高通推出骁龙START计划 推动个人AI终端加速落地
2026-06-20 3361915
2026-06-19 0
原创 NLPer 2026-06-18 15:34 江苏

Reason Only When Needed: Efficient Generative Reward Modeling via Model-Internal Uncertainty

论文题目:Reason Only When Needed: Efficient Generative Reward Modeling via Model-Internal Uncertainty
收录会议:ACL 2026
arXiv 链接:https://arxiv.org/abs/2604.10072
作者单位:腾讯混元 & 新南威尔士大学(UNSW)
领域:LLM 高效推理 / 生成式奖励模型 / 推理优化
关键词:E-GRM, Dynamic CoT Trigger, Model-Internal Uncertainty, Discriminative Scoring, GRM, Efficiency, Reward Fidelity
大语言模型在参数规模持续增长的趋势下,每一次推理调用的计算成本已经不容忽视。腾讯混元和新南威尔士大学在ACL 2026上提出了E-GRM(高效生成式奖励模型)框架,揭示了推理效率优化的新思路:**与其让推理更快,不如让模型先判断"是否值得推理"**。E-GRM利用模型自身的解码不确定性作为路由信号,动态决定是否需要投入完整的思维链推理。实验数据显示,这一方案在当前主流的奖励模型评估基准上实现了效能双升——效率大幅提升的同时精度也获得改善。
当前奖励模型领域存在两个值得质疑的默认假设。假设一:评估每个响应都需要完整的思维链推理。假设二:多数投票是从多条推理链中选出最佳答案的可靠方式。
E-GRM的设计者认为,这两个假设都需要被修正。58%的输入其实不需要深度推理,而投票机制会抹平推理路径之间的质量差异。
E-GRM的核心是一个简洁的动态路由机制,在完整推理之前先进行一次快速的不确定性评估。
图1:E-GRM框架示意图,展示动态路由与判别式评分的整体流程。
对输入 进行 次并行解码,每次使用不同的采样参数(如温度0.7、0.8、0.9,top-p 0.9、0.95等),得到初始响应集合。通过计算这些响应的共识度来量化模型对问题的把握程度:
共识度本质上衡量的是模型输出的一致性。从理论上说,它等价于在离散输出空间上对模型置信度的简化估计。如果模型对某问题有明确的答案,多次采样必然收敛;如果模型需要反复推理才能得出结论,采样结果就会分散。
阈值 意味着在 的条件下,至少4/5的解码结果一致才被视为"可在短路径中安全处理"。
从统计学角度看,共识度可以视为对多次二项试验中"最频繁答案"出现频率的估计。假设模型对问题 有真实置信度 ,则 次解码中多数答案出现的次数服从二项分布 。当 时,假阳性率(简单问题被误判为复杂)为 ,假阴性率(复杂问题被误判为简单)为 。两个错误率均处于可接受范围。
从信息论角度,共识度与条件熵 呈单调负相关。这意味着共识度天然携带了关于模型对问题认知状态的信息,无需额外标注即可获得。
E-GRM的设计与Kahneman提出的双系统理论(Dual Process Theory)高度契合:短路径对应系统1(快速、直觉、低能耗),长路径对应系统2(缓慢、分析、高能耗)。共识度在这里扮演了系统1"信心阈值"的角色——当系统1信心足够(共识度≥0.8)时,系统2不需要介入。这一类比不仅为E-GRM提供了认知科学层面的合理性,也为未来设计更精细的多层级路由策略提供了理论支撑。
阈值的选择不是随意的,而是基于开发集上对效率-精度帕累托前沿的系统分析。研究者展示了不同阈值下性能的变化曲线:
| 阈值 | 短路径比例 | 延迟(s) | 准确率(%) |
|---|---|---|---|
| 0.7 | 72% | 1.6 | 77.0 |
| 0.75 | 65% | 1.9 | 77.8 |
| 0.8 | 58% | 2.2 | 78.4 |
| 0.85 | 45% | 2.8 | 78.6 |
| 0.9 | 28% | 3.4 | 78.5 |
阈值0.8处效率增益(62%延迟降低)与精度增益(+3.3%)的平衡最好,因此被选为默认值。
表1:CONSENSUS路由 vs 其他自适应方法对比
| 方法 | 条件 | 准确率(%) | 延迟(s) | 跨领域泛化性 |
|---|---|---|---|---|
| Forced-CoT | 无 | 75.1 | 3.8 | 高 |
| 基于规则 | 领域知识 | 70.5 | 2.1 | 低 |
| AdaCoT | 任务特征 | 76.8 | 2.9 | 中 |
| E-GRM | 共识度 | 78.4 | 2.2 | 高 |
投票隐含地假设所有推理链的"意见"权重相等。但不同推理链的质量差异巨大——一条基于严密推导的推理链应当比一条靠猜测蒙对的推理链权重更高。
E-GRM的评分器 将输入 和候选推理链 拼接后,通过预训练BERT编码器获取联合表示,再通过线性层映射到 区间。
评分器训练的核心是混合损失:
Huber损失处理分数回归,对异常值鲁棒;铰链损失处理排序,专注于难区分样本。超参数 平衡二者。训练数据通过答案正确性弱监督和困难样本挖掘两种策略构造,确保评分器在广泛场景中具有良好的泛化能力。
Huber损失的具体形式体现了对误差的不同处理策略:
当预测分数偏差在1以内时,采用平方损失进行精细化调优;偏差超过1时切换到绝对值损失,防止极端异常标签主导梯度方向。铰链损失 仅当正负样本分差不足预设间隔 时才产生梯度,使训练自动聚焦于难例。
在推理阶段,评分器从多条候选CoT中选择最优;在训练阶段,评分器的输出差值作为扩展GRPO的奖励信号组成部分。这种双重角色使得评分器的优化目标与策略模型的优化目标高度一致。
利用动态触发机制将训练数据分为短路径集和长路径集。短路径训练 ,学习快速回答;长路径训练 ,学习逐步推理。路径分离使训练效率提升约15%,同时避免了简单任务上的过拟合。
标准GRPO仅对单个响应计算奖励,忽视正负样本之间的相对质量差异。E-GRM引入配对奖励:
当 时,正确答案约束和质量对比信号具有相同权重。优化目标引入KL散度正则项控制更新幅度。
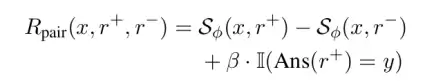
图4:Coupled-GRPO中配对奖励函数的具体构造方式。
32B模型在RM-Bench的标准化平均得分为79.2%。Easy、Normal、Hard三个子集得分分别为86.0%、80.8%、70.7%,呈现随难度递增但性能稳定下降的合理趋势。
7B→14B→32B的趋势显示,性能提升与规模呈近线性关系。32B总体得分0.743超越GPT-4o(0.738),其中Harmlessness Pairwise得分0.823达到最高水平。
32B模型以91.5%综合得分在所有开源模型中排名前列。Reasoning子集95.4%和Safety子集92.0%尤其值得关注,表明评分器的质量评估能力在需要精细判断的场景中最为突出。
| 指标 | 数值 | 对比基线 |
|---|---|---|
| 短路径比例 | 58% | 0%(强制CoT) |
| 准确率 | 78.4% | +3.3% |
| 延迟 | 2.2s | -62%(3.8s→2.2s) |
| FLOPs | 15.7T | -49%(23.7T→15.7T) |
表2:MATH组件消融
| 变体 | 准确率(%) | FLOPs(T) | 延迟(s) | 变化分析 |
|---|---|---|---|---|
| Full | 78.4 | 15.7 | 2.2 | - |
| w/o Dynamic | 75.2 | 23.4 | 3.4 | 效率损失 |
| w/o Scorer | 72.8 | 15.9 | 2.2 | 精度损失 |
| Baseline | 69.1 | 23.7 | 3.6 | 双重损失 |
表3:GRPO变体消融
| 变体 | MATH | HelpSteer2 | RMB无害 |
|---|---|---|---|
| 标准GRPO | 76.9 | 81.5 | 0.765 |
| 扩展GRPO | 78.4 | 82.3 | 0.775 |
32B模型相比7B在RM-Bench上提升9.1个百分点(70.1%→79.2%),在RewardBench上提升6.2个百分点(85.3%→91.5%)。更重要的是,规模扩展对长路径样本的精度贡献大于短路径,说明复杂推理能力随模型规模增长的边际收益更高。
将E-GRM与强制CoT在MATH上进行效率-精度的全面对比:
| 维度 | 强制CoT | E-GRM | 变化 |
|---|---|---|---|
| 短路径比例 | 0% | 58% | +58% |
| 短路径准确率 | - | 81.2% | - |
| 长路径准确率 | - | 74.5% | - |
| 加权准确率 | 75.1% | 78.4% | +3.3% |
| 平均延迟 | 3.8s | 2.2s | -62% |
| 计算开销 | 23.7T FLOPs | 15.7T | -49% |
短路径样本准确率(81.2%)高于长路径(74.5%)进一步证实了共识度与问题复杂度的负相关关系。
E-GRM的设计传达了一个明确的信息:在追求模型能力的同时,关注"何时需要能力"同样重要。对于正在部署LLM的工程团队,E-GRM的共识度计算可以作为轻量级预检步骤,显著降低推理成本。
并行解码的固定成本(约5%)在极低延迟场景下不可忽略。
固定阈值在极端领域可能不是最优。
评分器的OOD泛化边界有待明确。
基于E-GRM的当前工作,有若干有前景的扩展方向:一是动态阈值机制,使路由策略在不同领域自适应调整阈值;二是将共识度信号与其他不确定性度量(如预期校准误差ECE)结合;三是将动态触发与模型量化、知识蒸馏等模型压缩技术联合优化,实现更极致的效率提升。
E-GRM通过动态推理控制和判别式评分,以简洁高效的方式改进了GRM的效率和精度。在各类基准上的全面实验和消融验证,为该方法提供了充分的实证支持。其"量力而行"的设计哲学对更广泛的大模型应用场景具有借鉴意义。
| 指标 | 强制CoT | E-GRM | 提升 |
|---|---|---|---|
| 准确率(MATH) | 75.1% | 78.4% | +3.3% |
| 延迟 | 3.8s | 2.2s | -62% |
| FLOPs | 23.7T | 15.7T | -49% |
| RM-Bench Avg | - | 79.2% | SOTA |
| RMB Overall | - | 0.743 | 超越GPT-4o |
| RewardBench | - | 91.5% | SOTA |
E-GRM在所有维度上实现了综合最优,展现了按需推理范式的巨大潜力。
图表附录:

图1:Coupled-GRPO奖励机制。
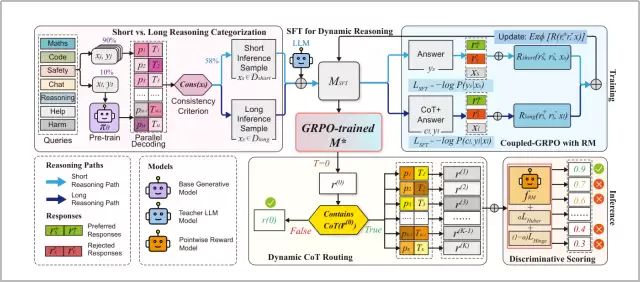
图2:E-GRM完整流程。
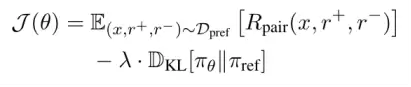
附图1:扩展GRPO优化目标。
参考文献: Xue, C., et al. (2026). Reason Only When Needed.ACL 2026.
版权说明:本文为学术解析,版权归原作者所有。
进技术交流群请添加AINLP小助手微信(id: ainlp2)
请备注具体方向+所用到的相关技术点

关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括LLM、预训练模型、自动生成、文本摘要、智能问答、聊天机器人、机器翻译、知识图谱、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP小助手微信(id:ainlp2),备注工作/研究方向+加群目的。
