粉丝苦等九年终迎续作!幼女战记第二季官方预告公布!7月8日首播
2026-07-04 3380788
2026-07-03 0
上一篇文章完成了 BERT 微调效果的系统测试与验收指标设计。本章进入生成式模型领域:使用 Hugging Face 上的 GPT-2 中文预训练模型,在本地语料上微调,训练一个中文古诗词生成模型。
上一篇快速导航:《(六)模型微调效果测试:基于 BERT 的中文评价情感分析[附源码]》
需要本章配套源码和数据集的同学,可以点赞 + 关注,我会把完整工程发给你。
GPT-2 是一种基于 Transformer 的生成模型,专注于生成连贯的文本。在 Hugging Face 的 Transformers 库中,GPT-2 已经被应用于多种中文文本生成任务,如古诗词、歌词和对联生成等。
# 将模型下载到本地调用
from transformers import AutoModelForCausalLM, AutoTokenizer# 将模型和分词器下载到本地,并指定保存路径
model_name = "uer/gpt2-chinese-cluecorpussmall"
cache_dir = "model/uer/gpt2-chinese-cluecorpussmall"# 下载模型
AutoModelForCausalLM.from_pretrained(model_name, cache_dir=cache_dir)
# 下载分词工具
AutoTokenizer.from_pretrained(model_name, cache_dir=cache_dir)print(f"模型分词器已下载到:{cache_dir}")
说明: 后续训练与推理代码统一从 model/uer/gpt2-chinese-cluecorpussmall 加载模型,请先执行上述下载脚本。
from transformers import BertTokenizer, GPT2LMHeadModel, TextGenerationPipeline
# 加载中文歌词模型的 tokenizer 和模型
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-lyric")
# 使用 GPT2LMHeadModel 加载预训练的中文歌词生成模型
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-lyric")
# 使用 pipeline 进行文本生成
text_generator = TextGenerationPipeline(model, tokenizer)
# 生成文本,max_length 指定生成的最大长度,do_sample=True 启用随机采样
print(text_generator("雨一直下", max_length=100, do_sample=True))
解释:
BertTokenizer:
将输入文本转换为模型可处理的格式。中文 GPT-2 系列沿用了 BERT 的分词器设计。
GPT2LMHeadModel:
GPT-2 的语言模型实现,专注于文本生成任务。
TextGenerationPipeline:
Hugging Face 提供的推理工具,封装了模型与分词器,一行代码即可生成文本。
do_sample=True:
启用随机采样,每次生成结果可能不同,有助于输出多样化内容。

from transformers import BertTokenizer, GPT2LMHeadModel, TextGenerationPipeline
# 加载中文古文模型的 tokenizer 和模型
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-ancient")
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-ancient")
# 创建文本生成管道,并指定使用 GPU (device=0)
text_generator = TextGenerationPipeline(model, tokenizer, device=0)
# 生成文本,启用随机采样
print(text_generator("卖炭翁,", max_length=100, do_sample=True))
解释:
device=0
指定使用第一块 GPU。若无 GPU,可省略该参数或设为 device=-1 使用 CPU。
max_length=100:
生成文本的最大 token 数。

# 加载中文对联模型的 tokenizer 和模型
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-couplet")
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-couplet")
text_generator = TextGenerationPipeline(model, tokenizer)
# 生成对联,以 [CLS] 为对联的开头
print(text_generator("[CLS]春 回 大 地 千 山 秀 -", max_length=28,
do_sample=True))
解释:
[CLS] 标记:
特殊标记,用于标记对联的开头。生成的对联会以 [CLS] 为开头,模型将生成后续部分。

GPT2LMHeadModel(
(transformer): GPT2Model( # transformer 无法表示序列
(wte): Embedding(21128, 768) # 词向量编码,768是词向量的维度,即一个词转化为长度为768的向量,词向量越高,表达的信息越详细
(wpe): Embedding(1024, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0-11): 12 x GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D(nf=2304, nx=768)
(c_proj): Conv1D(nf=768, nx=768)
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D(nf=3072, nx=768)
(c_proj): Conv1D(nf=768, nx=3072)
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=768, out_features=21128, bias=False) # 最终的输出,输入和输出都是21128
)(wte): Embedding(21128, 768) input_ids,一共有21128个索引。
文本生成模型的本质,实际上还是分类。
与 BERT「整句输入 → 输出一个分类标签」不同,GPT-2 是自回归生成:每步只预测下一个字,再拼回去继续预测。流程如下:
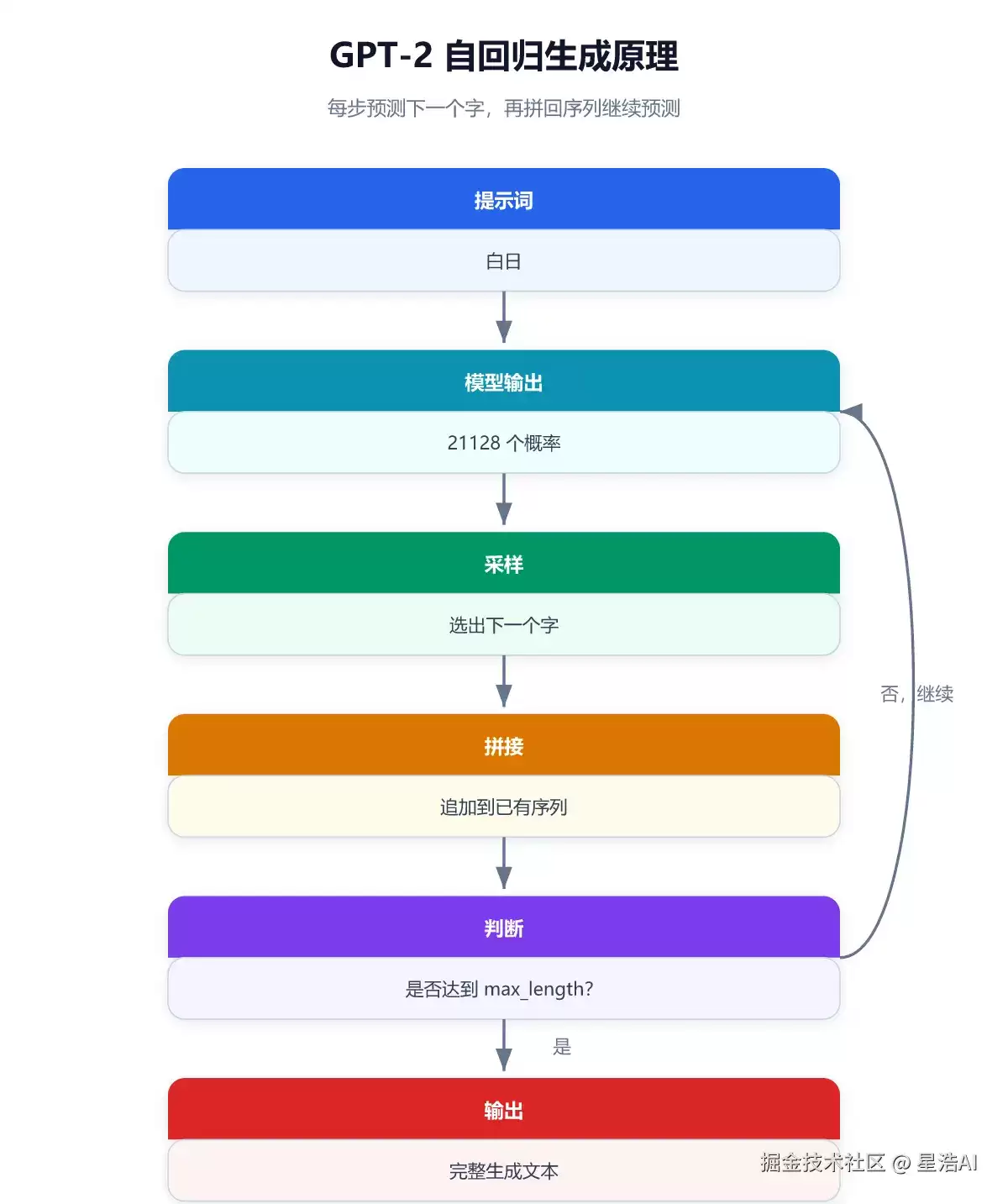
训练前需准备符合格式的语料。chinese_poems.txt 每行一首完整的古诗,示例:
床前明月光,疑是地上霜。举头望明月,低头思故乡。
春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。
白日依山尽,黄河入海流。欲穷千里目,更上一层楼。
锄禾日当午,汗滴禾下土。谁知盘中餐,粒粒皆辛苦。
解释:
本章完整流程如下:
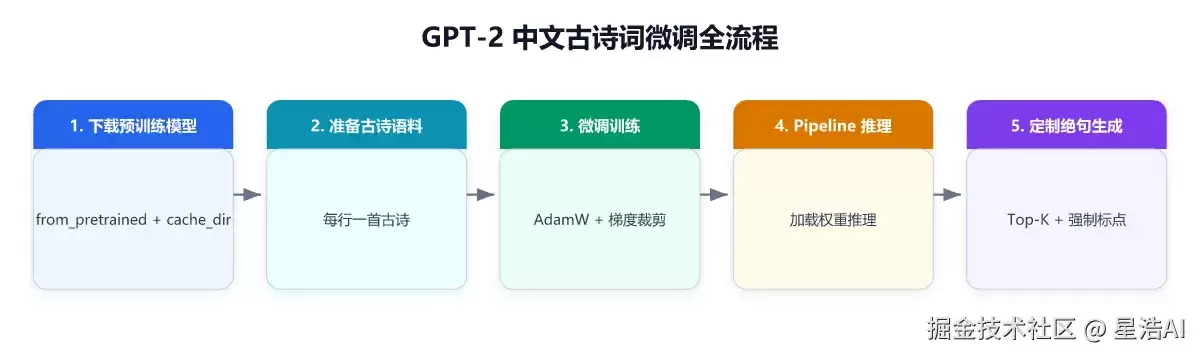
定义自定义数据集,核心逻辑是按行读取古诗、过滤空行:
from torch.utils.data import Datasetclass MyDataset(Dataset):
def __init__(self):
# 读取文本文件,并去除每行的空白字符
with open("data/chinese_poems.txt", encoding="utf-8") as f:
lines = f.readlines()
# 去除每行文本的前后空白字符
lines = [i.strip() for i in lines if i.strip()]
self.lines = lines def __len__(self):
# 返回数据集的总长度
return len(self.lines) def __getitem__(self, item):
# 根据索引返回一条数据
return self.lines[item]
说明:
__init__:读取数据文件并过滤空行。__len__:返回样本数量,供 DataLoader 使用。__getitem__:按索引返回单条样本。模型训练流程与 BERT 微调类似:加载预训练模型 → 构建 DataLoader → 定义优化器 → 循环训练 → 保存权重。与 BERT 分类任务的关键差异在于:GPT-2 是生成式语言模型,collate_fn 需要把 input_ids 复制为 labels,用于下一词预测。
加载模型与数据:
dataset = MyDataset()
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR)
model = AutoModelForCausalLM.from_pretrained(MODEL_DIR)
collate_fn:批量编码 + 构造标签
def collate_fn(data):
data = tokenizer.batch_encode_plus(data,
padding=True,
truncation=True,
max_length=512,
return_tensors='pt')
data['labels'] = data['input_ids'].clone() # 关键:自回归语言模型标签
return dataloader = DataLoader(dataset=dataset,
batch_size=2,
shuffle=True,
drop_last=True,
collate_fn=collate_fn)
train() 主函数:优化器、调度器与训练循环
optimizer = AdamW(model.parameters(), lr=2e-5)
scheduler = get_scheduler(name="linear",
num_warmup_steps=0,
num_training_steps=len(loader),
optimizer=optimizer)for epoch in range(EPOCH):
for i, data in enumerate(loader):
out = model(**data)
loss = out['loss'] loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad() torch.save(model.state_dict(), WEIGHTS_PATH)
每轮 epoch 结束后,权重保存到 .pt 文件中。
训练要点:
设备选择:
自动检测 GPU,无 GPU 时使用 CPU。
AdamW 优化器:
lr=2e-5 是预训练模型微调的常用学习率,过大容易破坏已有语义,过小则收敛慢。
学习率调度器:
get_scheduler 按训练步数线性调整学习率。
梯度裁剪:
clip_grad_norm_ 防止梯度爆炸。
训练循环:
前向传播 → 计算 loss → 反向传播 → 更新参数;每轮 epoch 结束保存权重。
加载微调权重后,用 Pipeline 一行生成:
model.load_state_dict(torch.load(WEIGHTS_PATH, map_location="cpu"))
pipeline = TextGenerationPipeline(model, tokenizer, device=device)print(pipeline("白日", max_length=24, do_sample=True))

说明: 加载微调后的权重,以「白日」为提示词,随机采样生成诗句。Pipeline 写法简单,但无法控制绝句格式。
Pipeline 生成的长度和格式不可控。通过逐字生成 + Top-K 采样 + 强制标点,输出标准五言绝句。核心是递归函数 generate_loop,每轮预测下一个字,直到达到绝句长度:
两种推理方式对比如下:
| 方式 | 长度控制 | 格式控制 | 代码复杂度 |
|---|---|---|---|
| Pipeline | 仅 max_length | 不可控 | 低,一行调用 |
| 定制生成 | row × col 精确控制 | 强制逗号、句号 | 较高,逐字递归 |
# Top-K 采样:只保留概率最高的 50 个候选词
topk_value = torch.topk(out, 50).values[:, -1].unsqueeze(dim=1)
out = out.masked_fill(out < topk_value, -float("inf"))
out = out.softmax(dim=1).multinomial(num_samples=1)# 按五言格式强制插入逗号、句号
c = data["input_ids"].shape[1] / (col + 1)
if c % 1 == 0:
token = "." if c % 2 == 0 else ","
out[:, 0] = tokenizer.get_vocab()[token]data["input_ids"] = torch.cat([data["input_ids"], out], dim=1)if data["input_ids"].shape[1] >= row * col + row + 1:
return data
return generate_loop(data) # 未达长度,递归继续生成data = generate_loop(data) # 从提示词出发,逐字生成
generate("白", row=4, col=5) # 4 行,每行 5 字
定制化生成要点:
Top-K 采样:
缩小候选词范围,提升生成质量。
强制标点:
按 (col+1) 的节奏插入逗号与句号,控制绝句格式。
row / col 参数:
row=4, col=5 即四行五言绝句。

| 阶段 | 关键操作 |
|---|---|
| 模型下载 | from_pretrained + cache_dir |
| 数据准备 | 每行一首古诗,UTF-8 编码 |
| 微调训练 | DataLoader + AdamW + 梯度裁剪 |
| 推理测试 | Pipeline 或定制化逐字生成 |
GPT-2 微调的核心思路与 BERT 类似:加载预训练权重 → 准备领域语料 → 在小数据集上继续训练 → 保存并加载自定义权重推理。区别在于 GPT-2 是生成式模型,训练目标是预测下一个词,推理时通过采样策略控制输出风格与格式。
需要本章配套源码和数据集的同学,可以点赞 + 关注,我会把完整工程发给你。