高通推出骁龙START计划 推动个人AI终端加速落地
2026-06-20 3361915
2026-06-19 0
原创 AddyOsmani 2026-06-18 15:34 江苏
一个不错的模型配上优秀的 harness,会胜过一个顶级模型配上糟糕的 harness。我在自己的工作里反复看到这一点。越来越多有意思的工程,已经从选择模型转向设计模型周围的脚手架。
谷歌工程师 Addy Osmani 在 4 月份发表了一篇《Agent Harness Engineering》。和他前几天发表的Loop Engineering属于同一条线:Loop Engineering 讨论怎样把 coding agent 组织成持续运行的闭环;Agent Harness Engineering 先把模型外面的那层运行支架讲清楚。
这里的 harness,可以理解为 agent 的脚手架和控制系统:prompt、工具、上下文策略、hooks、sandboxes、subagents、反馈循环和失败恢复路径。Addy 这篇文章的核心意思是,coding agent 不只是模型本身,而是模型加上你围绕它搭出来的一整套工程环境,以下是全文翻译。
一个 coding agent,是模型加上你围绕它搭建的一切。Harness engineering 把这层脚手架当成真正的工程产物;每当 agent 出错,它都会被进一步收紧。
粗略地说:每当你发现 agent 犯了一个错误,你就花时间设计一个解决方案,让它以后不再犯同样的错误。
过去两年,我们一直在争论模型。哪个最聪明,哪个写 React 最干净,哪个幻觉更少。这种讨论当然有意义,但它漏掉了系统的另一半。模型只是运行中 agent 的一个输入。剩下的部分是 harness:prompt、工具、上下文策略、hooks、sandboxes、subagents、反馈循环和恢复路径。它们包在模型外面,让模型真正完成一件事。
一个不错的模型配上优秀的 harness,会胜过一个顶级模型配上糟糕的 harness。我在自己的工作里反复看到这一点。越来越多有意思的工程,已经从选择模型转向设计模型周围的脚手架。
这门实践现在有了名字。Viv Trivedy 提出了 harness engineering 这个术语,他的《Anatomy of an Agent Harness》是我看到过最清晰的一篇,讲明了 harness 到底是什么,以及每一部分为什么存在。
Dex Horthy 一直在追踪这个模式的形成。HumanLayer 把多数 agent 失败归纳为“skill issue”,也就是配置问题,而不是模型权重问题。Anthropic 的工程团队发布了我认为目前最好的公开拆解,讲怎样为长时间运行的工作设计 harness。Birgitta Böckeler 也从用户视角给过一个很好的概览。
这篇文章就是我试着把这些线索汇总起来。
Viv 的一句话基本说清楚了:
Agent = Model + Harness. If you’re not the model, you’re the harness.
Agent 等于模型加 harness。如果你不是模型,那你就是 harness。
Harness 是所有不属于模型本身的代码、配置和执行逻辑。一个原始模型不是 agent。只有当 harness 赋予它状态、工具执行、反馈循环和可执行约束之后,它才变成 agent。
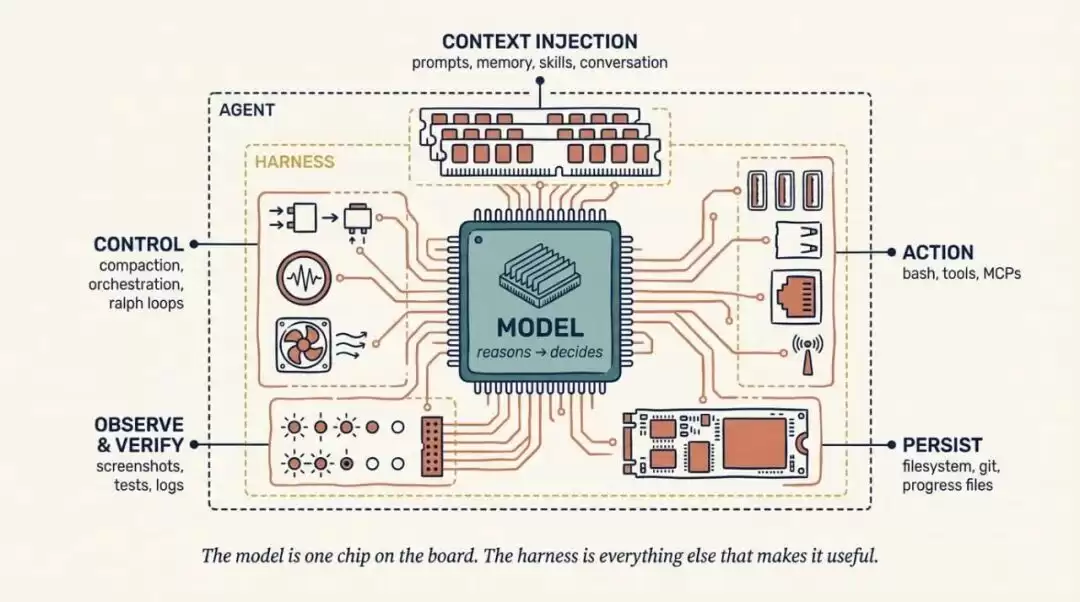
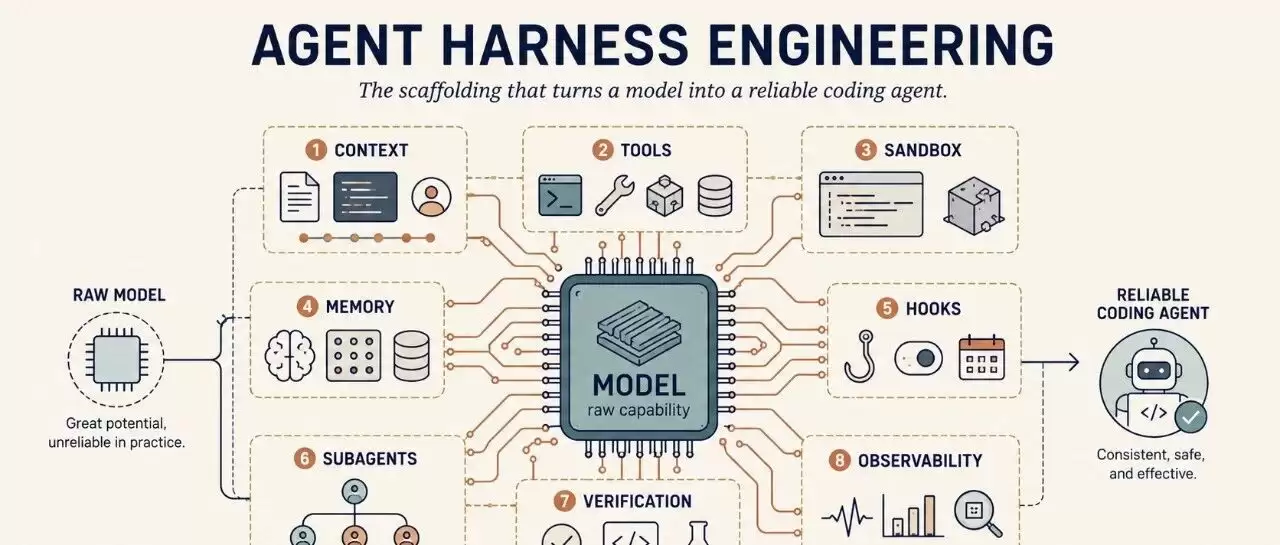
图 1 展示 agent harness 的组成。模型位于中间,harness 围绕模型提供上下文注入、控制流、行动能力、持久化和观测能力。
具体来说,harness 包括:
System prompts、CLAUDE.md、AGENTS.md、skill files 和 subagent prompts。
Tools、skills、MCP servers 以及它们的描述。
打包好的基础设施,例如 filesystem、sandbox、browser。
编排逻辑,例如 subagent spawning、handoffs、model routing。
用于确定性执行的 hooks 和 middleware,例如 compaction、continuation、lint checks。
Observability,例如 logs、traces、cost 和 latency metering。
Simon Willison 把 loop 的部分压缩到最本质:agent 是一个“为了达成目标而循环运行工具的系统”。真正的技术含量,在于工具和 loop 两者的设计。
如果这听起来像是很大的表面积,那确实如此。而且这是你的表面积,不是模型提供商的表面积。Claude Code、Cursor、Codex、Aider、Cline,这些都是 harness。底层模型有时候是同一个,但你体验到的行为,很大程度上由 harness 决定。
coding agent = AI model(s) + harness
这个等式由 Viv 提出,也被 HumanLayer 反复强调,它说明了真正的工作发生在哪里。关于左边模型的争论很热闹,但大部分实际杠杆都在右边。
我经常看到工程师掉进一种模式:agent 做了一件蠢事,工程师把锅甩给模型,然后把问题归档成“等下一个版本吧”。
Harness engineering 的心态拒绝这种默认反应。失败通常是可读的。Agent 不知道某个约定,那就把约定加进AGENTS.md。Agent 运行了破坏性命令,那就加一个 hook 去阻止它。Agent 在一个 40 步任务里迷路了,那就把它拆成 planner 和 executor。Agent 总是把坏掉的代码说成“完成了”,那就把 typecheck 作为反压信号接回 loop。
HumanLayer 的说法是:“这不是模型问题,这是配置问题。”当你认真对待这句话时,harness engineering 就出现了。
Viv 的文章和 HumanLayer 的文章里都出现了一个很有冲击力的数据点。在 Terminal Bench 2.0 上,Claude Opus 4.6 运行在 Claude Code 内部时,分数明显低于同一个模型运行在自定义 harness 里时的分数。Viv 的团队只改变 harness,就把一个 coding agent 从 Top 30 推到了 Top 5。模型会和它接受 post-training 时所处的 harness 绑定在一起。把它放进另一个 harness,给它更适合你代码库的工具、更紧凑的 prompt、更清晰的反压机制,就可能释放出原 harness 没有用出来的能力。
这和“等 GPT-6 就好了”的叙事正好相反。今天的模型能做什么,和你实际看到它做成什么之间,有很大一部分差距是 harness gap。
Harness engineering 里最重要的习惯,是把 agent 的错误当成永久信号,而不是一次性笑话,也不是可以重试一下的“坏运行”。它们是信号。
如果 agent 提交了一个 PR,里面有被注释掉的测试,而我误合并了它,这就是一个输入。下一版AGENTS.md会写上“永远不要注释掉测试;要么删除,要么修好”。下一版 pre-commit hook 会在 diff 里 grep.skip(和xit(。下一版 reviewer subagent 会把被注释掉的测试标为 blocker。
你只在看到真实失败之后添加约束。只有当一个足够强的模型让某条约束变得多余时,你才移除它。好的AGENTS.md里的每一行,都应该能追溯到某个具体出过问题的地方。
这也是为什么 harness engineering 是一门实践,而不是一个框架。适合你代码库的 harness,是被你的失败历史塑造出来的。你没法直接下载它。
Viv 的一个框架,在我真正设计 harness 时最有用:先从你想要的行为出发,再推导出能帮助模型实现这个行为的 harness 组件。他的模式是:
我们想要的行为,或想修复的行为 -> 帮助模型达成它的 harness 设计。
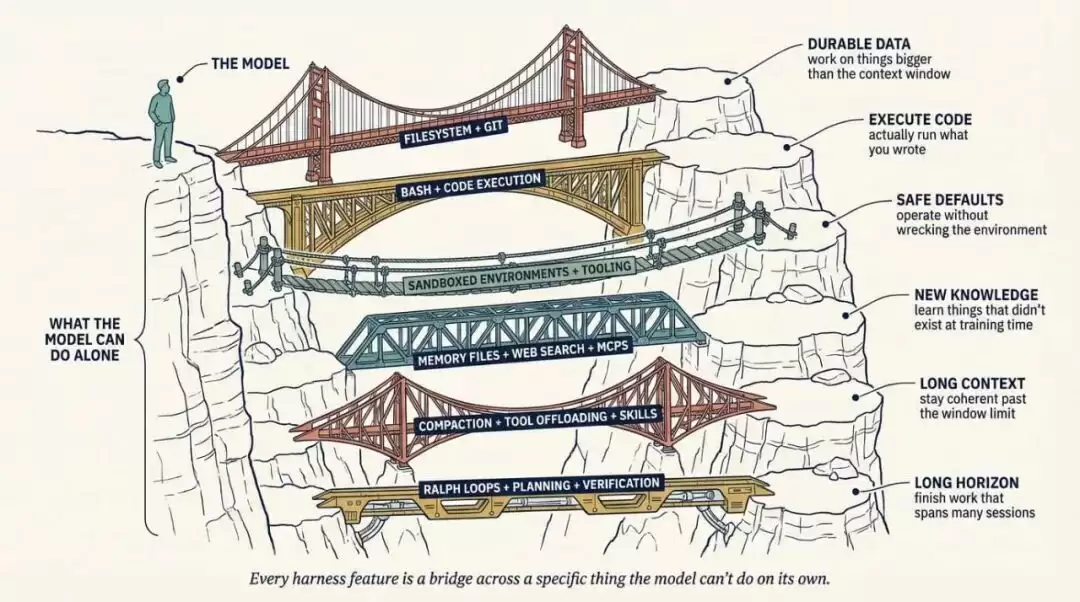
每个 harness 特性都来自模型自身无法稳定完成的行为。例如,持久处理真实数据对应 filesystem 和 git;写代码并执行代码对应 bash 和 code execution;安全执行和默认能力对应 sandboxed environments 和 tooling;记住新知识对应 memory files、web search 和 MCPs;长上下文性能对应 compaction、tool offloading 和 skills;长周期工作对应 Ralph loops、planning 和 verification。
这种推导方式的价值在于,每个 harness 组件都有一个具体工作。如果你说不清某个组件存在是为了交付哪种行为,它大概率就不应该在那里。
本节剩余部分会大致按照 Viv 的顺序走一遍这些组件,同时加上我认为值得借鉴的具体模式。
Filesystem 是最基础的 primitive,也常常因为太无聊而被低估。模型只能直接操作放得进上下文窗口的东西。没有 filesystem,你就在把东西复制粘贴进聊天窗口里,而那不是工作流。
一旦有了 filesystem,agent 就有了一个 workspace:可以读取数据、代码和文档;可以把中间工作卸载出去,而不是全塞在上下文里;也可以让多个 agents 和人通过共享文件协作。再加上 Git,你就免费获得了版本控制,所以 agent 可以追踪进展、回滚错误、为实验开分支。
大多数其他 harness primitives,最终都会在某处指向 filesystem。
今天主流的 agent loop 是 ReAct loop:模型推理,通过工具调用采取行动,观察结果,然后重复。但 harness 只能执行它有逻辑支持的工具。你可以尝试为每一种可能的动作预先构建工具,也可以把 bash 交给 agent,让它按需构建自己需要的工具。
Willison 的观点是,agents 已经非常擅长 shell commands;大多数任务最后都会收敛成几条选得很好的 CLI 调用。Harness 仍然会提供聚焦的工具,但 bash 加 code execution 已经成了 autonomous problem solving 的默认通用策略。这就像不是只教一个人使用某个厨房小工具,而是直接把厨房交给他。
Bash 只有在安全的地方运行才有用。让 agent 生成的代码在你的笔记本上运行有风险,而且单个本地环境也没法扩展到许多并行 agents。
Sandboxes 给 agents 提供隔离的运行环境。Harness 不在本地执行,而是连接到一个 sandbox 里运行代码、检查文件、安装依赖并验证工作。你可以设置 allow-list commands,强制网络隔离,按需启动新环境,并在任务结束后销毁它们。
一个好的 sandbox 应该带着好的默认值:预装语言运行时和包、Git 和测试 CLI、用于网页交互的 headless browser。Browsers、logs、screenshots 和 test runners,让 agent 能够观察自己的工作,并闭合 self-verification loop。
模型不会配置自己的执行环境。Agent 在哪里运行、可用什么、如何验证输出,这些都是 harness 层面的决定。
除了模型权重和当前上下文里的内容,模型没有额外知识。在不能编辑权重的情况下,添加知识的唯一方式就是 context injection。
Filesystem 再一次成为 primitive。Harness 支持像AGENTS.md这样的 memory file 标准,在每次启动时注入。随着 agent 编辑这个文件,harness 会重新加载它,一个 session 里的知识就能带到下一个 session。这是一种粗糙但有效的 continual learning。
对于训练时不存在的知识,例如新库版本、当前文档、今天的数据,web search 和 Context7 这样的 MCP tools 可以跨过知识截止日期。这类 primitive 值得内置到 harness 里,而不是交给用户临时处理。
Context rot 指的是:随着上下文窗口被填满,模型的推理和完成任务的能力会变差。上下文是稀缺资源,而 harness 在很大程度上就是优秀 context engineering 的交付机制。
有三种技术反复出现。
Compaction。当窗口接近满载时,总有东西必须让位。让 API 报错不是 production harness 的选项,所以 harness 会智能总结并卸载旧上下文,让 agent 能继续工作。
Tool-call offloading。大型工具输出,比如 2000 行日志文件,会塞满上下文,却不一定提供多少信号。Harness 会保留超过阈值的头部和尾部 tokens,把完整输出卸载到 filesystem,agent 需要时再读取。
带渐进披露的 Skills。启动时把每个 tool 和 MCP 都加载进上下文,会在 agent 采取第一个动作前就降低性能。Skills 让 harness 只在任务确实需要时才暴露说明和工具。
Anthropic 的 harness 文章还为真正长的任务补充了一种技术:完整上下文重置。Harness 会拆掉 session,并用一个压缩后的 hand-off file 重新构建它。他们明确说,单靠 compaction 不足以完成长任务;有时候你需要带着结构化 brief 从头开始。这更接近人类给新工程师 onboarding 的方式,而不是我们通常理解的“记忆”。
自主长周期工作是圣杯,也是最难做对的事情。今天的模型会遇到提前停止、复杂问题拆解不佳、跨多个上下文窗口工作时不连贯等问题。Harness 必须围绕这些问题进行设计。
我之前在 self-improving agents 和 2026 trends piece 里写过 Ralph Loop 这样的 autonomous coding loops,但放在这个框架里值得再说一遍:一个 hook 拦截模型试图退出的动作,把原始 prompt 重新注入一个新的上下文窗口,迫使 agent 围绕完成目标继续工作。每次迭代都从干净上下文开始,但通过 filesystem 读取上一轮留下的状态。这是一个出奇简单的技巧,可以把单 session agent 变成 multi-session agent;这种 primitive 绝不是“只要换个更聪明的模型”就能自然推出来的。
Planning是模型把目标拆成一系列步骤,通常写进磁盘上的 plan file。Harness 会通过 prompting 和提醒来支持它使用 plan file。每一步之后,agent 通过 self-verification 检查工作:hooks 运行预定义测试套件,并把失败信息和错误文本送回模型;或者模型根据明确标准审查自己的输出。
Planner / generator / evaluator 拆分。Anthropic 关于 long-running harness 的工作明确指出,把 generation 和 evaluation 拆成不同 agents,效果优于 self-evaluation,因为 agents 给自己的工作打分时会稳定偏乐观。这有点像文本版 GAN。相关模式是 sprint contract:generator 和 evaluator 在写代码之前先协商“完成”到底意味着什么。在我自己的工作流里,先写下 done-condition,比任何 prompt 修改都更能抓住 scope drift。
Hooks 区分了“我告诉 agent 做 X”和“系统强制执行 X”。
Hook 是在特定生命周期点运行的脚本:工具调用前、文件编辑后、提交前、session 启动时。Agent 永远不该忘记但经常会忘的事,应该放在 hooks 里。每次编辑后运行 typecheck、lint 和 tests,并把失败暴露出来。阻止破坏性 bash,例如rm -rf、git push --force、DROP TABLE。打开 PR 或 push 到main前要求批准。写入时自动格式化,让 agent 不要把 token 浪费在空白字符上。
HumanLayer 强调、我也越来越认同的原则是:成功时沉默,失败时详细。如果 typecheck 通过,agent 什么都听不到;如果失败,错误文本会被注入 loop,agent 自己修正。这让反馈循环在常见成功情况下几乎免费,在出错时又直接可操作。
AGENTS.md和工具选择Repo 根目录下的扁平 Markdown 规则书,仍然是单个最高杠杆的配置点,因为它每一轮都会进入 system prompt。约定放在这里:package manager、test framework、formatting、“永远不要碰/legacy”、“始终使用我们的 logger”。这里有两条硬吃教训换来的经验。
保持简短。HumanLayer 把自己的规则控制在 60 行以内。每一行都在争夺注意力,规则越多,每条规则就越不重要。它应该像飞行员检查单,而不是 style guide。
每一行都要挣来。规则应该能追溯到某个具体的过去失败,或者某个硬性外部约束。如果不能,它就是噪音。用棘轮方式添加,不要头脑风暴式堆规则。
工具也适用同样的纪律。每个工具的名称、描述和 schema,都会在每次请求中被写进 prompt。10 个聚焦工具胜过 50 个互相重叠的工具,因为模型能把菜单装进脑子里。HumanLayer 还指出了一个真实的安全问题:工具描述会填充 prompt,所以你安装的任何 MCP server 都是模型会读取的可信文本。一个草率或恶意的 MCP,可以在你输入任何东西之前就对 agent 做 prompt injection。
我见过的最清晰的成熟 harness 公开图,是 Fareed Khan 对 Claude Code 架构 的拆解,值得认真看一会儿。
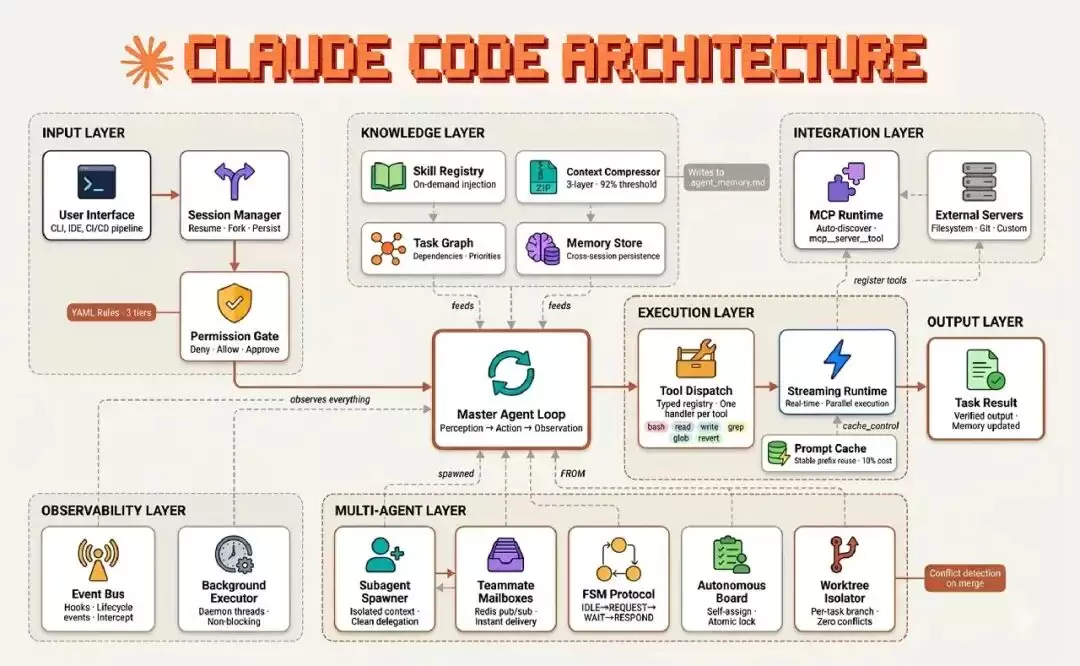
图 3 展示 Claude Code 的多层架构。输入层、知识层、集成层、执行层、输出层、观测层和多 agent 层围绕中心的 master agent loop 展开。
上一节里的几乎每一个概念,都以命名组件的形式出现在这张图上。Context injection 是 knowledge layer。Loop state 存在 memory store 和 worktree isolator 里。破坏性动作 hooks 藏在 permission gate 后面。Subagent context firewalls 构成整个 multi-agent layer。Tool dispatch registry 是 MCP servers 和 bash 接入的地方。Khan 的论点和 Viv 一样,只是通过一个已经发布的产品讲了一遍:Claude Code 的发展轨迹,至少和它底层模型一样,也关于 harness。
Anthropic 文章里一个很好的观察是:随着模型进步,有意思的 harness 组合空间不会缩小。它会移动。
天真的叙事是,更好的模型会让 harness 过时。如果模型能规划,就不需要 planner。如果模型能在长周期里保持连贯,就不需要 context resets。是的,Opus 4.6 基本消灭了 context-anxiety 这种失败模式。Sonnet 4.5 以前会在接近它以为的上下文限制时过早收尾,这意味着我六个月前还在写的一整类 anxiety-mitigation scaffolding,现在已经成了死代码。
但天花板也随着模型移动了。过去无法触及的任务现在进入可做范围,而它们也带来自己的失败模式。焦虑缓解脚手架消失了,取而代之的可能是多日 memory policy,一个协调三个 specialized agents 的 harness,或者针对生成 UI 设计质量的 evaluators。假设会变化,编码这些假设的脚手架也会跟着变化。
Anthropic 说得很清楚:“harness 里的每个组件,都编码了一个关于模型无法独立完成什么的假设。”当模型在某件事上变强时,相关组件就不再承重,应该被移除。当模型解锁了新能力,就需要新的脚手架去触达新的天花板。
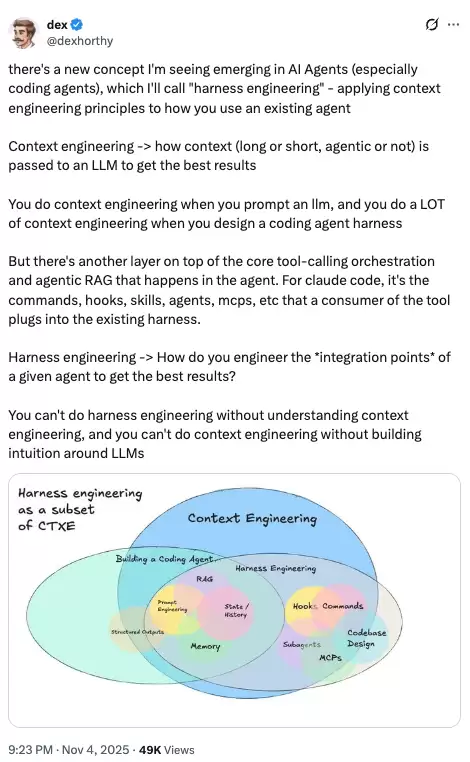
另一件正在发生的事,Viv 明确命名为 harness 设计和模型训练之间的反馈循环。
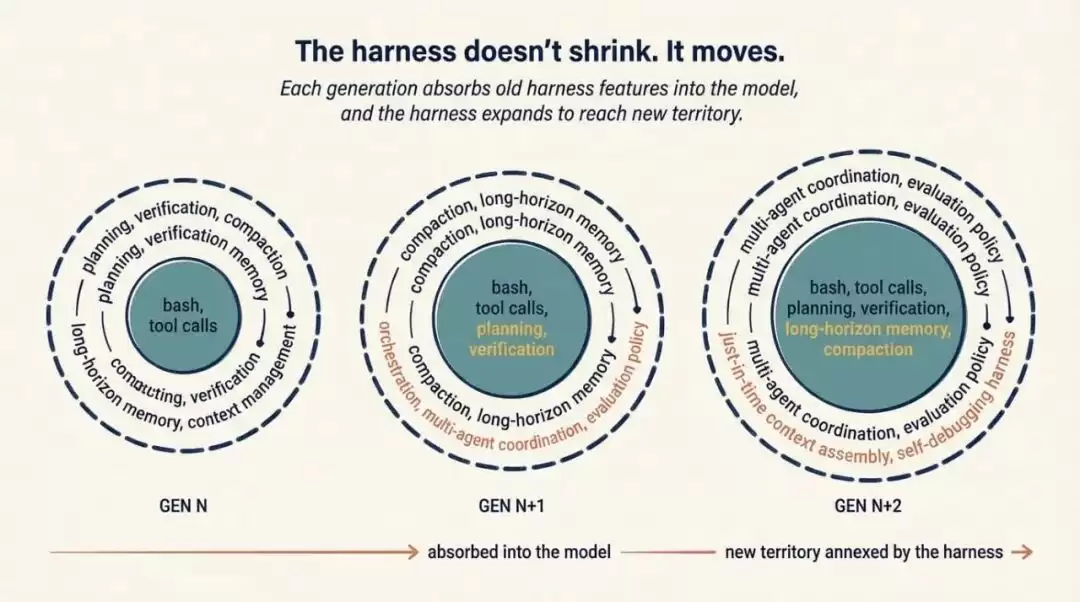
图 4 展示模型与 harness 的训练循环。一个有用 primitive 先在 harness 中被发现,再被标准化进产品,用于训练下一代模型,下一代模型又变得更擅长使用这个 primitive,如此循环。
今天的 agent 产品在 post-training 时已经把 harness 放进了 loop。模型会特别擅长 harness 设计者认为它应该擅长的动作:filesystem operations、bash、planning、subagent dispatch。这就是为什么 Opus 4.6 在 Claude Code 里和在别人 harness 里感觉不同;也解释了为什么改变一个工具的逻辑有时会造成奇怪的回归。一个真正通用的模型不应该在意你用的是apply_patch还是str_replace,但 co-training 会制造过拟合。
实际含义有两点。第一,harness 是一个活系统,不是一次设置完就不再动的 config file。第二,“最好”的 harness 不一定是模型训练时所在的那个,而是为你的任务设计的那个。Viv 在 Terminal Bench 上从 Top 30 到 Top 5 的跃迁,是我看到过最清晰的证明。
Viv 的另一个贡献是 HaaS 这个框架:Harness-as-a-Service。它的观察是,我们正在从构建在 LLM APIs 之上,转向构建在 harness APIs 之上。前者给你一个 completion,后者给你一个 runtime。Claude Agent SDK、Codex SDK 和 OpenAI Agents SDK 都指向同一个方向。你开箱得到 loop、tools、context management、hooks 和 sandbox primitives,然后对它们做定制。
这个转变很重要,因为过去的默认路径是:自己构建 loop,自己接 tool-calling,自己处理 conversation state,自己发明 approval flow。现在的默认路径是:选择一个 harness framework,围绕四个支柱进行配置,也就是 system prompt、tools、context、subagents,然后把剩下的精力放到特定领域的 prompt 和 tool design 上。
这也是“skill issue”变得可处理的原因。每次出错时,你不是从零重建一个 agent。你是在调一个已经拆得足够好的配置表面。
Viv 对这一点的说法,也是开始时允许自己混乱的最好理由:“好的 agent 构建是一场迭代练习。如果没有 v0.1,你就没法迭代。”
把顶级 coding agents 放在一起看,Claude Code、Cursor、Codex、Aider、Cline,它们彼此之间的相似度,比它们底层模型之间的相似度更高。模型不同,但 harness patterns 正在收敛。我不认为这是偶然的。这是整个行业慢慢找到那些真正承重的脚手架,把一个生成式模型变成能交付东西的系统。
Viv 对开放问题的框架,是我觉得最令人兴奋的部分:编排许多 agents 在同一个代码库上并行工作;让 agents 分析自己的 traces,识别并修复 harness 层面的失败模式;让 harness 根据给定任务,just-in-time 地动态组装正确的工具和上下文,而不是在启动时预先配置好。
最后这一点尤其让我觉得,harness 正在停止作为静态 config,开始变得更像某种 compiler。
原文:https://addyosmani.com/blog/agent-harness-engineering/
Viv Trivedy,《Anatomy of an Agent Harness》:https://x.com/Vtrivedy10/status/2031408954517971368
Dex Horthy:https://x.com/dexhorthy/status/1985699548153467120
HumanLayer: https://www.humanlayer.dev/blog/skill-issue-harness-engineering-for-coding-agents
Anthropic engineering: https://www.anthropic.com/engineering/harness-design-long-running-apps
Birgitta Böckeler: https://martinfowler.com/articles/exploring-gen-ai/harness-engineering.html
Simon Willison: https://simonwillison.net/2025/Sep/30/designing-agentic-loops/
Addy Osmani, Self-improving agents: https://addyosmani.com/blog/self-improving-agents/
Addy Osmani, 2026 trends: https://beyond.addy.ie/2026-trends/
Claude Code architecture: https://levelup.gitconnected.com/building-claude-code-with-harness-engineering-d2e8c0da85f0
HaaS: https://www.vtrivedy.com/posts/claude-code-sdk-haas-harness-as-a-service
进技术交流群请添加AINLP小助手微信(id: ainlp2)
请备注具体方向+所用到的相关技术点

关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括LLM、预训练模型、自动生成、文本摘要、智能问答、聊天机器人、机器翻译、知识图谱、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP小助手微信(id:ainlp2),备注工作/研究方向+加群目的。
