高通推出骁龙START计划 推动个人AI终端加速落地
2026-06-20 3361915
2026-06-19 0
魔搭ModelScope社区 2026-06-18 15:22 美国

EBench发布通用具身操作评测体系,Qwen-RobotManip在多维诊断中登顶,总分领先并在移动/精细操作/长短程任务中表现均衡,但高精度与长尾任务仍具挑战,展示了更结构化的能力评估与模型对比方法。
通用具身操作模型的竞争,正在从“谁的总分更高”,走向“谁的能力结构更完整”。
近日,Qwen-RobotManip在EBench Generalist Test上取得45.6% Test SR与60.8% Test Score,在当前所评测模型中排名第一。相比Lingbot-VA,在Test SR和Test Score上分别领先约14.7与13.1个百分点。
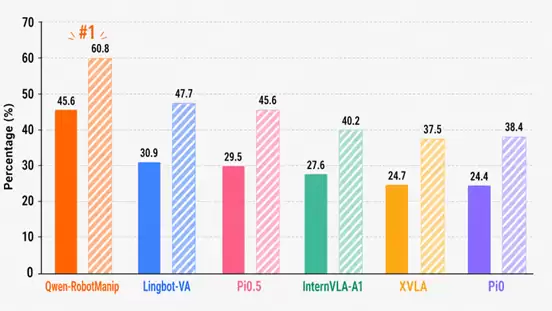
EBench榜单
关于EBench
EBench是面向通用具身操作模型的多维评测平台,覆盖长程任务、精细操作与移动操作,区别于仅以整体成功率衡量模型表现的传统评测基准,EBench面向模型研发中的可复现评测、能力诊断与泛化分析需求,构建了标准化任务库、多维标签体系、训测隔离机制和在线评测平台。
当前,EBench包含26种任务、510条测试数据,能够从场景、原子技能、任务时长、操作精度和操作模式五个维度生成能力画像,并围绕物体、背景、指令和组合扰动四类分布外情境评估模型泛化能力。现已开源分布式评测工具,支持8卡4090在30分钟内完成验证集评测,实现快速迭代;同时提供7×24小时在线评测平台,所有提交均基于可复现的标准化协议执行。每次测试完成后,评测工具能够自动生成结构化诊断报告,包含五维能力画像、训练集到测试集的能力迁移曲线、泛化维度雷达图及任务级热力图。模型开发者可以快速判断短板来自移动操作还是桌面精细控制,来自新物体泛化还是长程规划,从而更有针对性地推进模型迭代。
此外,EBench通过严格的物体级训测隔离机制,进一步区分模型是在真正泛化,还是仅仅适应已知分布。其验证集同时包含已见任务与未见任务,测试集则作为隔离评测集合,用于在分布外情境中考察模型对新物体、新场景和新任务组合的真实适应能力。值得注意的是,在这一标准化隔离机制下,有无大规模预训练的模型在EBench上呈现出更明显的性能差异;而在LIBERO、RoboTwin 2.0等既有评测基准中,这种差异并不显著。这表明,EBench能够更敏感地捕捉预训练对通用具身操作能力的影响,为研究者分析模型泛化边界和预训练收益提供更具诊断价值的评测依据。更具体的实验分析可参见EBench技术报告。
相关链接:
技术报告链接:
https://arxiv.org/pdf/2606.18239
项目开源地址:
https://github.com/InternRobotics/EBench
评测集ModelScope下载链接:https://modelscope.cn/datasets/InternRobotics/EBench-Dataset
在线仿真评测平台:
https://internrobotics.shlab.org.cn/eval
从五维能力看Qwen-RobotManip:不是单点冲高,而是能力结构更完整
EBench的核心设计之一,是将具身操作能力拆解为Operating Mode、Horizon、Precision、Atomic Skill、Scene五个维度,而不是仅用一个平均成功率评价模型。这样的设计使榜单结果不止回答“谁排第一”,也能进一步解释模型优势来自哪里、短板出现在哪里。
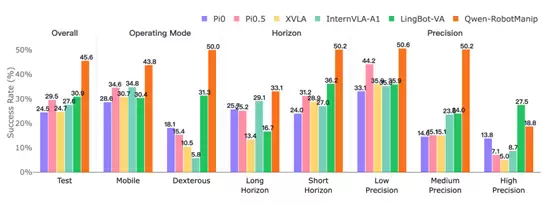
Qwen-RobotManip在操作模式、任务长度和精度维度上表现出强劲性能,而高精度操控仍然具有挑战性
从整体结构看,Qwen-RobotManip的表现并非由单一任务类型拉动。在Operating Mode上,Qwen-RobotManip在移动操作中达到SR 43.8%,说明其在需要结合移动、观察与操作的任务中表现较好;同时,在固定场景下的精细操作中也处于领先地位,达到SR50.0%。任务时间尺度上的结果进一步补充了这一观察:Qwen-RobotManip同时刷新了短程和长程任务表现,其中Short Horizon达到SR 50.2%,Long Horizon达到SR 33.1%。短程任务更能反映模型对目标、动作和局部状态的即时响应能力;长程任务则会放大目标保持、步骤衔接和误差累积问题。Qwen-RobotManip在两类任务中同步提升,说明本次领先并不是依靠“更容易完成的短任务”拉高总分,而是在更完整的任务链条上也体现出较稳定的执行能力。
在精度维度上,Qwen-RobotManip的提升主要集中在低中精度任务,分别达到SR 50.6%和50.2%。这表明其在需要一定操作精度和接触稳定性的任务中表现较好。不过,高精度仍是明显短板。Qwen-RobotManip在High Precision上达到SR 18.8%,虽高于大多数baseline,但低于LingBot-VA的27.5%,说明高精度操控仍然具有挑战性,也显示不同模型的能力结构并不完全一致。
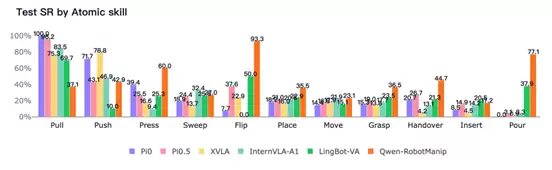
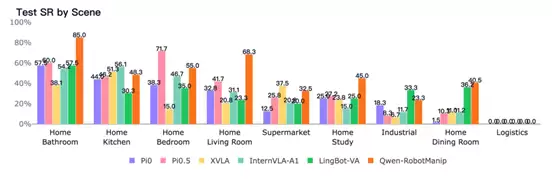
Qwen-RobotManip在原子操作技能和家庭场景上的覆盖更广,而部分原子技能和长尾场景仍具有挑战性
更细粒度的原子技能结果显示,Qwen-RobotManip在Flip、Pour、Press、Handover、Grasp、Place、Move等多类技能上取得领先或接近领先,体现出较广的日常操作技能覆盖。尤其在Flip、Pour、Press、Handover等技能上,Qwen-RobotManip与其他模型拉开了较明显差距。与此同时,这一维度也揭示了清晰的短板:Qwen-RobotManip在Pull、Push、Sweep、Insert等技能上并非最优,其中PullPi0表现更好,PushXVLA指标更优,Sweep InternVLA-A1得分最高,Insert则是LingBot-VA表现更好。
这种技能覆盖也反映到场景表现中。Qwen-RobotManip在Home Bathroom、Home Living Room、Home Study、Home Dining Room等家庭场景中表现较好,说明其在生活类场景中的任务适应性较强。但在Industrial、Logistics等场景中,Qwen-RobotManip的优势并不稳定;尤其Logistics场景中,各模型整体表现仍然很低,反映出长尾场景和非家庭场景仍有较大提升空间。
综合五个维度来看,本次结果显示Qwen-RobotManip不仅取得总分领先,也在移动操作、固定操作、长短程任务、低/中精度操作、多类原子技能和多个家庭场景中呈现出较好的整体表现。与此同时,高精度操作、Pull / Push / Sweep/insert等特定原子技能,以及工业/物流场景等结果也标出了下一阶段需要继续突破的能力边界。
泛化表现更均衡:四类扰动下几乎无明显下降
除了任务类型,EBench还重点考察模型在不同分布变化下的泛化能力。本次结果显示,Qwen-RobotManip在Background、Instruction、Object、Mix四类泛化设置中表现较为均衡,分别达到约45.3%、45.3%、44.5%和46.8%。相比部分基线在Object或Mix扰动下明显下降,Qwen-RobotManip在四类扰动之间波动很小,说明其表现并不集中在单一变化类型上,而是在背景变化、指令改写、物体替换和组合扰动下都保持了相对稳定的任务完成能力。
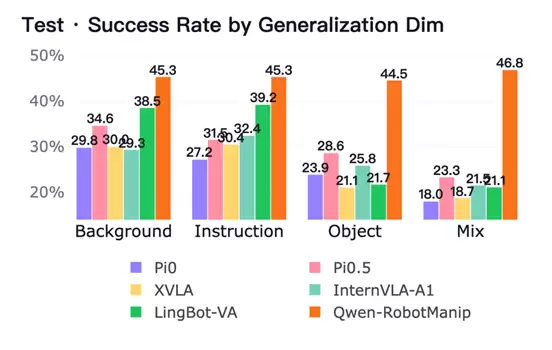
Qwen-RobotManip在Background、Instruction、Object和Mix四类扰动下均表现稳定
这一点也使Qwen-RobotManip与LingBot-VA呈现出不同的能力结构。LingBot-VA在Background和Instruction上表现较强,分别达到38.5%和39.2%,但在Object和Mix上下降到21.7%和21.1%,说明其对物体替换和组合扰动仍较敏感。相比之下,Qwen-RobotManip在四类扰动下几乎没有明显退化,显示出更平坦的泛化曲线。此外,Pi0.5的泛化表现也相对均衡,但整体水平仍低于Qwen-RobotManip。
任务级观察:日常操作任务提升明显,长尾难题仍未解决
从任务级热力图看,Qwen-RobotManip在多个移动与日常操作任务中达到或超过现有基线,尤其是在需要物体识别、抓取、移动、放置、翻转、倾倒和多阶段执行的任务上表现较好。这与前文五维诊断中的观察一致:Qwen-RobotManip的提升更多体现在日常操作技能和家庭场景覆盖上。
与此同时,EBench的任务级诊断也显示,当前模型在shop、bottle等任务中仍有较大提升空间,这两个任务中所有模型包括Qwen-RobotManip和LingBot-VA仍几乎为0。部分任务如collect_coffee_beans、pen等也仍处于较低水平。值得注意的是,LingBot-VA在microwave、peg_in_hole、flip_cup_collect_cookies等任务上体现出一定差异化优势,说明不同模型仍存在明显互补性。高精度、长尾、细粒度桌面操作,以及部分长程移动任务,仍是现有模型需要持续突破的方向。
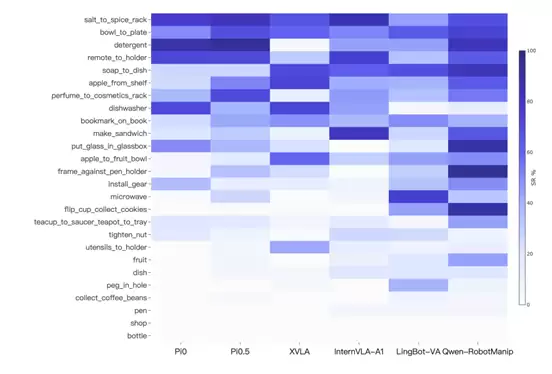
任务级热力图对比:Qwen-RobotManip在多个日常操作任务上取得提升,但高精度和长尾任务仍存在挑战
?点击关注ModelScope公众号获取
更多技术信息~