览器守护进程那样能用代码行数衡量。
Garry Tan 的 YC CEO 身份确实带来了不成比例的曝光,这是事实。但曝光只解决被看见的问题,不解决被留下来用的问题。社区遥测的 23,839 个独立安装,以及至少 10 个明确标注 inspired by gstack 的衍生项目(upstack、nanopm、CFO-stack、tonone、Gstack 等),证明这个东西确实在被使用、在被模仿。
HN 上也有少数实际用过的人给出了正面反馈。用户 madrox 经过几天深度使用后,评价 plan skills 能"catch gaps"、DESIGN.md "needs to become a standard practice"、浏览器方案 "superior to Claude's built-in extension in pretty much every way"(几乎在所有方面都优于 Claude 内置扩展)。不过他也批评 CEO skill 不太有效、不喜欢 auto-update 被用来推送 Garry's List 文章。这种"用过且有赞有弹"的反馈,比纯围观者的嘲讽更有参考价值。
至于 LOC 指标 - 这个批评完全成立,gstack 自己也在 ON_THE_LOC_CONTROVERSY.md 里试图辩护,但方法论争议没消解。
一句话总结:这是个有真工程、也有营销话术的项目,两者并存。
 魅力 vs 批评对照
魅力 vs 批评对照
图 6:源码支撑的工程魅力 vs HN 社区的批评(天平视角)
最后说一个有意思的现象 - gstack 已经长出了一个明确的衍生生态。
HN 上至少有 10 个明确标注 inspired by gstack 的 Show HN 项目,每一个都从不同角度补 gstack 的那 20%:
项目 | 定位 |
|---|---|
upstack | gstack 的最后 20% 补充,专注 red/green TDD |
nanopm | gstack 证明了工程团队,我来补 PM 层 |
CFO-stack | 双分录会计 skill 套件 |
tonone | 不再 prompt Claude,给它职位头衔 |
Gstack | gstack 适配 C 开发 |
gstack-fork | 适配 Google Antigravity Gemini-CLI |
CTP Room | 基于 gstack 的多 agent 协作层 |
the-big-learn | gstack for Learning Chinese |
imstack | 加密投资管理 skill 套件 |
gstack-auto | 并行化 gstack 运行 |
这批项目形成了一个明确的gstack 模式亚文化。它们共享同一个核心假设:AI agent 的工作流应该被编码成角色化的 skill,而不是即兴的 prompt。
从开源生态的角度看,一个项目能催生 10 个明确标注 inspired by 的衍生项目,本身就是开创性地位的证据。调研范围内,未见 Karpathy 的 skills repo(17K star)或 obra/superpowers 形成同等规模的衍生生态。
回到最开始那个问题:gstack 凭什么拿 11.8 万 star?
把它讲清楚了:跟 LOC 无关,跟 Garry Tan 的名字无关,也跟"23 个专家角色"这种话术无关。撑起 11.8 万 star 的是几个具体的工程和定位决策 -
第一,它把一个真实的长驻浏览器守护进程做到了生产可用。100-200ms 的稳态延迟、不丢 cookie 的长驻进程、绕过 CSP 的 Locator 方案、6 层 prompt injection 防御 - 这些才是能让 AI agent 真正操作 Web 的工程。
第二,它把不可重复的 AI 即兴对话,固化成了可复用的 sprint 闭环。Think→Plan→Build→Review→Test→Ship→Reflect,每一步都接住上一步的产出。流程即代码不是口号,是把团队的口头约定变成 slash 命令。
第三,它在 vendor lock-in 焦虑的时代,选择做 vendor 中立。10 个 host、/codex 主动跨模型、加新 host 零代码改动。
还有几件事也得算上:MIT 协议、默认本地、文档把为什么这么设计写明白。
至于它的问题,也别回避:skill 层缺乏回归测试导致自信的误导、LOC 指标的营销包装、过度工程化的指控 - 这些都是真问题,使用的时候心里要有数。
但有一个判断是确定的:不管 gstack 这个具体项目最终走向哪里,它确立的 AI agent 工作流应该被角色化、被流程化、被工程化这个范式,会留下来。那 10 个衍生项目就是证据。
下一个时代的开发工具长什么样,大概率会带有 gstack 的影子。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!