《天国拯救2》二度无缘奖项引玩家不满 亨利无奈靠"偷"斩获殊荣
2026-07-05 3382761
2026-07-05 0
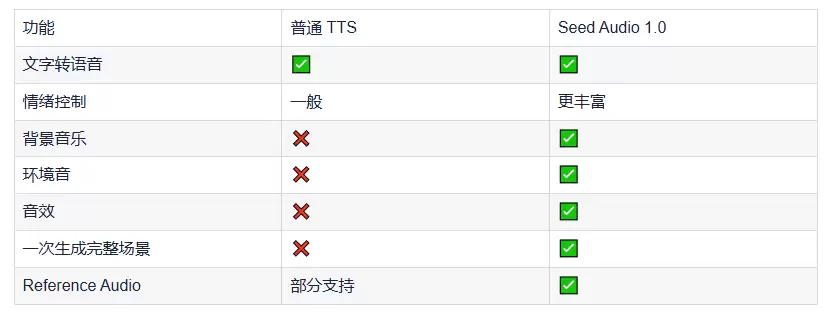
继 Seedance、Seedream 等模型之后,字节跳动 Seed 团队正式推出了 Seed Audio 1.0,它不仅能够生成自然语音,还能将对白、背景音乐、环境音和音效融合到同一个音频输出中,为视频创作者、游戏开发者和内容团队提供更加完整的 AI 音频解决方案。
Seed Audio 1.0 是字节跳动推出的新一代多模态 AI 音频模型。
与传统 Text-to-Speech(TTS)不同,它并不仅仅负责"把文字读出来"。
它能够理解整个场景,根据提示词生成:
自然的人声对白环境声音(Environment)背景音乐(BGM)各种音效(SFX)最终直接输出一段完整的音频,而不是多个独立素材等待后期混音。
传统流程通常需要:
代码语言:txt复制TTS → 下载音乐 → 下载音效 → Premiere 混音
而 Seed Audio 可以直接生成:
代码语言:txt复制Voice Music Sound Effects Ambience
例如:
代码语言:txt复制一位老人站在海边,缓慢讲述自己的童年,远处传来海浪,背景播放轻柔钢琴。
模型即可直接生成完整音频。
除了文字 Prompt,Seed Audio 还支持参考素材。
例如可以上传:
一个说话人的声音一段背景音乐一段环境音模型会学习参考素材的风格,再进行新的生成。
相比传统 TTS:
代码语言:txt复制Hello.
Seed Audio 更关注:
开心悲伤紧张激动恐惧平静因此对白更接近真人配音.
依托 Seed Speech 系列技术,Seed Audio 支持多语言语音生成,并能实现更加自然的语音表现。
官方定位主要包括以下几类场景:
例如:
代码语言:txt复制Generate a documentary narrationwith calm male voice,ocean ambience,cinematic background music.
适合:
YouTubeTikTok短视频宣传片广告制作可以一次生成:
产品介绍转场音效背景音乐减少后期制作时间。
AI Podcast
Prompt:
代码语言:txt复制Two people discussing AI,coffee shop ambience,soft jazz background.
生成结果包含:
两个人说话
咖啡店环境背景音乐无需单独寻找素材。与传统 TTS 有什么区别?
很多人容易混淆 Seed Music 与 Seed Audio。
实际上两者定位不同:
主要关注:
AI 作曲歌曲生成风格迁移歌声转换音乐编辑更加关注:
语音音效环境声音乐全场景声音生成可以理解为:
代码语言:txt复制Seed Music 更偏向音乐创作,而 Seed Audio 更偏向完整的 AI 音频内容生成。
Seed Audio 1.0 的目标并不是取代传统 TTS,而是将 语音、背景音乐、环境音和音效 融合到统一的生成流程中,让创作者能够通过一次 Prompt 完成整个声音场景的构建。对于视频创作、播客、有声书、广告、游戏等需要丰富音频设计的场景,它相比传统「TTS 配乐 音效」的分步工作流更高效,也更符合未来多模态内容生成的发展方向。