利用Kimi智能编写产品推广文案_结合Kimi联网获取竞品数据
2026-06-02 3338906
2026-06-02 0
人工智能正迎来革命性突破,AI自我进化技术成为通向AGI的关键路径。本文将深度解析递归自改进如何推动AI实现质的飞跃。

当前AI发展已进入全新阶段,硅谷专家普遍认为自我进化是突破规模瓶颈的核心方案。Anthropic联合创始人预测,到2028年AI实现自主改进的概率高达60%。

OpenAI近期高薪招聘递归自改进研究员,年薪达44万美元。同时AI科研领域取得重大进展,Nature连发三篇智能体论文,Google DeepMind等机构展示了AI在药物研发中的突破性表现。
2026年3月,上海科学智能研究院推出Suiren-1.0模型,凭借1.8B参数量超越UniMol系列。该模型采用320张H800 GPU和7000万条量子化学数据,展现出典型的算力优势。
但Suiren存在明显局限:其训练数据集中于可计算性质,而实际研发更依赖实验性质数据。实验数据具有稀疏性、噪声大等特点,传统方法难以解决这些挑战。
深度原理团队开发的MIRA系统实现了全自主科研流程。该系统仅需人类提供研究目标,即可完成从文献调研到模型训练的全过程。
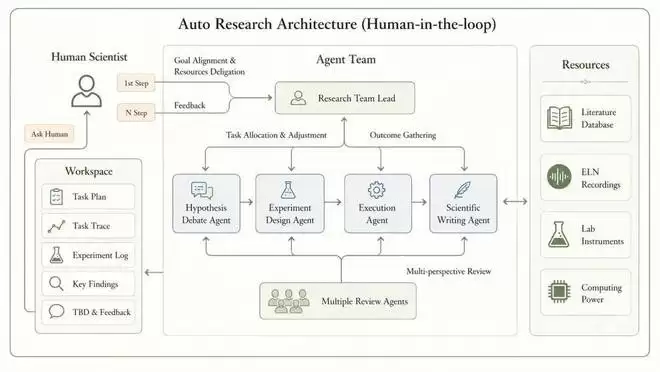
MIRA具备完整科研能力:理解目标、拆解任务、执行实验、分析结果并调整策略。这种递归闭环使模型性能持续提升,将Self-Improving Agent理论成功应用于科学问题。
面对开放性问题时,MIRA能自主分析并选择最优方案。例如在分子预测任务中,它推荐保留UniMol-v2骨架,增加多构象感知能力。
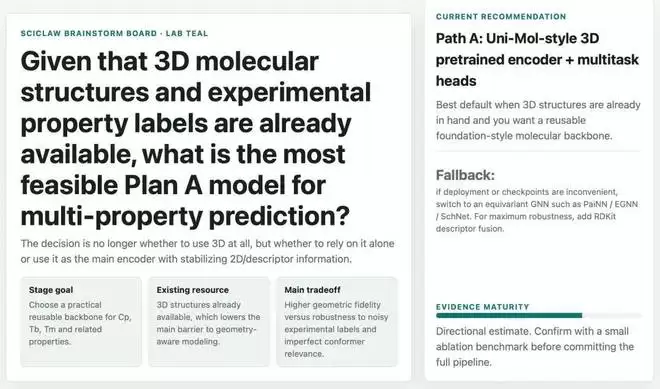
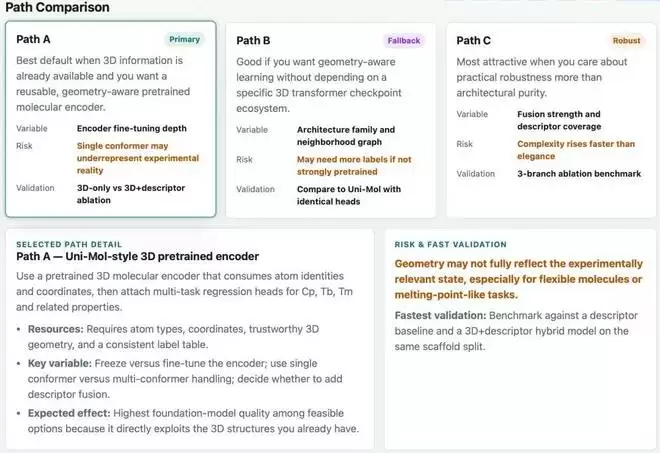
MIRA完成了代码级重构:识别冗余模块、重设计数据流、标准化接口。这种直接操作源代码的能力是其区别于传统工具的关键。
在数据处理环节,MIRA展现出类人直觉:能基于物理常识判断数据合理性。面对40个实验性质数据集,它自主执行多阶段清洗,识别并移除异常数据点。
MIRA创新性地将LLM训练范式迁移至材料模型,并加入物理改造:
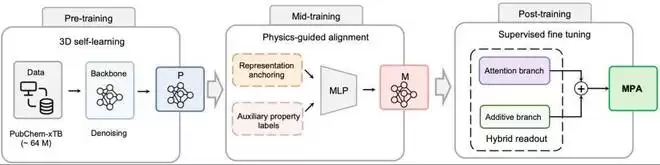
1. 预训练阶段:使用6400万分子数据进行3D自监督学习
2. 物理对齐中间训练:仅保留与目标性质物理机制匹配的辅助监督
3. 后训练阶段:引入Huber损失和混合读出头设计
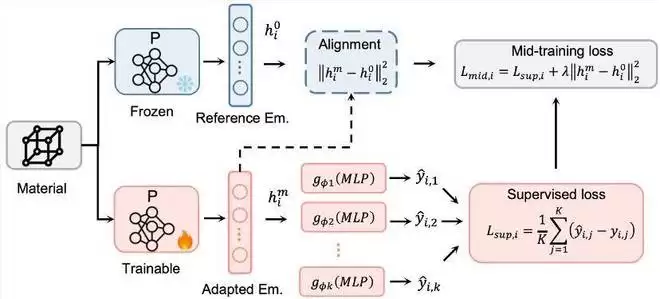
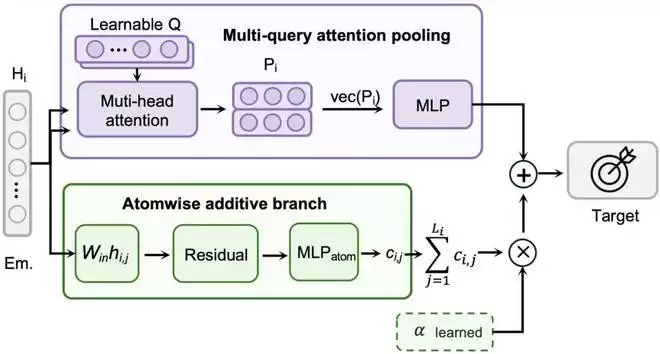
MPA模型取得显著突破:
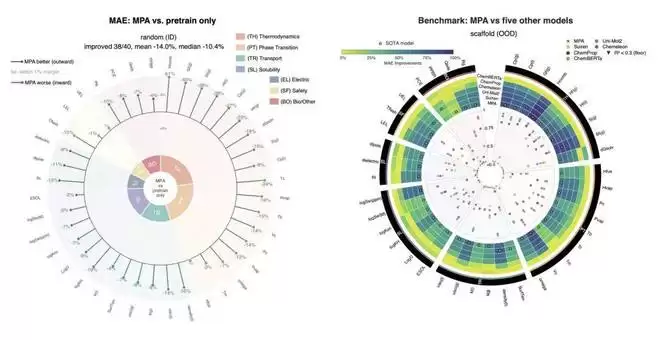
40项任务中38项获得提升,平均误差降低14%。热力学性质改善最显著,燃烧焓误差降低51.1%。与Suiren相比,40个端点中赢得35个,平均误差再降5.4%。
MPA的成功源于上百轮自主迭代。MIRA在数据、架构、损失函数等方面持续优化:
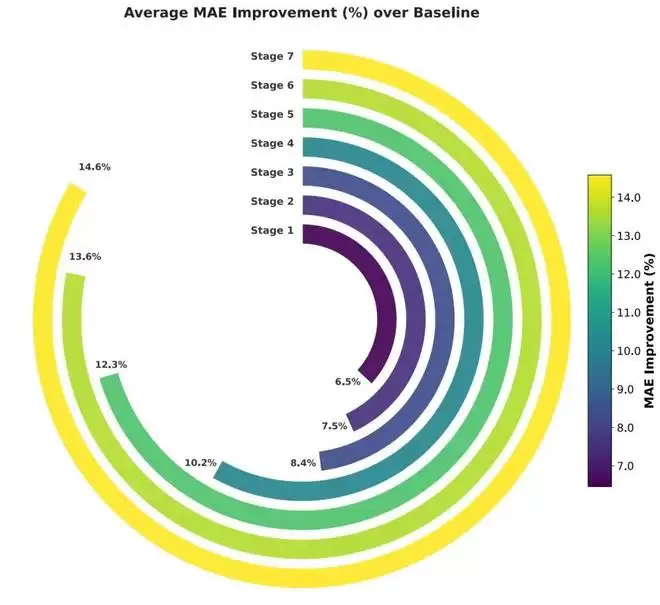
数据侧三次改进使MAE累计降低8.4%;模型结构调整带来12.3%提升;损失函数优化再降1.3%。最终实现14.6%的MAE降低。
AI自主改进的范式正在重塑科研格局,从编码到研究再到自我优化,智能体能力边界加速扩展。递归进化机制将持续推动AI向AGI迈进,这场变革可能比预期来得更快。