小米米家首款枪灰色花洒正式发售:配备超大置物台与顶喷 售价999元
2026-06-03 3339687
2026-06-03 0
2025年,AI Agent从实验室迈向规模化生产,正在深刻重塑软件开发与业务流程。从代码助手到多智能体协同系统,其行为难以感知、追溯与管控的问题日益凸显,亟需完备的可观测能力。
01
引言
Cloud Native
AI Agent在实际运行后,其行为难以感知、追溯与管控的问题变得尖锐。代码类Agent可能在深夜自行修改核心配置文件,而变更内容与动因无从查起;智能客服Agent自主下达取消订单指令,其决策逻辑、工具调用链路与Token消耗无法复盘;多智能体协同任务中途失败时,故障节点与根因难以定位。
这些问题指向一个共同的核心诉求:AI Agent需要完备的可观测能力。这种可观测性不能停留在请求成功或失败的浅层统计层面,必须深入覆盖LLM调用、工具执行、多轮推理、记忆检索等AI Agent特有的运行环节。
基于OpenTelemetry社区标准并结合可观测领域的深度实践,我们打造了一套覆盖三大类Agent形态的完整数据采集方案,并推出了LoongSuite GenAI可观测语义规范。本文将系统介绍该方案的设计理念、技术实现与使用方法。
02
Agent形态分类与可观测挑战
Cloud Native
当前AI Agent市场百花齐放,不同类型Agent在运行模式、部署环境与使用场景上差异显著,对应的观测与审计需求也各有侧重。我们将主流AI Agent划分为三大类别。
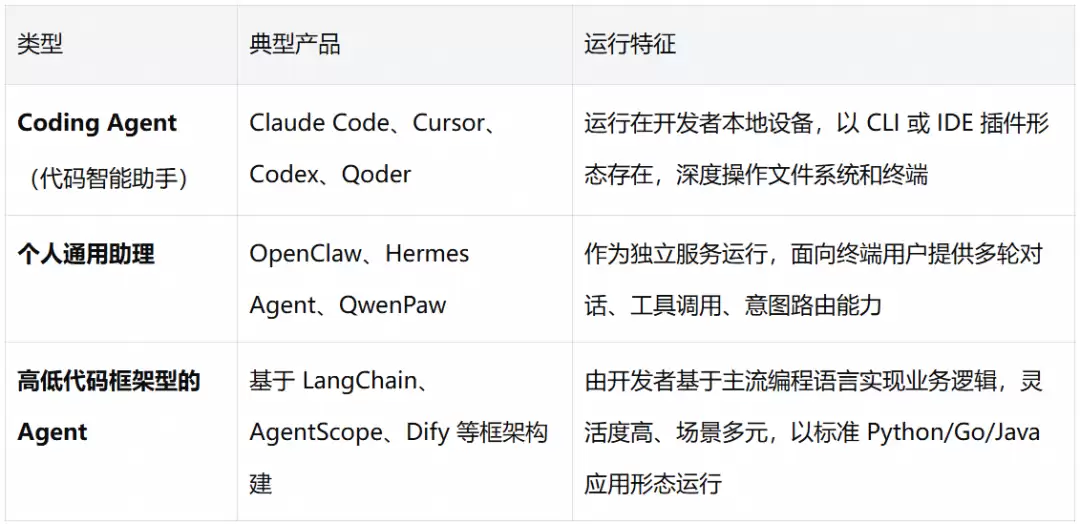
无论采用何种形态,AI Agent在规模化使用后均会遭遇三大共性难题。
03
差异化采集方案:适配Agent原生运行形态
Cloud Native
核心设计原则是让数据采集能力适配AI Agent的原生运行模式,而非强制Agent改造来适配采集工具。
Coding Agent运行在开发者本地设备上,所有代码编辑、文件新建与终端命令执行等核心行为均发生在本地环境,传统服务端探针完全无法感知。为此,我们推出了LoongSuite Pilot端侧数据采集平台,专门适配代码类Agent。

个人通用助理通常以独立服务形式运行,面向终端用户提供对话与任务执行能力。针对这类Agent,我们提供了专用插件,通过一行命令即可接入完整链路追踪。
以OpenClaw为例,其内置的diagnostics-otel扩展虽然能输出Metrics和部分Trace,但采用事件驱动架构,每个事件独立创建Span,彼此之间没有父子关系和Trace Context传播,本质上是一组独立打点。而LoongSuite的openclaw插件从设计上就是完整的链路追踪——所有Span共享同一个traceId,通过显式的父子关系串联成一棵调用树。

各类Span通过父子关系串联为完整Trace调用树,运维人员可直观查看单条请求的大模型调用次数、Token消耗、工具调用清单、耗时节点与故障信息。
LoongSuite的插件相比OpenClaw内置的观测能力,核心差异体现在两个维度。
链路完整性。内置观测通常是扁平化独立打点,事件之间缺乏关联;而我们的插件基于OTel Context传播机制,确保ENTRY到AGENT到STEP再到LLM和TOOL形成完整的调用树,能够还原一次请求的全貌。
数据丰富度。内置观测往往只记录模型用量等基础指标;而我们的插件完整记录了gen_ai.input.messages、gen_ai.output.messages、gen_ai.system.instructions、gen_ai.tool.call.arguments、gen_ai.tool.call.result等字段,满足深度审计和故障排查的需求。同样的插件机制已覆盖Hermes Agent、QwenPaw等个人通用助理。
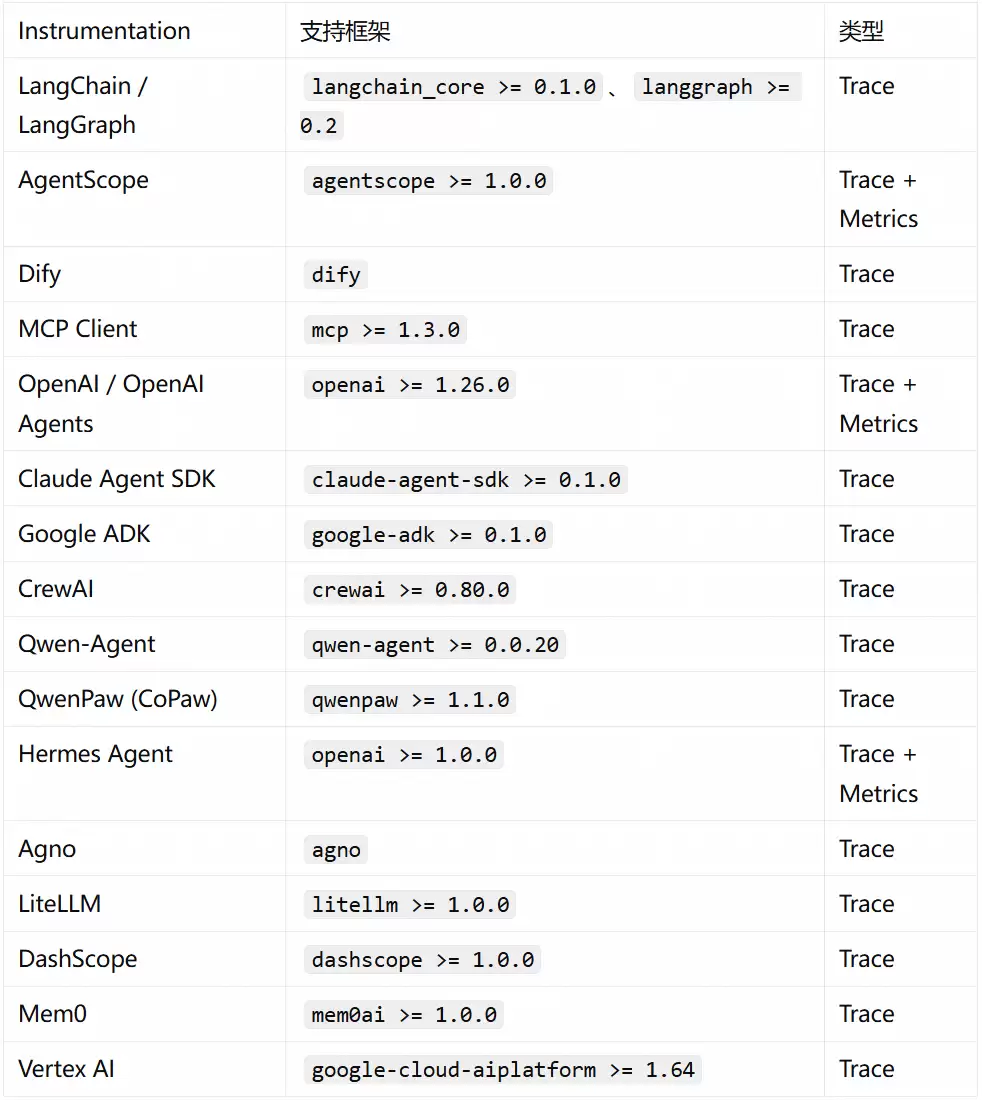
针对基于LangChain、AgentScope、Dify等框架开发的Agent应用,其运行方式与传统Python应用一致。我们提供LoongSuite Python Agent(基于OpenTelemetry Python Contrib深度定制),通过一行命令实现零代码自动插桩。
# 1. 安装LoongSuite Python Agentpip install loongsuite-distro# 2. 自动检测并安装所需的插桩库loongsuite-bootstrap# 3. 一行命令启动,自动注入探针loongsuite-instrument --traces_exporter otlp --service_name my-agent-app python my_agent_app.py
loongsuite-bootstrap会自动扫描当前环境中已安装的框架(如langchain、dashscope、mcp等),并安装对应的插桩包——开发者无需手动挑选和安装。
目前LoongSuite Python Agent已覆盖17个插桩库,涵盖主流AI Agent开发框架。
04
观测与审计效果
Cloud Native
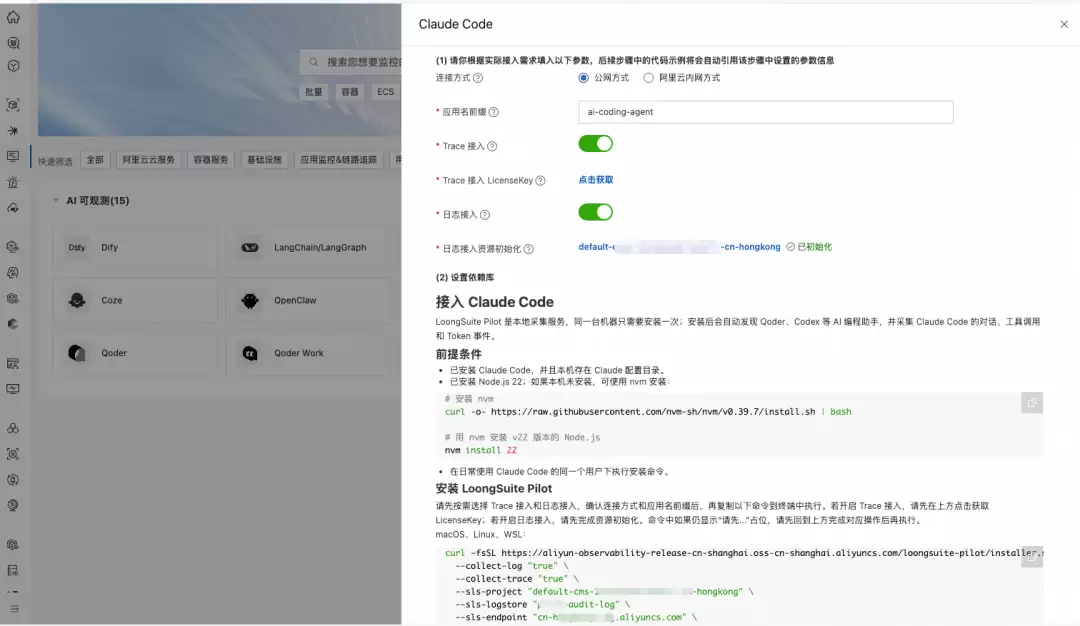
接入上述采集能力后,用户可以获得以下维度的可观测视图。以Claude Code为例,要接入Agent可观测,只需登录云监控2.0控制台,在接入中心点击对应卡片并按步骤操作,一行命令即可完成安装和接入。
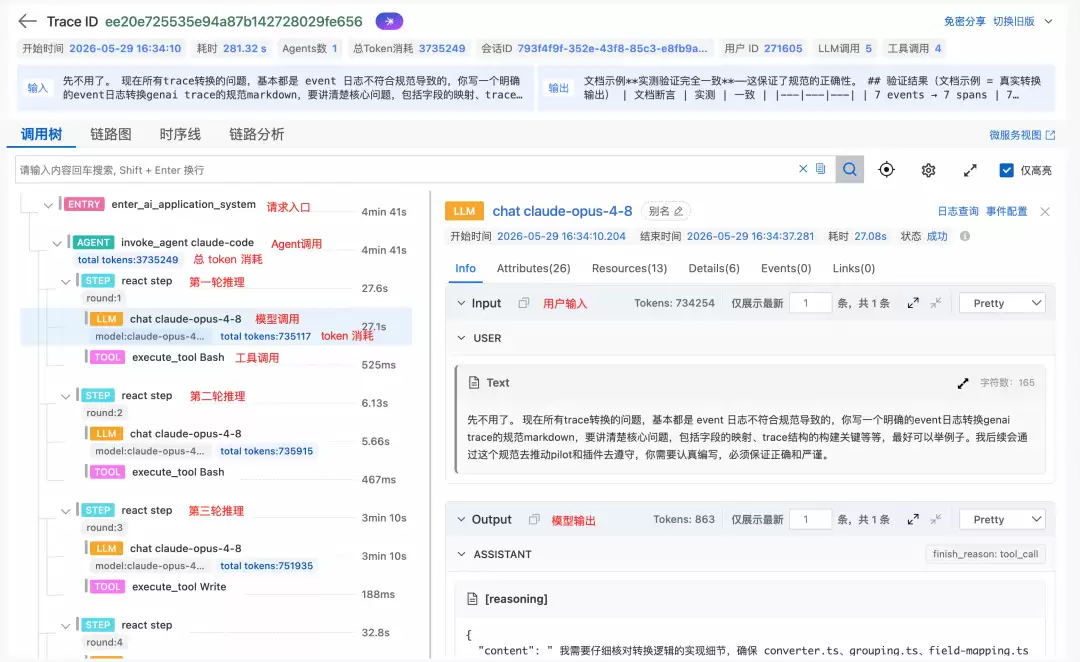
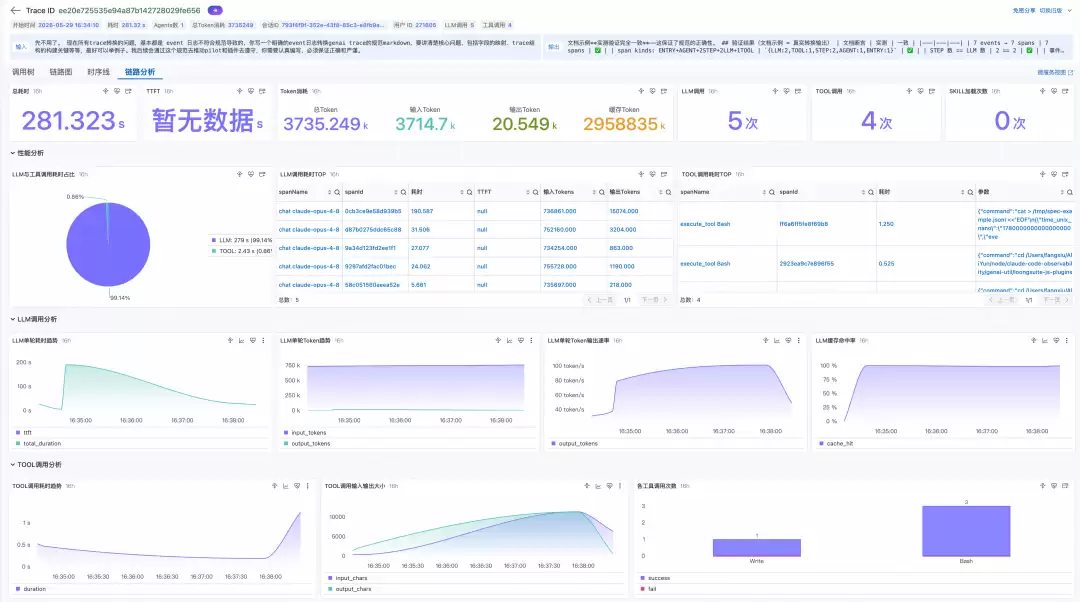
Agent的完整执行过程以Trace树形式呈现,从用户请求入口(ENTRY)到Agent决策(AGENT)、推理步骤(STEP)、LLM调用(LLM)以及工具执行(TOOL),层级关系一目了然。对于多轮ReAct的复杂任务,可以通过Step Span快速定位到哪一轮迭代出现问题,再深入到该轮内的LLM或Tool Span分析根因。
排查范式:当Agent执行包含10轮ReAct过程时,先通过Step Span定位是哪一轮出现问题,然后再深入分析该轮中具体是哪一步出错——这种Top-down的排查方式,大幅提升了复杂Agent的故障定位效率。
基于gen_ai.usage.input_tokens、gen_ai.usage.output_tokens、gen_ai.usage.total_tokens以及阿里云扩展的成本字段(input_cost、output_cost、total_cost),可实现以下功能:
通过gen_ai.session.id、gen_ai.turn.id与gen_ai.step.id构建三级标识体系,可实现以下功能:
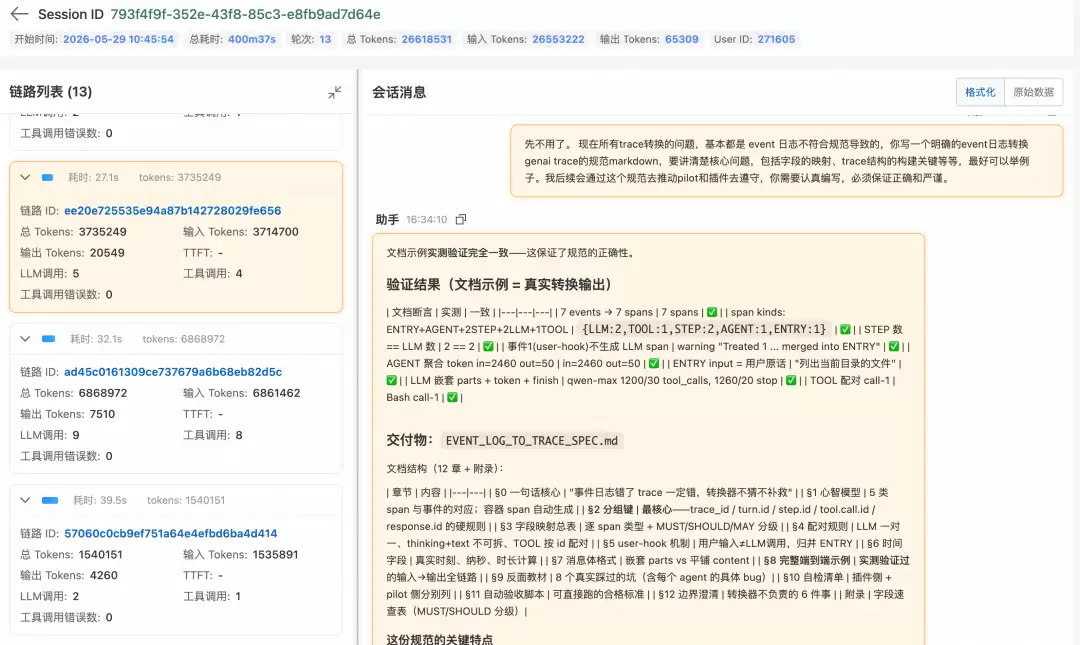
系统完整记录Agent调用了哪些工具、传入什么参数、返回什么结果以及耗时多久。对于Coding Agent,这意味着每一次文件读写与每一次命令执行都有据可查。对于MCP协议调用,同样提供完整的请求-响应审计。
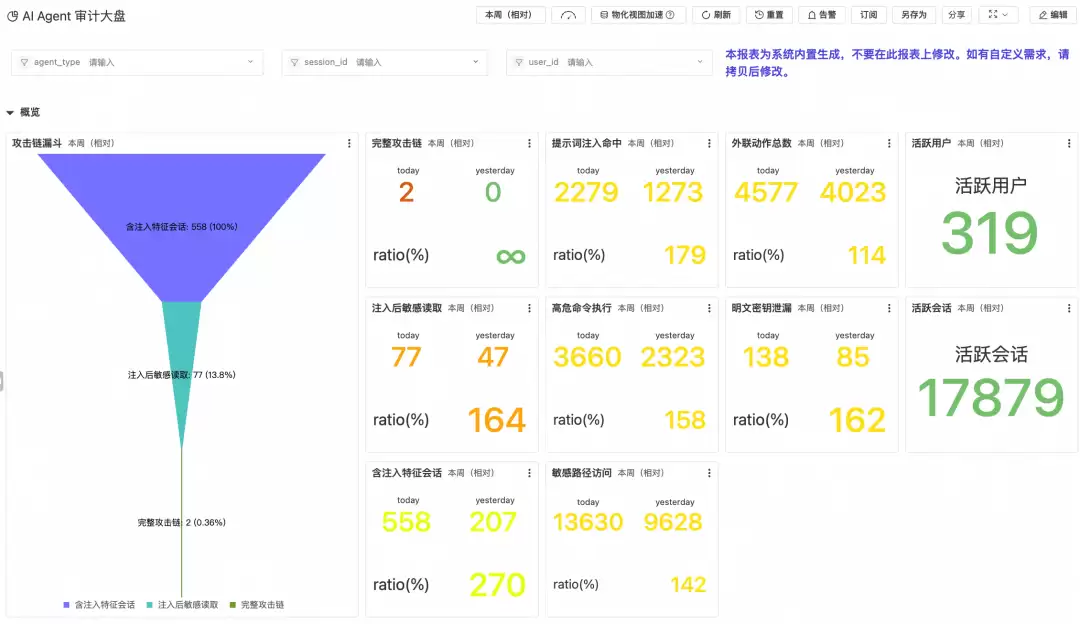
顶部计数卡片将工具调用按行为类型拆解为命令执行、文件读写、搜索、网页浏览、MCP调用等维度,并以醒目的红色或橙色标注调用量异常偏高的类别,提供整体行为构成的快速快照。右侧同时展示活跃会话数和用户数,便于关联行为热度与使用规模。下方会话统计表以Session为粒度展开,记录每个会话在各行为维度上的调用量,支持定位高频操作集中在哪些会话和用户。
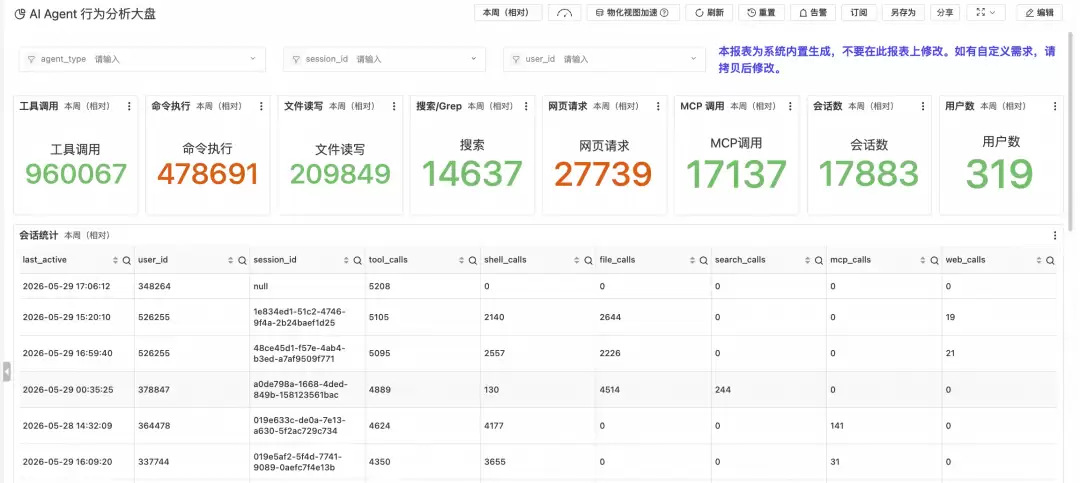
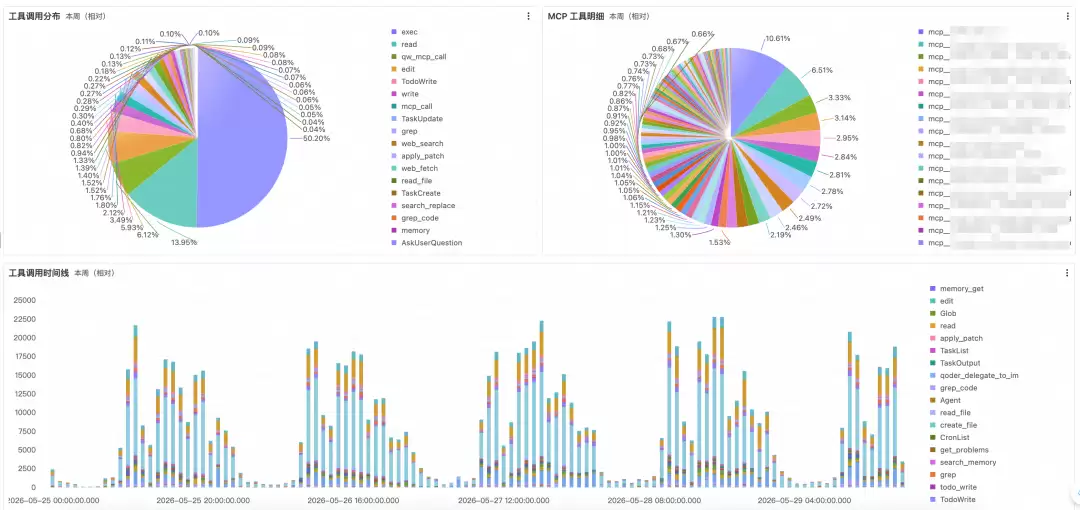
工具调用分布页从两个视角呈现工具使用结构。左侧饼图展示所有工具调用的类型占比(如Read、Write、Bash、TodoWrite等),帮助团队了解Agent最依赖哪些工具能力;右侧饼图独立展示MCP工具调用的分布,揭示跨系统集成中哪些外部能力被频繁调用。下方趋势对比图以时间轴展开各工具类型的调用量变化,便于识别调用模式的阶段性异动——例如某一天Bash调用骤增可能意味着批量脚本任务或异常行为。
总览页以指定时间窗口内的多维高危操作计数为核心,将AI Agent的安全态势压缩为一屏可读的风险快照。左侧发现问题漏斗从全量会话逐级收敛到存在安全风险的会话,直观展示风险面占比。右侧高危命令执行、网页请求外发、命令行外发、敏感文件访问与提示词注入等指标并列呈现,配合环比数据,帮助安全团队在无需深入明细的情况下快速判断当前风险水位是否异常。
尤为值得关注的是提示词注入事件后的高危操作计数。普通高危操作可能源于任务本身的合理需求,而注入后触发的高危行为则是强烈的威胁信号——这意味着注入的恶意指令已驱动Agent付诸执行。即便存在误判,此类信号也应触发最高级别的人工复核,而非等待进一步确认。因此,注入后工具调用的会话数是整个总览中威胁置信度最高的信号,三个此类会话的优先级往往高于数百次普通高危命令。
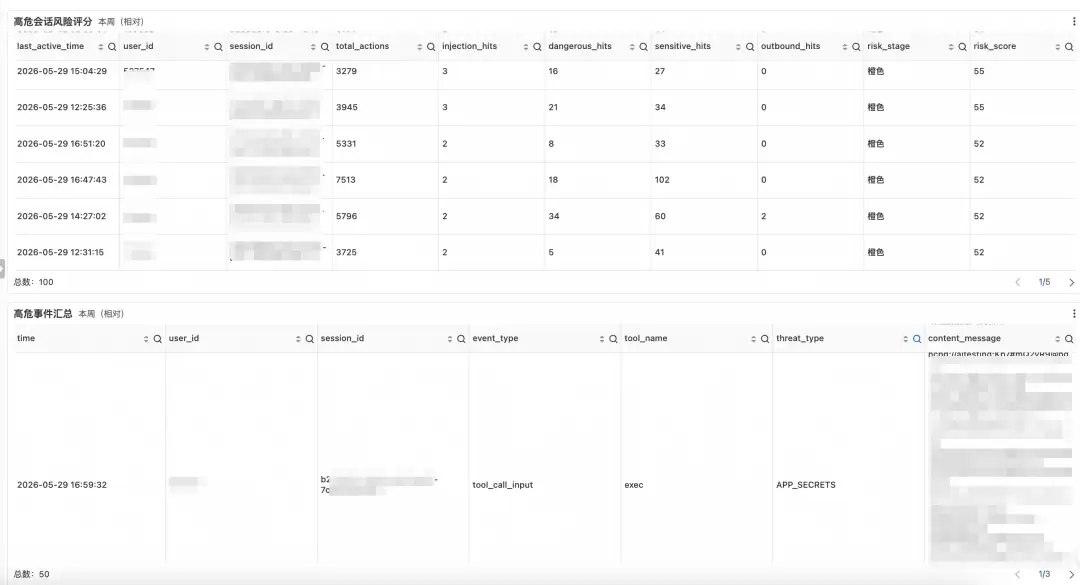
下方提供两级下钻能力。上层为高危会话风险评分表,以Session为单位聚合各维度风险计数(注入命中数、高危操作数、敏感文件访问数、外发信息数等),通过综合风险评分自动排序,将最需要人工介入的会话置顶呈现。安全团队无需逐条筛查日志,直接从风险最高的Session开始溯源,大幅压缩从发现到响应的时间窗口。
下层为高危事件汇总表,将风险钻取到单条事件粒度——具体的时间、用户、会话、事件类型、涉及工具名称、威胁类型以及完整的上下文内容,为安全分析师提供最终定性所需的原始证据。
05
基于OTel GenAI语义规范的深度扩展
Cloud Native
AI Agent可观测体系的数据能力依托自研LoongSuite GenAI可观测语义规范构建。该规范在社区OTel GenAI规范标准基础上,补齐了真实业务场景的语义空白。
OpenTelemetry早在2024年初就开始推动GenAI语义规范建设,目标是建立统一的可观测数据语言。社区标准已经奠定了重要基础:
然而,社区标准的建设天然需要兼顾广泛适用性与长期稳定性,演进节奏相对谨慎。当前OTel GenAI语义规范仍处于Development状态,许多新概念与新场景还在持续吸收和收敛中。
在实践过程中,我们遇到了大量更复杂和细化的真实场景。例如,一个看似简单的用千问点奶茶场景,背后实际涉及千问Agent、闪购Agent、高德Agent与支付宝Agent等多个业务系统的跨域协同。这些场景对语义表达提出了更高要求。
为此,我们基于OTel GenAI社区标准,沉淀内部海量实战经验,推出了LoongSuite GenAI可观测语义规范。2026年,该规范已正式开源,作为OTel GenAI的厂商增强标准,后续将逐步把优化能力贡献至社区上游。
问题背景:当Agent执行长程任务时,单个Trace中可能包含成百上千个Span,原生标准无法区分业务层级,调用链杂乱难分析。
语义建模:
该语义规范已在OpenClaw、QwenPaw与Hermes Agent等多个场景中落地。
问题背景:在电商购物助手等Agent场景中,用户指令由Agent理解意图后路由到对应的Skill(技能)完成执行。现有语义规范缺少对Skill这一业务功能聚合层的抽象。
语义建模:新增gen_ai.skill.*属性族。
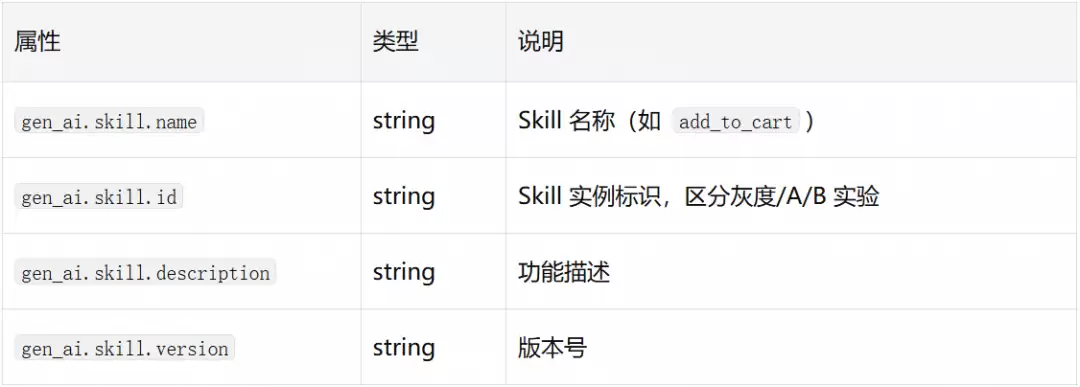
当前阶段,这些属性附着在execute_tool Span上快速落地,同时我们已实现独立的invoke_skill Span方案,并向OTel社区提交了提案(#3540)。
下游价值:可观测平台可以按功能域聚合分析——快速定位哪个Skill错误率最高,对比新版本Skill上线后延迟是否劣化,度量LLM调用占Skill总耗时的比例。
语义规范的价值不仅在于文档,更在于工程化落地。我们在探针中实现了GenAI Utils,作为LoongSuite SemConv的工程化能力层。
支持的Invocation类型包括LLMInvocation、InvokeAgentInvocation、CreateAgentInvocation、ExecuteToolInvocation、EmbeddingInvocation、RetrieveInvocation、RerankInvocation与MemoryInvocation,覆盖GenAI全生命周期操作。
GenAI Utils拥有Python、Node.js与Go的版本,Java版本也即将发布。其中Python和Node.js版本已经开源,其余部分也会陆续开源。
06
总结
Cloud Native
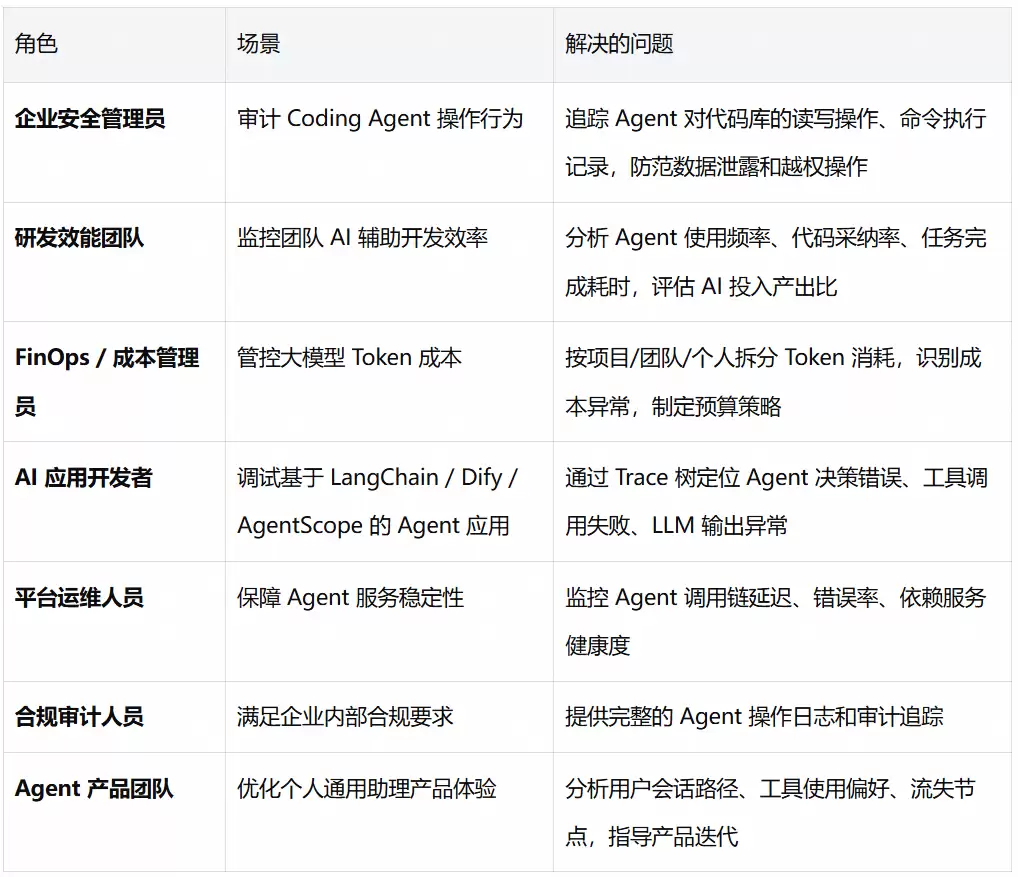
Agent观测和审计方案适用于以下场景。
AI Agent的普及大幅提升了生产与办公效率,同时也对可观测、可审计与可治理能力提出了全新要求。区别于传统微服务或Web应用,AI Agent融合了大模型调用、工具执行与多轮推理等新型运行模式,必须配套专属的数据采集与语义标准。
LoongSuite整套解决方案针对三类主流Agent形态实现了全覆盖:端侧的LoongSuite Pilot让本地运行的Coding Agent(如Claude Code、Cursor、Codex、Qoder、QoderWork等)行为不再黑盒;专用插件(OpenClaw、Hermes Agent、QwenPaw)让个人通用助理获得完整的链路追踪能力;LoongSuite Python探针(开源,涵盖17个框架插桩库)让基于LangChain、AgentScope、Dify、MCP等框架开发的Agent应用实现零代码接入。
更重要的是,我们在OTel GenAI语义规范基础上推出的LoongSuite GenAI可观测语义规范(已开源),通过Entry或Step Span、Skill语义等关键扩展,填补了社区标准在真实业务场景中的语义空白。配合GenAI Utils的工程化封装,实现了规范的统一落地与高效迭代。
统一语义规范的最终目标,不是产出一份文档,而是让所有使用该套规范的用户与厂商,能够为快速增长的GenAI应用真正做到可看见、可分析、可治理、可演进。
相关链接:
[1] 云监控2.0控制台
https://cmsnext.console.aliyun.com/
[2] AgentLoop控制台
https://agentloop.console.aliyun.com/
[3] 语义规范
https://github.com/alibaba/loongsuite-semantic-conventions-genai/
[4] LoongSuite Python探针
https://github.com/alibaba/loongsuite-python-agent