ClawHub产线落地技能的识别指南
2026-06-07 3345072
2026-06-07 0
原创 郑佳美 2026-06-06 18:03 广东
2026 年 6 月 1 日,国际机器人与自动化会议(ICRA)在奥地利维也纳召开。次日上午的自动驾驶与导航报告环节,雷峰网GAIR 2021大会嘉宾、上海交通大学教授王贺升发表了题为《Learning to Navigate: From Scene Understanding to Decision Makin》的演讲。
3D 视觉研究正在从“重建形状”走向“理解空间”。过去,一个模型只要能生成外观合理的三维物体,就已经足够令人关注。
但现在,真正重要的问题正在变得更复杂:模型能否判断一个物体内部哪些部件可以运动,能否理解动态物体在时间中的几何和外观变化,能否在多视角重建中兼顾精度与效率,甚至能否读懂复杂的 3D 几何论文并写出可复现的研究代码。
这种转变也体现在 CVPR 2026 相关研究所关注的问题上。研究者不再只满足于让 AI 生成一个静态 3D 模型,而是希望它进一步理解物体的结构、运动方式、时空表示和计算过程。
一个抽屉不只是一个长方体,而是应该知道它可以沿轨道滑动;一个动态物体不只是连续的几帧形状,而是需要被统一表示和长期追踪;一个 3D 基础模型也不只是越大越好,还必须在实际场景中高效、稳定地运行。
更深层来看,3D AI正在从单点能力走向系统能力。它不仅要回答“物体长什么样”,还要回答“它怎么动”、“如何被重建”、“如何高效运行”、“如何被研究者复现和扩展”。当这些能力逐渐连在一起,3D 模型才更接近真正可用的空间智能系统,也更接近机器人、仿真、数字孪生和生成式 3D 内容所需要的核心基础。

01
《PARTICULATE: Feed-Forward 3D Object Articulation》关注的是 3D 物体自动关节化问题,相关研究来自牛津大学、剑桥大学和南洋理工大学。
论文主要研究如何从一个静态 3D 网格中,自动推断出物体的可动结构,包括物体由哪些可动部件组成、这些部件之间如何连接,以及它们分别沿着什么方向旋转或滑动。
这项任务的意义在于,很多现实物体并不只是“有形状”,还具有可运动的结构。比如柜门可以旋转打开,抽屉可以沿轨道滑动,水龙头、椅子、行李箱等物体也都有不同形式的可动部件。
对于机器人操作、物理仿真、游戏资产和数字孪生来说,仅有一个静态 3D 模型是不够的,还需要知道这个物体“哪里能动、怎么动、动多少”。
以往的方法往往依赖规则建模、部件检索,或者针对单个物体进行优化,推理速度慢,也很难覆盖真实世界中种类丰富的物体。

论文地址:https://arxiv.org/pdf/2512.11798
针对这一问题,论文提出了 PARTICULATE 框架,它可以在一次前向推理中,从输入的 3D mesh 直接预测完整的关节结构,并在数秒内生成一个可用于物理引擎的可动 3D 模型。
方法上,论文设计了 Part Articulation Transformer,也就是 PAT。它会先从输入 mesh 中采样点云,并结合表面法向量和 PartField 提取的 3D 语义部件特征,然后通过 Transformer 结构和多个解码头,同时预测部件分割、运动学树、关节类型、运动轴和运动范围。也就是说,模型不仅要把物体切分成不同部件,还要判断这些部件之间的父子关系,以及每个部件是旋转、平移,还是固定不动。
论文还构建了一个新的 3D 关节估计评测基准,包含 243 个高质量 3D 资产,并重新设计了更符合人类偏好的评估方式。实验中,PARTICULATE 在静态 3D mesh 的可动结构恢复任务上明显优于已有方法,并且能够泛化到未见过的物体,甚至可以处理 AI 生成的 3D 资产。
这篇论文的亮点在于,它把 3D 模型从“静态形状”进一步推向“可交互对象”。过去,一个 3D 生成模型可能只能生成一个外观合理的物体,而 PARTICULATE 试图进一步让模型理解物体内部的可动结构。
它不仅能告诉模型“这个物体长什么样”,还能让模型知道“这个物体应该怎么动”。这对于机器人操作、仿真环境、游戏制作和 AI 生成 3D 内容都有很强的实用价值。

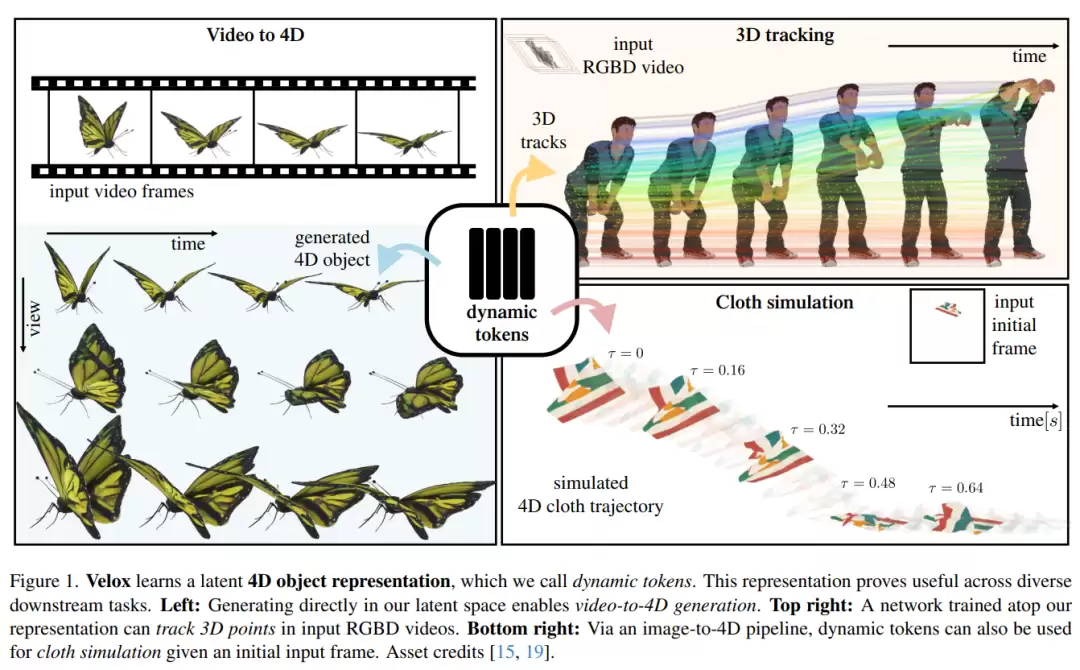
如果说 PARTICULATE 更关注静态 3D 物体内部的“可动结构”,那么《Velox: Learning Representations of 4D Geometry and Appearance》则进一步把视角扩展到时间维度,研究物体在运动过程中的几何和外观变化。相关研究来自苹果公司和多伦多大学,论文关注的是 4D 动态物体表示学习问题。
论文主要研究如何为随时间变化的 3D 物体学习一种紧凑、通用的表示,使模型能够同时捕捉物体的几何结构、外观信息和时间变化。这里的 4D 可以理解为“三维空间加时间”,也就是不仅要知道物体长什么样,还要知道它如何运动。
以往的 3D 或 4D 表示方法往往只服务于单一任务,或者需要提前知道不同时间点之间的点对应关系,因此泛化能力有限。针对这一问题,论文提出了 Velox 框架,将输入的时空彩色点云压缩成一组 dynamic tokens,用这些紧凑表示来概括整个动态物体。论文中提到,这种方式可以实现超过 30 倍的压缩,并且不需要把时间对应关系作为输入。

论文地址:https://arxiv.org/pdf/2605.04527
方法上,Velox 使用类似 Perceiver IO 的编码器,从无结构动态点云中提取时空信息,再通过两个解码器分别建模几何和外观。
其中 4D surface decoder 负责恢复随时间变化的物体表面,Gaussian decoder 则将 dynamic tokens 映射成 3D Gaussians,用于恢复外观细节。也就是说,Velox 不是逐帧处理 3D 物体,而是学习一个贯穿时间的统一动态表示。
论文将这种表示应用到 video-to-4D 生成、3D 跟踪和布料仿真等任务中。实验结果显示,Velox 在动态物体重建、新视角生成和 3D 跟踪等方面表现较好,能够把时间、运动、几何和外观统一到一个紧凑表示中。
这篇论文的亮点在于,它把 3D 生成从“静态形状”推进到“动态世界建模”。Velox 不只是重建一个会动的物体,而是学习一种可以复用的 4D 表示,让模型更好地理解物体在时间中的运动和变化。这对于 4D 生成、动态数字资产、机器人感知和仿真任务都有重要意义。
在 3D 和 4D 模型能力不断增强的同时,推理效率也成为实际应用中绕不开的问题。《HeSS: Head Sensitivity Score for Sparsity Redistribution in VGGT》关注的正是 VGGT 模型的高效推理,相关研究来自首尔大学。论文主要研究如何在多视角 3D 重建中降低 VGGT 全局注意力层的计算开销,同时尽量避免精度下降。
VGGT 依靠全局注意力来理解多张图像之间的几何关系,但注意力计算成本会随着输入视图数量增加而快速上升,这限制了它在大规模或实时 3D 重建场景中的应用。
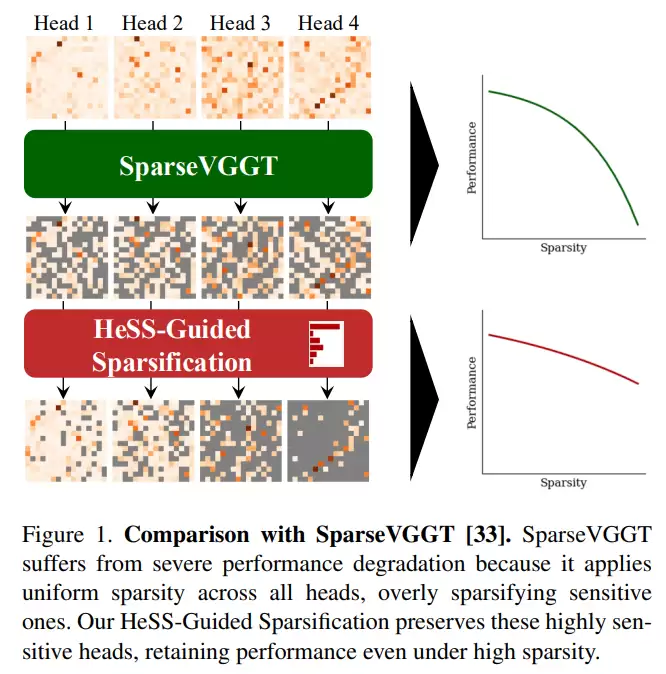
以往的稀疏化方法通常会对所有注意力头使用相同的稀疏策略,也就是统一减少注意力计算。但论文指出,不同注意力头对稀疏化的敏感程度并不一样。有些头对相机位姿、点云结构等几何信息非常关键,如果被过度稀疏化,模型性能会明显下降;而有些头相对不敏感,可以承受更高程度的稀疏。

论文地址:https://arxiv.org/pdf/2603.25336v1
针对这一问题,论文提出了 HeSS,也就是 Head Sensitivity Score,用来衡量每个注意力头对稀疏化的敏感程度。它通过一个小规模校准集,结合相机位姿误差和点云误差两个指标,近似估计每个注意力头的重要性。这样模型就可以知道哪些头需要保留更密集的注意力计算,哪些头可以进一步稀疏化。
方法上,论文采用两阶段流程。第一阶段是离线校准,计算每个注意力头的 HeSS 分数;第二阶段是在推理时根据这些分数重新分配注意力预算。也就是说,总计算量不一定增加,但会把更多预算分给敏感头,把更少预算分给不敏感头,从而在保持加速效果的同时减少重建质量损失。
这篇论文的亮点在于,它不是简单地“统一压缩”模型,而是根据不同注意力头的重要性进行更精细的稀疏化分配。实验结果显示,HeSS 能够有效捕捉全局注意力层中不同头的敏感差异,在高稀疏率下比 SparseVGGT 更好地保持相机位姿估计和点云重建质量,并且可以推广到其他基于 VGGT 的结构中。
总体来看,这篇论文的核心贡献是让 VGGT 这类 3D 视觉基础模型在保持几何精度的同时变得更高效。它说明模型加速不能只看计算量,还要理解模型内部不同模块对任务结果的影响。对于多视角 3D 重建、实时空间感知和大规模 3D 场景建模来说,这类“精度友好型加速”方法具有较强的实用价值。
当 3D 视觉模型越来越复杂,另一个问题也随之出现:大语言模型能不能真正帮助研究者理解并实现这些几何算法。
《Benchmarking PhD-Level Coding in 3D Geometric Computer Vision》关注的是 3D 几何视觉中的高难度代码生成评测问题,相关研究来自清华大学人工智能产业研究院、清华大学求真书院、北京智源人工智能研究院、北京大学、南京大学和多伦多大学。
论文主要研究的是:当大语言模型读到一篇 3D 视觉论文和相关代码框架时,能否真正理解其中的几何算法,并写出可以运行、可以通过单元测试的研究级代码。
这项工作的背景在于,AI 辅助编程已经在通用软件开发中表现较强,但 3D 几何视觉代码并不只是普通编程。它往往涉及坐标变换、相机投影、点云处理、物理或光学公式、渲染逻辑以及多视角几何关系。
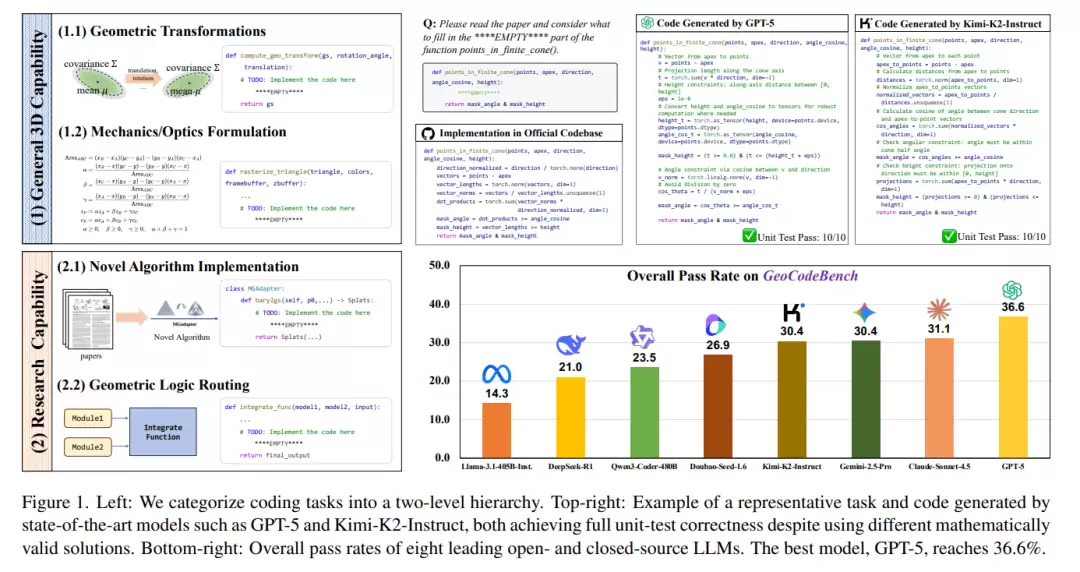
如果模型只是“会写代码”,但不能准确理解论文中的数学定义和几何约束,就很容易写出看似合理、实际错误的实现。为了解决缺少专业评测的问题,论文提出了 GeoCodeBench,这是一个面向 3D 几何视觉的博士级代码生成基准。
每个任务都来自真实 3D 视觉论文及其官方代码仓库,形式是给模型论文内容和一个被挖空的函数,让模型补全核心实现,再通过单元测试判断代码是否正确。这个设定更接近真实科研场景:模型不仅要读懂论文,还要把方法转化成可执行代码。

论文地址:https://arxiv.org/pdf/2603.30038v1
在数据构建上,GeoCodeBench 从 CVPR 2025、ICCV 2025 和 ICLR 2025 的 47 个代码仓库中筛选出 100 个高质量问题,覆盖 Gaussian Splatting、姿态估计、SLAM、重建、NeRF、物理建模和 3D 分割等方向。
任务被分为两大能力:一类是通用 3D 能力,包括几何变换和力学 / 光学公式实现;另一类是科研能力,包括新算法实现和几何逻辑组合。
论文还设计了自动化评测流程。系统会解析论文内容、提取代码函数、生成被挖空的实现模板,并为每个问题构建覆盖普通情况和边界情况的单元测试。模型生成代码后,直接在测试环境中运行,用通过率衡量结果。这种方式比只看自然语言回答更严格,因为代码必须真正执行正确,才能算通过。
实验结果显示,当前大模型在这类任务上仍有明显差距。论文评测了 8 个开源和闭源模型,其中表现最好的 GPT-5 总通过率也只有 36.6%。结果还显示,模型在基础几何和数学公式类任务上相对更好,但在论文特定的新算法实现和几何逻辑组合上明显更弱,说明它们距离可靠完成 3D 科研级编程还有很大空间。
这篇论文的亮点在于,它把大模型代码能力评测从通用编程推进到了更接近科研现场的 3D 几何视觉场景。
GeoCodeBench 不只是考模型会不会写 Python,而是考它能不能读懂论文、理解几何关系、实现核心算法并通过可复现测试。总体来看,这项工作为评估和推动“自动化 3D 视觉研究助手”提供了一个更严格、更真实的测试平台。
02
为了让国内的研发者、创业者与投资人能够毫无时差地掌握本届 CVPR 2026 的完整干货,雷峰网已全面上线【CVPR 2026 深度专区】。
专区不仅全面收录了重磅论文的工程化解读、专家前沿演讲,更将持续更新前方记者的第一手会议动态。
扫描下方二维码,或点击「阅读原文」关注专区。

与全球 8000 名顶尖大脑同步呼吸,抢先透视具身智能的下一个五年!

//
推荐阅读

CVPR 2026 三维视觉趋势梳理:从 RGB 感知,到真实世界建模

CVPR 2026 医学影像 AI 趋势梳理:从看懂影像,到接管科研工作流
未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。
阅读原文