NeurIPS用AI检测:说我的论文是AI生成的
2026-06-22 3362907
2026-06-13 0
智东西 2026-06-12 18:50 广东

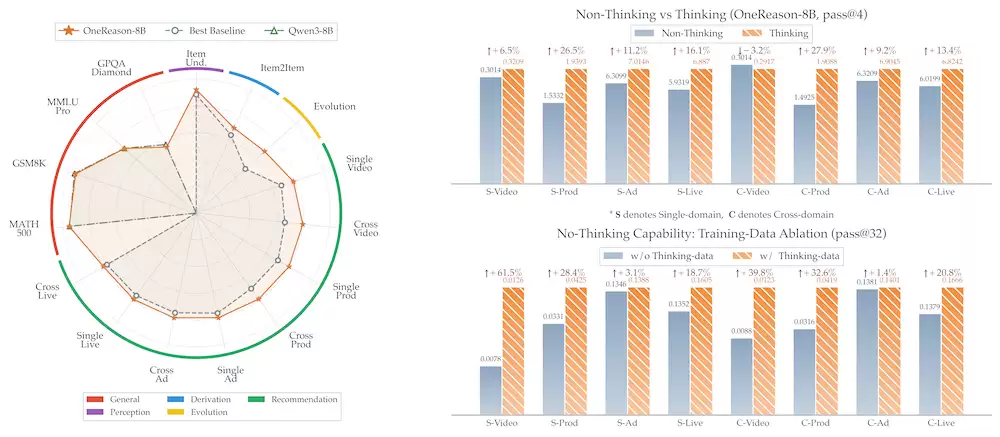
快手发布OneReason,首次在单模式下让“思考模式“在推荐任务上稳定优于“非思考模式”。

快手发布OneReason,让推荐系统从scaling走向reasoning”。
近日,快手OneRec团队发布了OneReason——一个8B规模的推荐推理基础模型。它业内首次在单模式下让"思考模式(thinking)"在推荐任务上稳定优于"非思考模式(non-thinking)",并通过Fast-Slow Thinking架构在快手App生活服务广告场景跑通线上A/B:总曝光+10.33%/广告收入+8.23%/ROI>5。
01.
引子:从一个反直觉现象说起
基础大模型这几年的主旋律从Scaling走向Reasoning,并向着Agentic演进——智能从"知道多少",走向"想得对不对",再到"能不能把事情做好"。一个自然的想法是把这套范式直接搬到推荐场景。但我们在OneRec-Think、OpenOneRec两次前置探索中撞上了一个反直觉现象:
打开思考模式,推荐效果不仅没有变好,有时反而更差。
这与多模态领域的"Thinking Hurts"同构——但根因还要更深一层:推荐里"思考"的形态从来没被认真定义过,模型只是在常规的认知框架里硬接CoT。
围绕这个发现,整个OneReason的工作可以拆成三个层层递进的问题:
1.推荐任务的CoT格式应该长什么样?
(设计层——CoT应该长什么样才对得起推荐推理的本质)
2.推荐大模型能否学会Reasoning?
(实现层——给定一套CoT设计,模型能否真的把它学进参数里、并产生因果贡献)
3.推荐大模型能否在工业场景上线落地?
(部署层——8B大模型+长CoT能不能进真实业务、跑出真实ROI)
每个问题背后都对应着一组真实的卡点。OneReason的故事,就是把这些卡点一个一个拆开、一个一个解掉的过程。
OneReason技术报告:
https://arxiv.org/abs/2606.06260
HuggingFace:
https://huggingface.co/OpenOneRec/OneReason-0.8B-pretrain
02.
Q1:推荐任务的
CoT格式应该长什么样?
卡点一:直接套用数学/代码CoT,认知形态搞错了
要回答这个问题,得先回到一个常被略读的根本问题:推荐推理的本质,到底是哪一类推理主导?
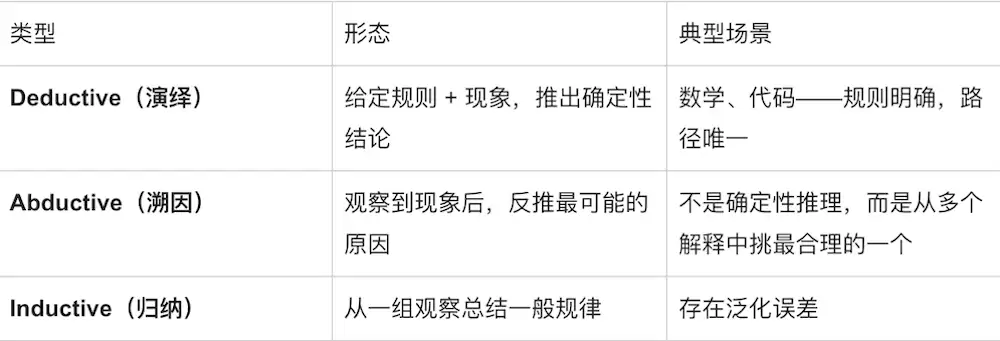
把推荐链路按这把尺子拆开:

推荐推理的核心难点在溯因——因为用户的真实兴趣是不可见、潜在的,我们看到的只是行为,真正驱动行为的"原因"必须靠推理反推。这与代码、数学等演绎主导的任务有本质区别。把通用LLM那套以演绎为主的CoT直接搬到推荐里,相当于用错了认知工具——这是"Thinking Hurts"在推荐里更深的认知层根因。
卡点二:溯因解释空间发散,自由生成会被噪声拖偏
溯因推理的解释空间天然发散——一段行为序列背后可以有无数种"为什么"。如果让模型"自由地想",CoT越长越偏离信号;同时,CoT还会面临几类典型陷阱:
剧透:CoT中提前暴露目标item信息,破坏推荐公平性;
伪解释:把"用户看了A、B、C,所以推荐D"当作推理,本质是行为流水账复读;
幻觉:编造用户未表现出的兴趣;
不一致:分析说"喜欢A方向",最终却推荐B方向。
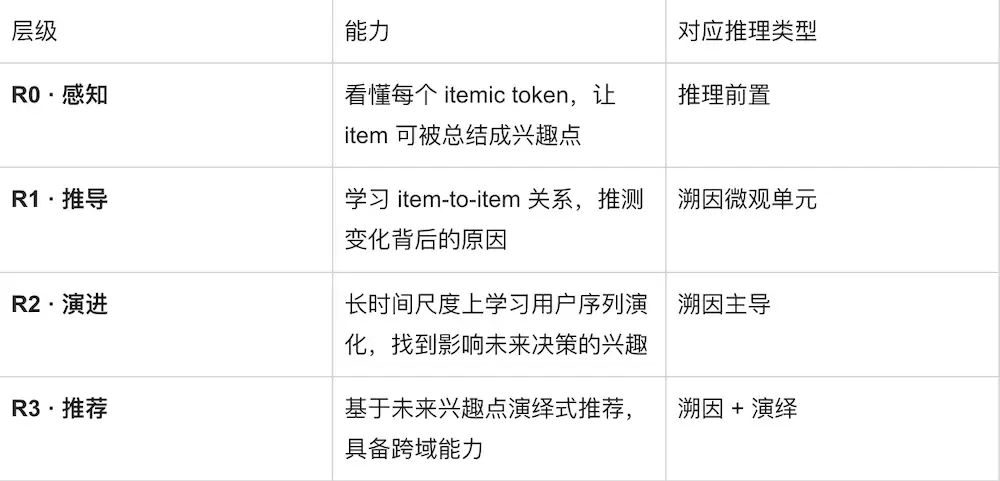
解决:R0–R3能力分层+R3三段式CoT+五维质量评估
针对"认知形态错配",我们按溯因主导的链路把推荐推理拆成R0–R3四层能力:
针对"自由发散被噪声拖偏",R3推荐CoT设计成严格的三段式结构——不让模型自由想,而是逼它做信息压缩:
用户抽象(归纳):从稀疏、含噪声的行为中抽象出可解释的偏好画像,并引用证据;
兴趣发散(溯因):把行为转化为一组候选兴趣假设——这里我们发现一个反直觉边界:宽度n=1/3/5最优、n=10/20反向衰减——典型的信息瓶颈:过宽的候选集会引入低置信度噪声、稀释核心信号;
兴趣权衡与推导(溯因+演绎):综合证据强度、近期性、画像匹配、跨域兼容性等多维度做最终多跳推断。
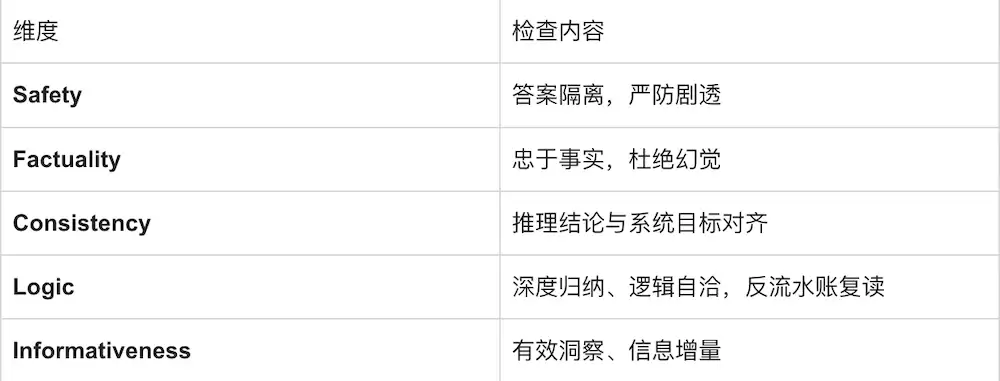
针对"剧透/伪解释/幻觉/不一致"四类陷阱,配套CoT五维质量评估:
到这一步,我们把"推荐CoT应该长什么样"这件事从口号推进到了可执行的设计规约。但设计规约只是图纸——下一步要回答的是:模型真的能学会按这张图纸思考吗?
03.
推荐大模型能否学会Reasoning?
卡点一:通用LLM的三种Reasoning激发路径,在推荐场景集体失效
要让R0–R3+三段式CoT真正进到模型参数里,最直接的想法是套用通用LLM的成熟方案。但通用LLM激发Reasoning的三种主流路径,每一种在推荐场景都有死锁:

这里说的还是SID模型单独无法激发reasoning,要加入文本数据训练。然而,SID和文本怎么融合,也是有讲究的,可能会出现thinking hurts。所以往根因上拆,"Thinking Hurts"的两块地基都是沙子:
1.感知地基塌:推荐基模的词表全是itemic token,嵌入被通用文本先验稀释——模型连"这个物品到底是什么"都没认清;
2.认知地基塌:直接把通用LLM的CoT数据混进推荐SFT,没有针对推荐任务的特殊认知形态做专属设计——长链推理只会在错误方向上累积误差。
卡点二:SFT之后,思考能力被老师的能力锁死,且thinking普遍打不过non-thinking
SFT阶段我们已经做完了:拿外部老师模型生成的trajectory——里面既有CoT,也有最终的itemic token——让模型teacher-forced地照着抄一遍。这一步让模型获得了通用的语义理解、指令跟随,以及初步的、面向推荐的推理能力。
但SFT有一个本质的天花板:模型的能力被老师的能力锁死了——老师没演示过的推理路径,学生学不到;老师演示得不够好的,学生只能复刻一遍。落到指标上,SFT阶段四个域上的thinking模式普遍弱于non-thinking模式:
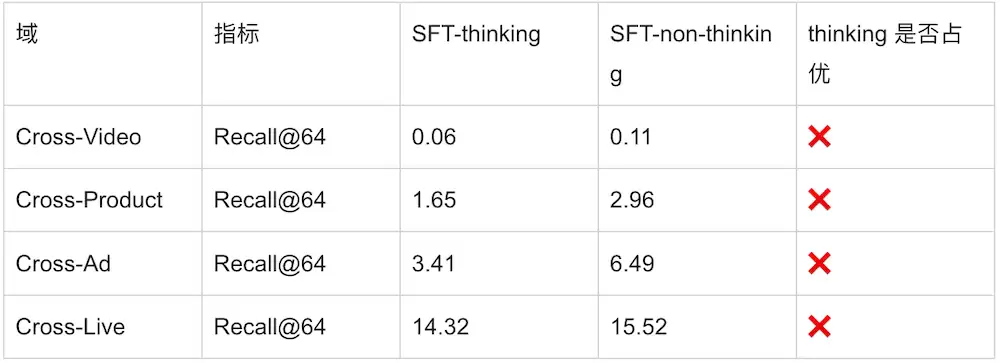
表:SFT结束时四个域的thinking vs non-thinking(数据来自技术报告Table9,单位%)。可以看到thinking普遍弱30%–50%——"打开思考反而更差"。
而我们的模型经过SFT其实已经在大规模推荐数据上"见过世面"了,它有没有可能跳出模仿、通过自己探索来进一步提升?这就是我们做RL的目的——通过"答案是否正确"这条outcome reward,反向牵引CoT的梯度方向:模型自己生成N条推理轨迹,奖励模型把更有可能产生正确推荐的那条CoT概率拉高、把误导推荐的CoT概率压低。CoT第一次有了"对错",而不仅仅是"像不像老师"。
卡点三:直接套用GRPO行不通——奖励稀疏是核心问题
但用GRPO直接跑推荐,会立刻撞上一个核心难题:
相比于数学推理、代码生成等可验证场景,推荐任务的候选空间极大、正确推荐信号极其稀疏,同时同一个用户的兴趣往往有多个方向。在这种reward landscape下直接套用通用GRPO,绝大多数rollout都拿不到任何有效奖励——梯度信号近乎为零,训练根本走不动。
一段我们曾经很狼狈的故事:第一次直接拿GRPO跑推荐RL,一开始看上去reward在涨——但训到后来模型开始整齐划一地"摆烂":CoT千篇一律——不同用户、不同行为序列、不同领域,模型吐出的"用户抽象/兴趣发散"几乎是同一段模板,只换几个名词。这是稀疏奖励下的典型坍塌:模型放弃探索,缩到一个能侥幸命中的小区域里反复横跳。
围绕这个核心问题,OneReason对GRPO做了三方面改进——见后文"解决"一节。
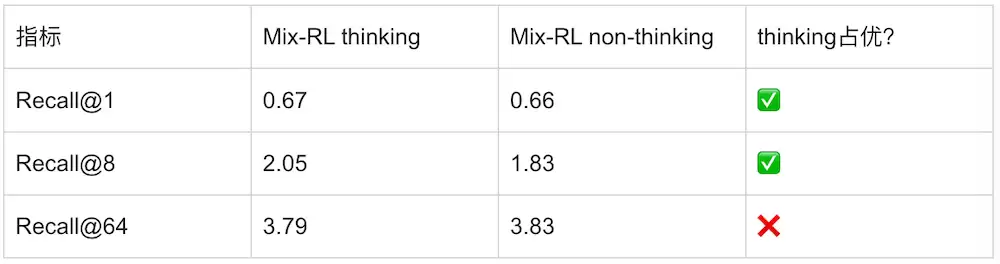
卡点四:跨域撕扯——Mix-RL没收敛到任何一个域的真分布峰值
稀疏奖励问题被工程上压住、Mix-RL跑稳之后,再看thinking vs non-thinking,会发现一个有意思的现象:对于recall@K,小K上 thinking已经能略微占优,但K一拉大,thinking就守不住——以Cross-Product为例:
原因是GRPO这类policy optimization本质是峰值追踪、会持续sharpen输出分布——把概率挤到group-relative advantage高的少数 rollout上,得到"单点很尖、覆盖面很窄"的输出分布。Recall@1(K=1)这种小K指标看起来还行,但越大越吃覆盖面,sharpened单峰守不住——这就是thinking在大K上fade的根因。
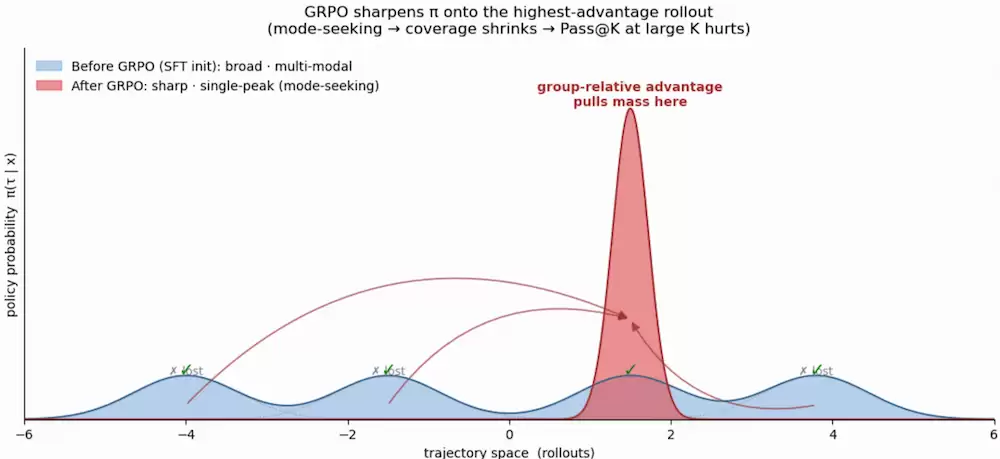
文献佐证:DAPO——明确诊断GRPO的token-level entropy collapse:advantage归一化把概率过度集中到少数rollouts,输出分布塌缩成尖峰。
最直接的修法是把分布变宽——让正确解集合扩大。RFT(Rejection-sampling Fine-tuning)正好做这件事:让模型rollout一批轨迹,用reject sampling只保留命中GT的正确轨迹,再用next-token prediction把这批轨迹学回模型,做分布扩覆盖,会把概率分配到所有正确轨迹上,从而broaden分布(使得输出分布变宽,从而可以覆盖更多的真实分布的峰值)(Yuan et al.2023,arXiv 2308.01825)。
但直接拿Mix-RL自己rollout自己做RFT,实际上是“拆东墙补西墙”——broaden是个此消彼长的过程:大K上覆盖面提升了,小K上原本的sharpening红利反而有所损耗(Recall@1/Recall@8轻微下降);而且绝对值本身并没提升。于是另一个问题浮出水面:如果 RFT只能在原地重新分配能量、拿不到纯增量,那么真正该优先修的不是sharpening、而是Mix-RL本身的绝对值不够高。
退一步看,Mix-RL的真问题不在sharpening——sharpening是所有RL都会有的;真问题是Mix-RL把四个域的信号同时塞进一个策略,梯度互相冲突,最终sharpen到了一个"四个域都不是真分布峰值"的中间夹生点。这才是绝对值上不去的根因。
把每个域单独跑GRPO(即Single-RL),结果立刻清晰:Single-RL绝对值显著高于Mix-RL(Cross-Ad/Cross-Live提升尤其明显)。这证明每个域的真分布峰值是能学到的,只是不能放在一起训。
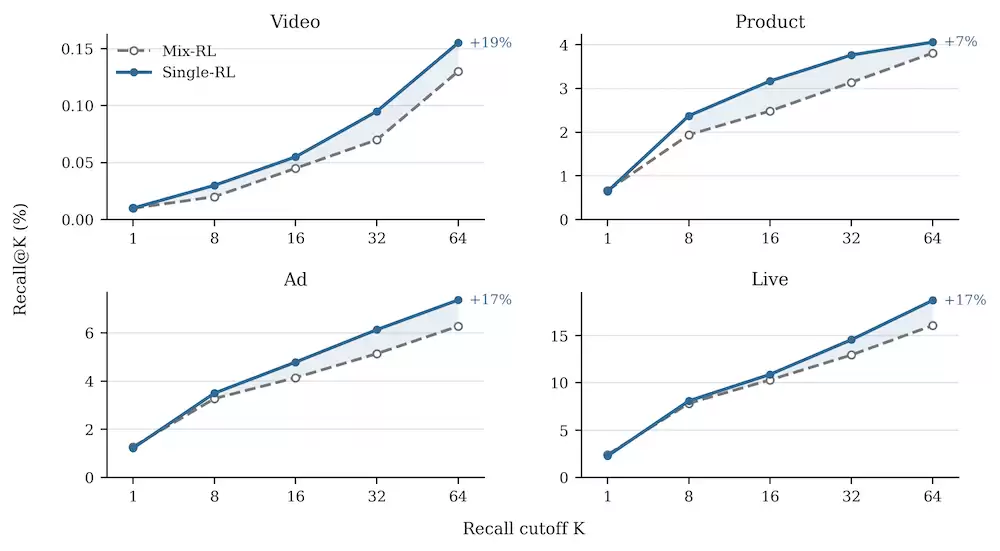
所以正确的工程链条是:用Single-RL把每个域的分布中心推到真分布峰值(解决绝对值问题),再用RFT/MOPD在这些高质量 teacher rollout上统一回基模——RFT负责"thinking占优"、MOPD负责"在Product/Ad/Live三个重点业务域把non-thinking绝对值推到更高"。这就是Specialize-then-Unify框架。
解决:从地基开始重铸——Pre-train重感知/SFT落设计/RL真激活
复盘三条路径,失败点其实指向同一件事:通用LLM的预训练里没有推荐世界。模型没见过item,所以Prompt调不出感知;不理解曝光和行为序列,所以SFT灌不进设计;连基础的推荐认知都没有,RL再精巧也激活不出从未具备的能力。问题不在上层方法,而在底下缺了一块地基。
OneReason的解法因此不是再换一个prompt、再加一份SFT数据,而是往前补一步——从Pre-train阶段就把推荐数据和通用数据混合训进去,先打造一个原生认识item、理解曝光、读得懂行为的推荐基础模型;地基补齐之后,Q1设计的CoT 才能真正落进SFT、Q2想要的推理才能真正被RL激活。这就是接下来要讲的Pre-train重感知/SFT落设计/RL真激活三步。

Pre-train·看得懂(578B token=416B推荐对齐+162B通用文本与多模数据)
Tokenizer:融合视觉/音频/文本特征训练Item Embedding→三级8192RQ-Kmeans量化→「域标识+三段子Token」统一格式,单品5000亿表示空间,覆盖短视频/直播/电商/广告四大领域;
四粒度对齐:Token(子单元语义)→Item(粗化降噪)→Relational(i2i关系/兴趣流转)→User(单域+跨域兴趣演化);
三阶段渐进退火:词表预热(仅训词表embedding与lm head)→全参训练→长序列退火(32K)。

效果(与OpenOneRec同等数据量):Grounding+161%/Understanding+36%/跨域核心推荐+65%——感知地基扎实了。
SFT·想得对:约395万条数据,按Q1的R0–R3阶梯式覆盖——R0感知(941K)/R1推导(400K)/R2演进(130K)/R3推荐CoT(885K)+Itemic指令(103K)+通用SFT(1.5M),把"用户抽象→兴趣发散→兴趣权衡"三段式直接以监督信号形式注入。
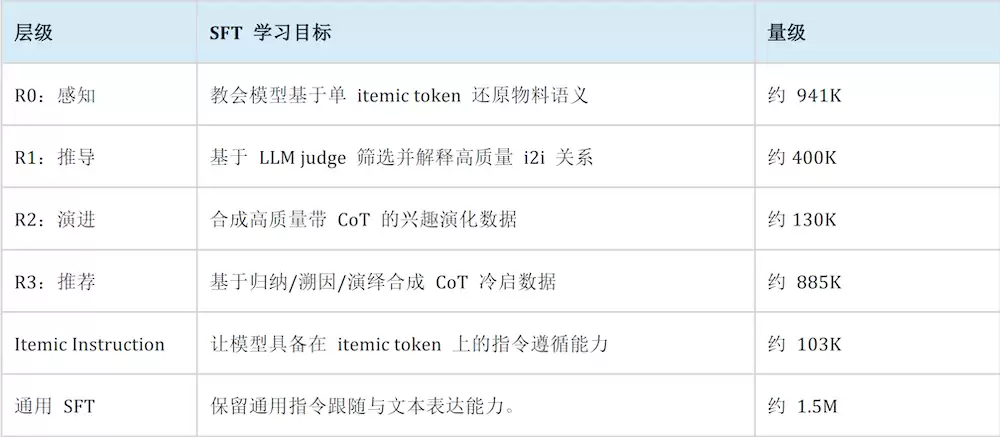
SFT数据分布。
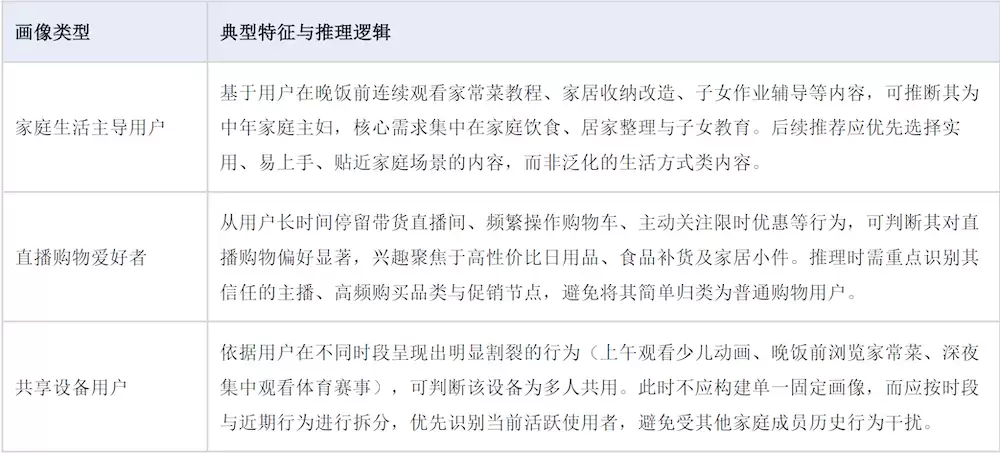
Persona Abstraction的典型画像示例。

Interest Expansion和Transition Inference的例子。
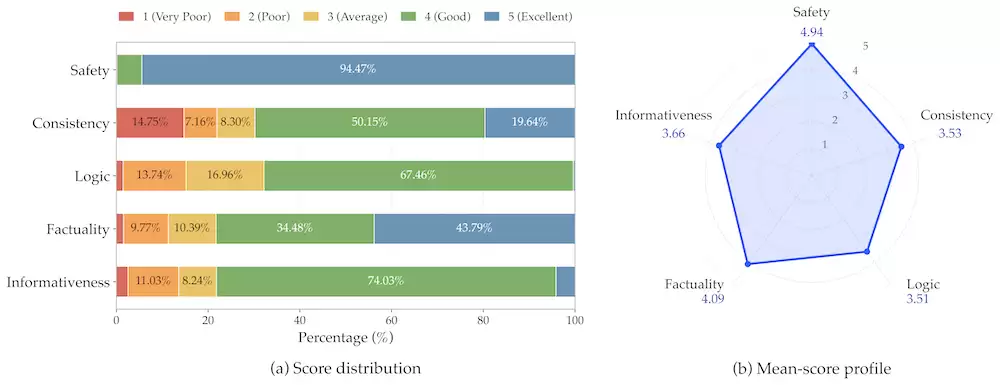
R3推理轨迹质量评估,覆盖Safety、Consistency、Logic、Factuality、Informativeness五个维度)。
RL·敢思考、能跨域:对应卡点三、卡点四双重解药。
针对卡点三(奖励稀疏)——围绕这一核心问题,OneReason对GRPO做三方面改进,按"先让训练能跑起来→再让训练稳得住→再让训练学得对"递进:
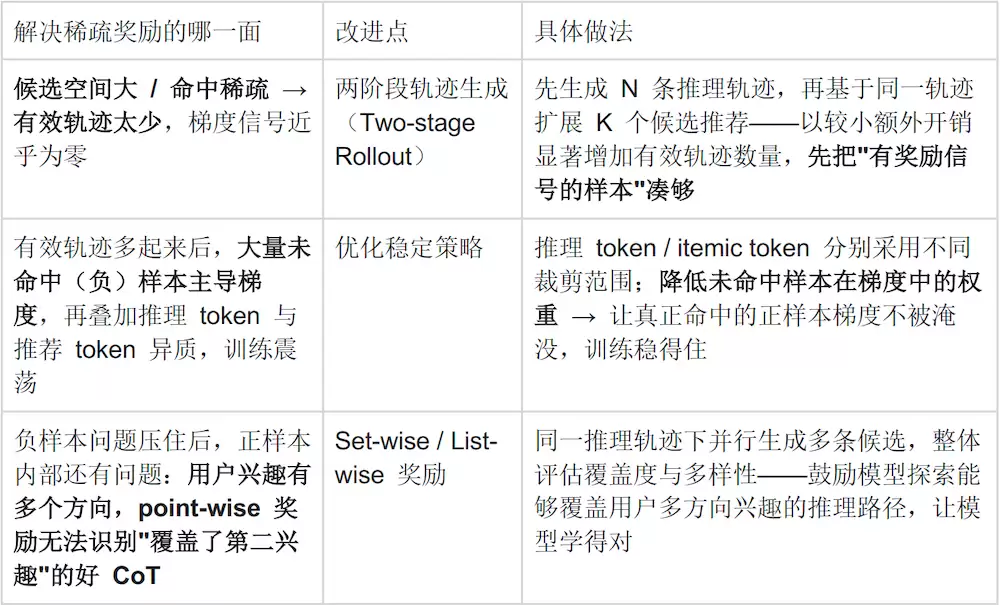
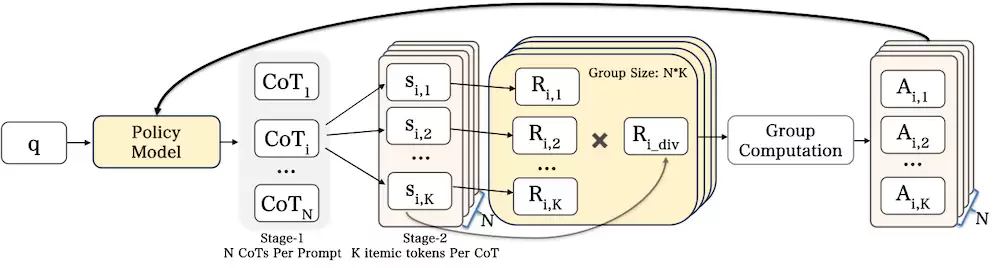
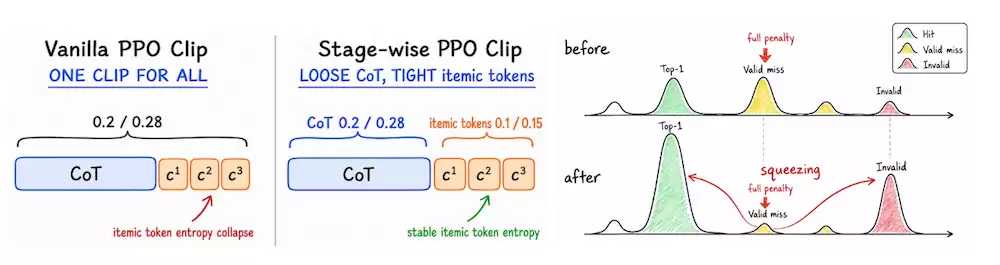
针对卡点四(跨域撕扯):先专后合(Specialize-then-Unify)框架:首先在每个领域内独立进行强化学习,学习领域特有的推荐知识,把绝对值推上去;随后再将多个领域专家模型的能力融合到统一模型中。
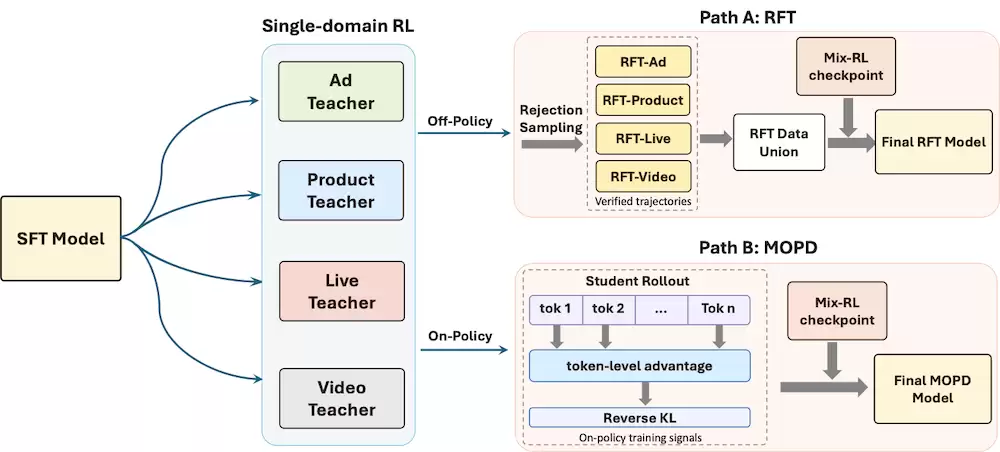
具体来说,探索了两条不同的技术路线:
RFT(Rejection Sampling Fine-tuning,off-policy)通过学习专家生成的高质量成功轨迹进行知识整合。因为broaden的中心已被单域老师模型推到了每个域的真分布峰值,所以broaden不以损绝对值为代价。RFT的独特价值是:在四个域上均稳定保证thinking >non-thinking——这是"思考对推荐有因果贡献"这件事唯一能被干净证明的路径。
MOPD(On-policy Distillation):学生先rollout,学生从策略层面持续吸收多个领域专家的能力。本质是峰值追踪:与RFT反方向——不broaden,而是把学生进一步精准对齐到teacher的真分布峰值上。
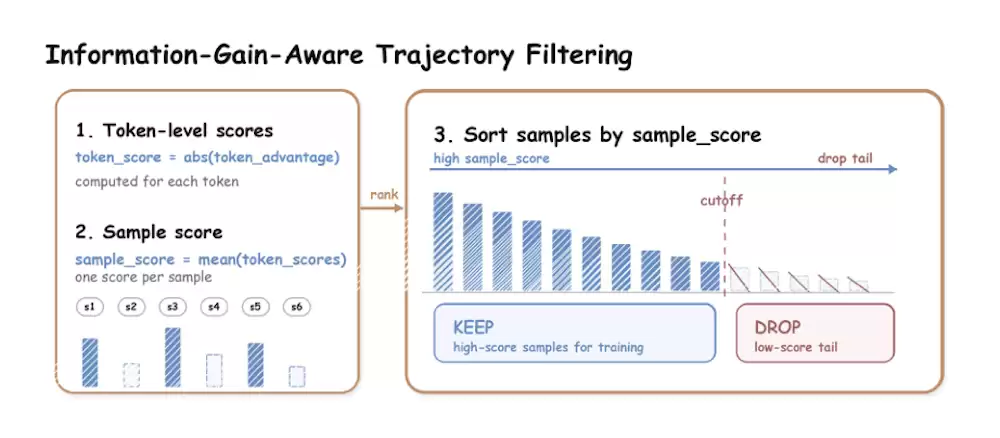
关键工程发现:学生很快在热门头部item上对齐teacher,这些轨迹advantage趋近零,真正有价值的长尾item信号反而被冗余梯度淹没。为此我们提出 Information-Gain-aware Trajectory Filtering(IGTF):只保留贡献前80%信息量的高价值轨迹参与蒸馏。这个设计让 MOPD原本对大K不友好的问题也得到了缓解——在Ad/Live域上thinking模式的收益反而更明显,说明"思考"在这两个域真的把往常捞不出来的长尾item捞出来了。
核心发现:
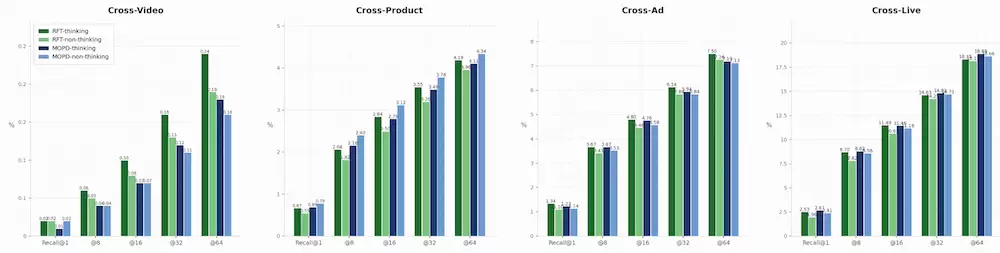
比绝对值谁高:RFT与MOPD半斤八两——thinking模式上RFT略优(Ad域明显)、MOPD略优(Live域明显);两者都是在"接近真分布峰值"的起点上各自加上不同价值,RFT不是"以损绝对值换thinking优势"。
RFT的独有价值:四个域均稳定保证△=thinking-non-thinking>0——这是证明"思考对最终推荐有因果贡献"唯一干净的路径;MOPD在这件事上不稳定。
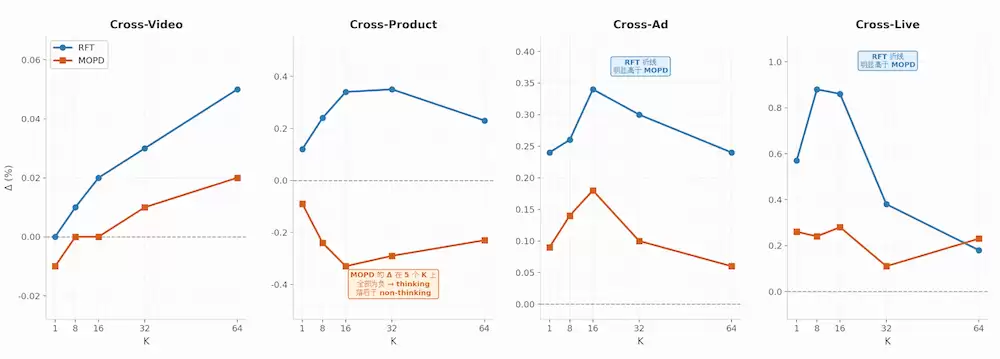
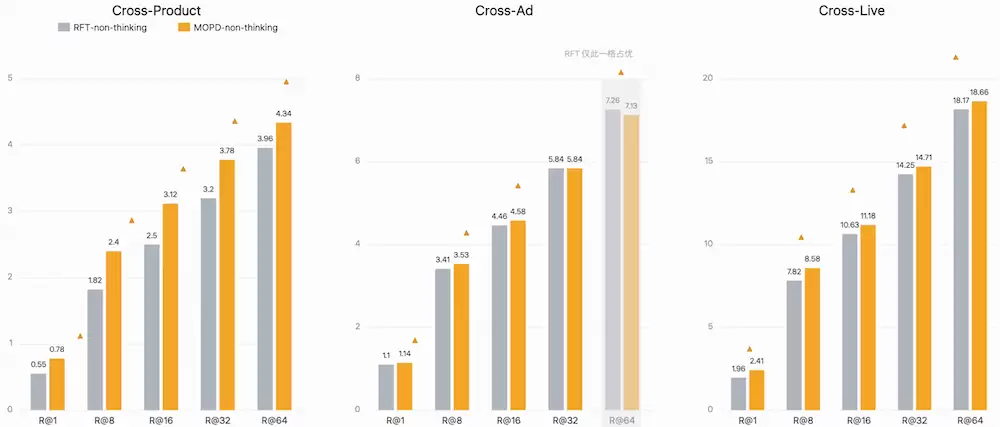
MOPD的独有价值:在Cross-Product/Cross-Ad/Cross-Live三个重点业务域上,non-thinking绝对值几乎全面高于RFT。对靠non-thinking上线的ROI导向场景,这是一个相当稳的工业信号。但需明确一点:Cross-Video域的non-thinking优势不明显(两者量级接近且互有胜负),这个域的MOPD还需进一步优化。
选择策略:
优先选RFT的场景(核心是"在意thinking本身的价值"):
→thinking>non-thinking是RFT唯一能给的"思考价值证明";
——行为信号天然稀疏,统计模型答不出"为什么适合此刻",需要溯因推理把多跳因果链显式写出来;
——把决策过程从权重黑盒搬到CoT,业务约束可写在推理层、策略迭代节奏从周级降到天级;
——规划、工具调用、长程对话推荐都需要一个稳定可读的推理链作为底座,没有Reasoning,Agentic只剩调用工具的壳。
优先选MOPD的场景(核心是"在意non-thinking上线绝对值"):
(如生活服务广告这类直接关心点击/收入绝对量的工业场景)→在Cross-Product/Cross-Ad/Cross-Live三个重点业务域上选MOPD——这三域的non-thinking绝对值几乎全胜RFT,对工业系统更友好。这不是"不要thinking"的妥协,而是"要non-thinking够着最高的那条路径"的主动选择。Cross-Video域的MOPD non-thinking优势暂还不明显,需后续进一步优化。
两条路径不是二选一,而是按业务目标互补:RFT是"知识沉淀"——把已验证的对的路径固化;MOPD是"能力扩展"——在持续训练里全局拔高底层语义直觉。
关键效果:从"假思考"到"真思考"的相变信号
——业内首次在单模式下让thinking模式在推荐任务上稳定占优;
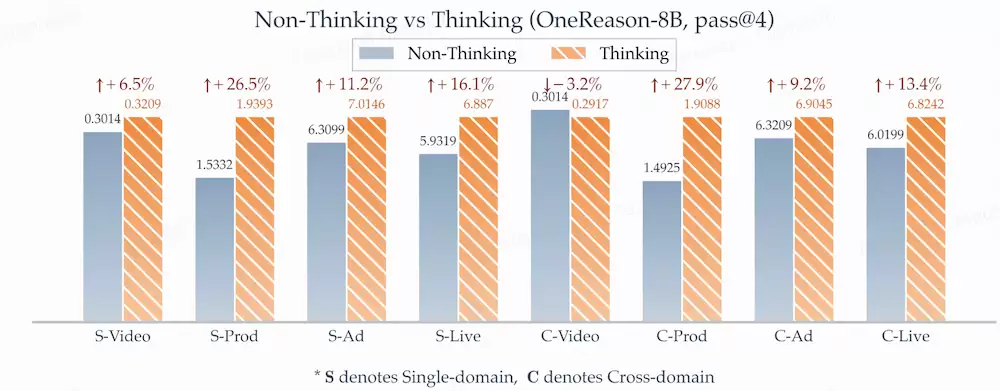
CoT信息熵增益由负转正:度量CoT对最终答案的因果贡献——SFT阶段全负向(CoT不能直接带来增益)→RFT后全正向(CoT真正辅助了模型对正确答案的理解)。
这是从假思考到真思考的相变信号;
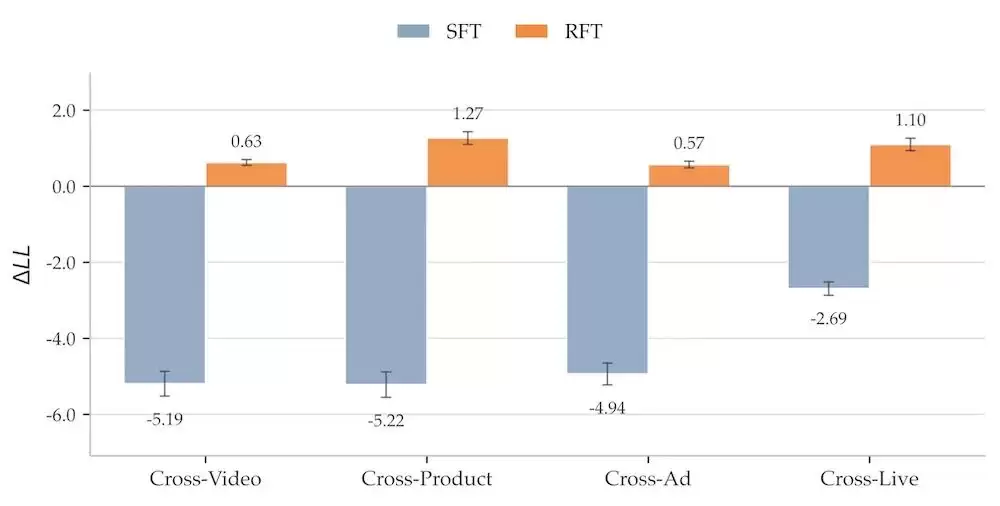
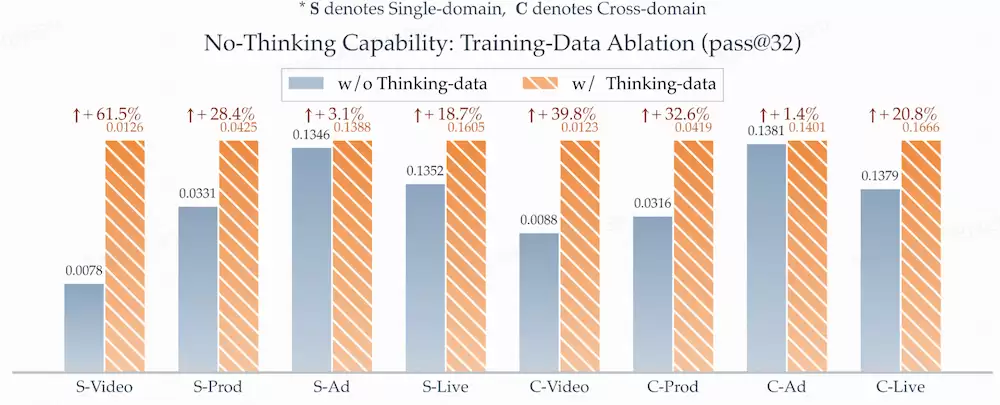
CoT内化效应:用带CoT的数据训练后,关掉thinking模式的直接推荐效果也同步变好——线上non-thinking部署同样吃到了 thinking训练的红利;
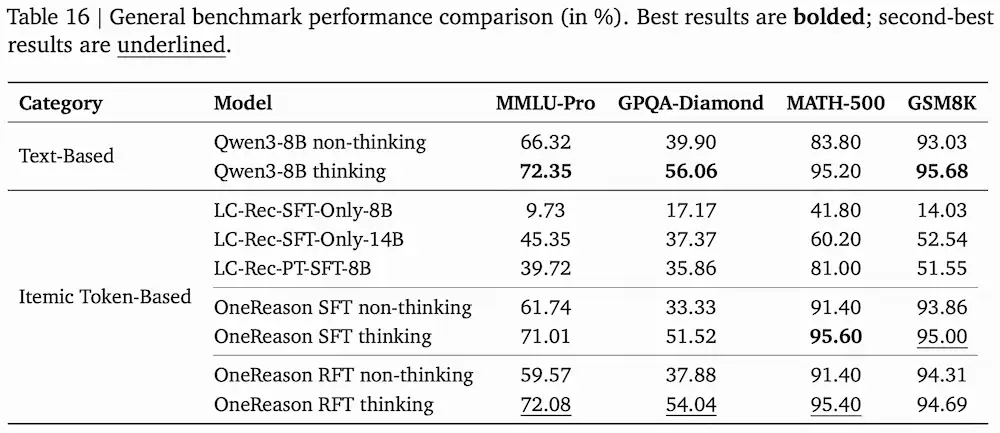
通识能力维持:MMLU-Pro/GPQA-Diamond等基本保留Qwen3-8B原始水平。
到这一步,Q1的CoT设计被真正内化进8B模型的参数里。但实验室效果再漂亮,最终也要回答下一个问题:这套机制能不能在工业系统里跑起来?
04.
推荐大模型
能否在工业场景上线落地?
卡点一:8B模型直接进实时召回,延迟和成本都过不了关
落地场景:快手App生活服务广告场景——高速增长但延迟约束极严的业务。直接把8B量级的OneReason拉到实时召回链路是不现实的——单次推理延迟和GPU成本都过不了关。这是几乎所有大模型上线推荐场景的共性卡点。
解决:Fast-Slow Thinking架构,用近线算力换在线延迟
把Fast(实时)+Slow(近线)解耦,让OneReason在近线慢思考、把结果以候选池形式喂给实时链路:
Slow范式·直接OneReason召回:用户画像+历史交互→OneReason思考→解码成候选list作为慢链路检索输出;
Fast范式·OneReason for OneRec:OneReason输出最相关itemic tokens→转embedding→在OneRec中引入专用Thinking Token承接信号——本质是把OneReason的知识蒸馏注入到在线OneRec。
两条范式机理互补、最终合并使用——慢范式sharpening、快范式broadening。
卡点二:物料每天更新、用户兴趣每天演化,静态模型必然漂移
工业推荐场景的物料库和用户兴趣分布是每天都在变的——一个静态训好的OneReason上线没几天就会失配。这要求模型必须有持续学习机制,但持续学习又会带来灾难性遗忘:每天追新数据,老的通用能力和推理结构就会逐渐被冲掉。
解决:双轨增量训练(防遗忘+跟住分布漂移)
存量Pretrain:滑动时间窗内对新物料持续预训练;混入通用域采样数据防止灾难性遗忘、保住通用推理能力;
增量SFT:每天从用户日志构造日级增量数据,用同日交互作为监督信号,让模型对短期偏好漂移更敏感。
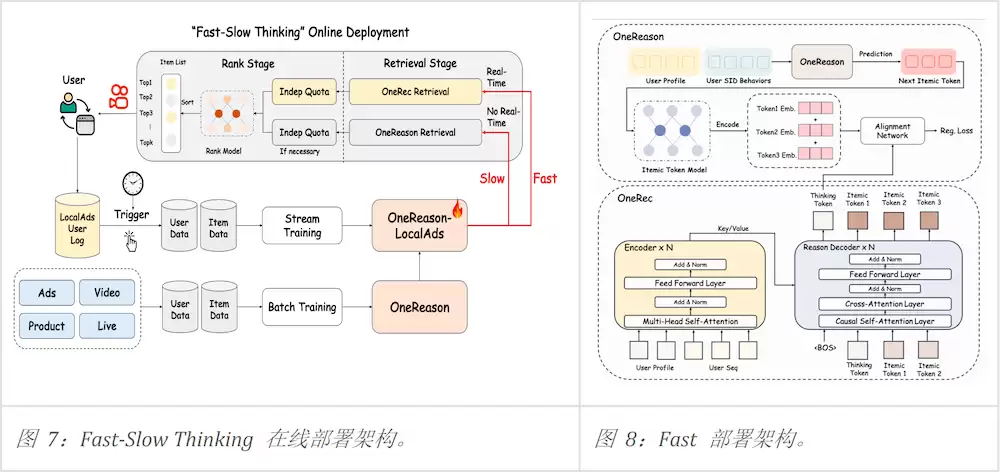
上线收益+双范式机理可分解归因(10天A/B、5%流量、treatment vs control)
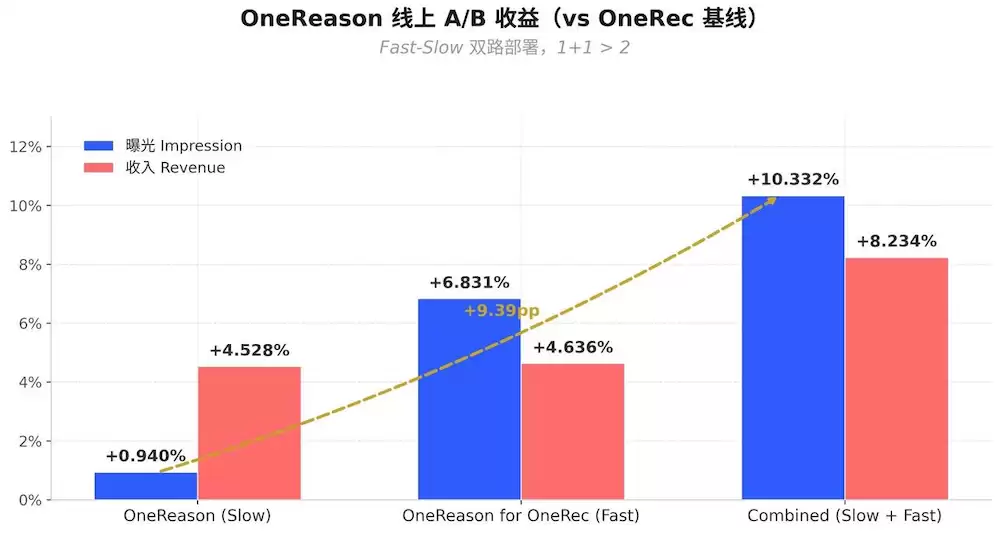
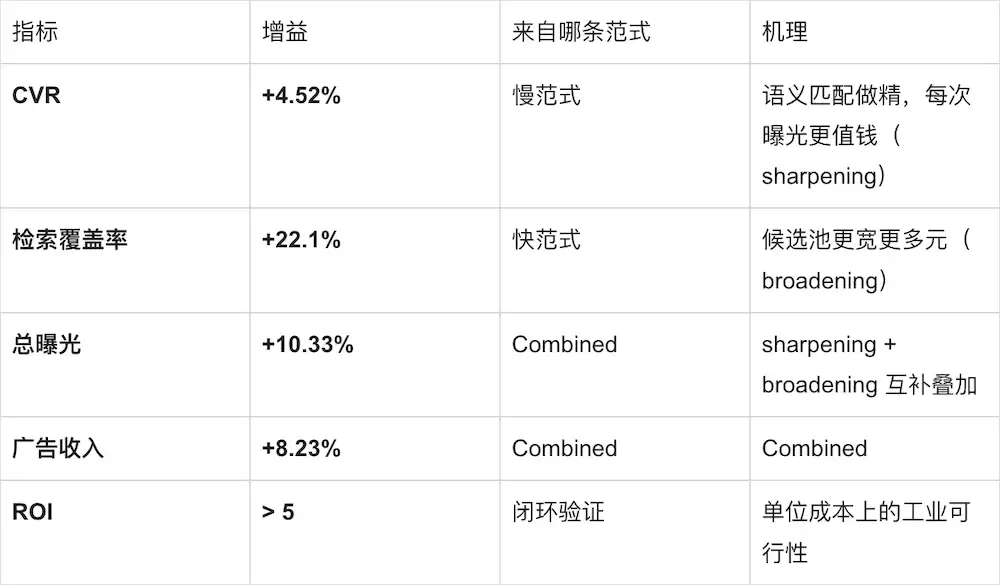
一个sharpening、一个broadening,加起来才是+10.33%/+8.23%这个Combined数——两条范式机理是可分解、可归因的,不是同一来源的简单放大。
工业可行性闭环
三个问题,一份回答
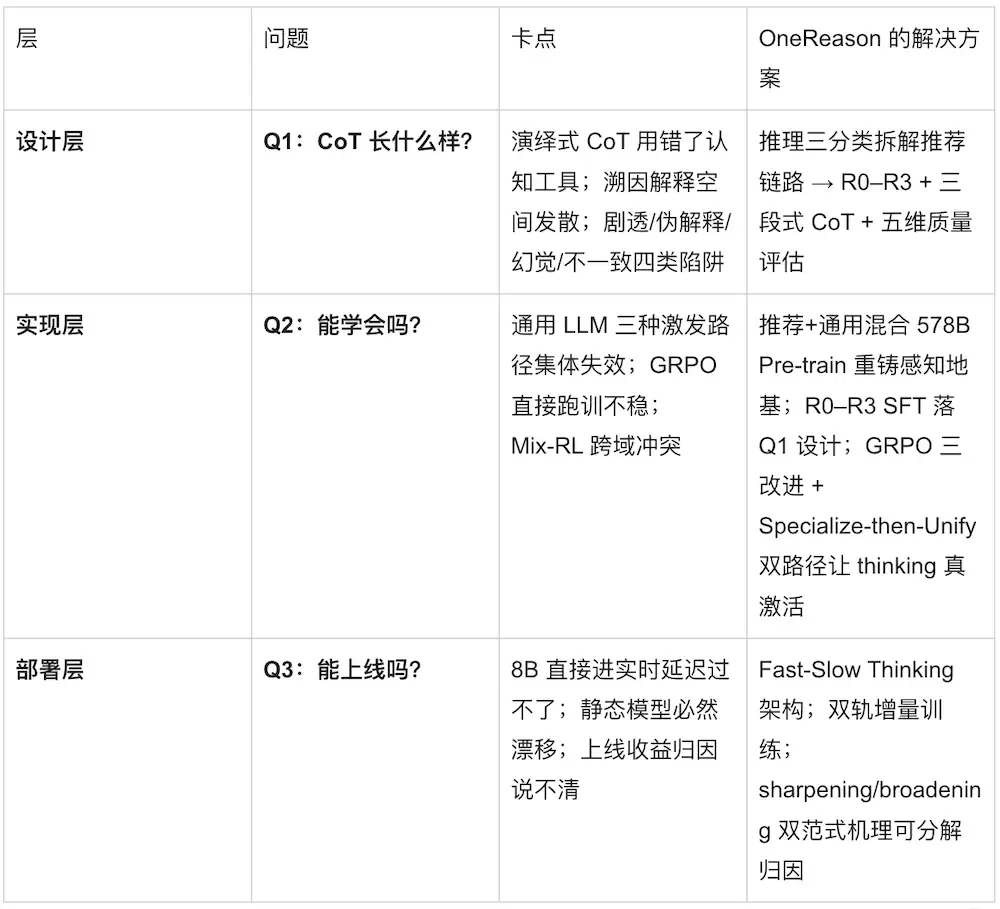
三层合成一条主线:先想清楚思考应该长什么样(What),再去把它做出来(How),最后把它送上业务(So What)
05.
从Scaling到Reasoning
我们已经走通——下一步是Agentic
OneReason把"推荐能不能思考"这件事推进到了CoT增益转正、thinking>non-thinking业内首次稳定成立、Fast-Slow工业落地的阶段。再下一步,我们的判断是Agentic RecSys:模型不再被动接query,而是主动观察→假设→验证→调整→再决策,把推荐的每一次响应当成一个ReAct循环。
推荐推理的可解释、可干预特性,让业务约束可以写在推理层——千人千策、新业务接入只需业务说明即可,策略迭代节奏可以从天级压到更快。这条路上Reasoning不是装饰,而是必备前提——没有Reasoning,Agentic就只剩一个调用工具的壳。
OneRec团队的使命是打造懂世界的推荐模型,寻找算力到用户价值的最优转化方案。欢迎更多志同道合的同行加入我们,做有挑战的事,一同见证推荐系统的未来。
本文相关内容也将在6月13日举办的快手技术沙龙现场进行分享,欢迎对生成式推荐、推荐推理能力以及Agentic Recommender感兴趣的同学到场交流,共同探讨推荐系统与大模型融合的前沿实践。
同时,OneRec团队也将在活动现场正式发布「快手探索者LLM-Rec挑战赛」,面向全球对推荐技术感兴趣的同学开放,邀请大家共同探索推荐系统与大模型深度融合的技术边界,携手打造更懂世界的推荐基础模型。
点击“阅读原文”即可跳转技术沙龙报名。




阅读原文