高通推出骁龙START计划 推动个人AI终端加速落地
2026-06-20 3361915
2026-06-19 0
Developers looking for LLM inference and model serving often turn to Ray Serve, a scalable model serving library with developer-friendly, Python-native APIs built by Anyscale. Combined with Google Kubernetes Engine (GKE), developers have a powerful, unified platform optimized for demanding LLM serving use cases, spanning from initial model development to online production serving.
However, that flexibility and feature set used to come at a cost to performance. But today, in partnership with Anyscale, we are delivering up to 5x higher throughput and 8x lower latency in Ray Serve, meeting the growing demands and rigorous performance requirements of state-of-the-art distributed inference, without having to sacrifice ease of use.
Through our joint engineering partnership, we are introducing three major architectural optimizations that dramatically improve Ray Serve LLM's performance characteristics:
Ray Serve HAProxy integration: Ray Serve now builds in HAProxy to manage internal request routing and load balancing. This setup drastically reduces proxy overhead and prevents the Python runtime from saturating under high traffic.
Direct token streaming architecture: This architecture decouples the initial request path from the return stream. Tokens stream directly from individual model replicas back to the proxy, bypassing the ingress router completely for the streaming data path to cut latency.
v2 Ray executor backend for vLLM: The revamped Ray backend for vLLM moves Ray out of the data plane to enable asynchronous scheduling. This unifies the code path with native vLLM executors, closing the performance gap and helping to ensure Ray users benefit from the latest engine-level optimizations.
We’ve also collaborated with Anyscale to benchmark the updated Ray Serve LLM on GKE clusters utilizing next-generation AI hardware, including Google Cloud A4 VMs powered by NVIDIA HGX B200 systems. We chose to run Gemma 4 E2B as a small, efficient model to isolate bottlenecks introduced from orchestration and routing. Our benchmarks compared the new Ray Serve LLM to its prior performance, as well as a plain vLLM setup using the Ray executor.
These technical enhancements deliver a transformative impact on performance, offering up to 5x higher throughput and 8x better latency compared to previous Ray Serve configurations.
The improved Ray Serve LLM demonstrated a remarkable improvement on a serving cluster with eight replicas, showing a scaling pattern that far exceeds previous performance, and showing comparable performance to running vLLM natively, but without the flexibility that Ray brings to the table.
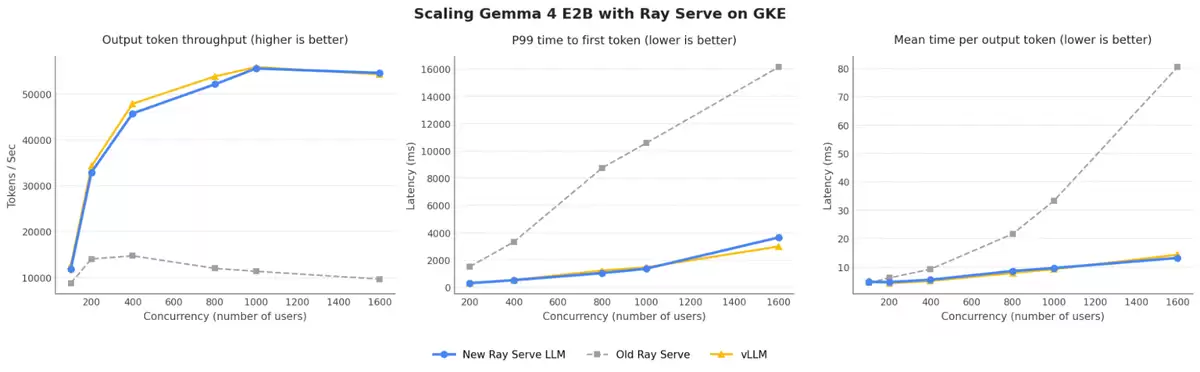
We observe that with an increasing number of concurrent users, Ray is now able to scale up throughput while maintaining a low 99th percentile time-to-first-token, where previously it struggled. Now LLM practitioners don’t have to sacrifice Ray’s rich features and ecosystem to get production-grade performance on Kubernetes.
GKE provides the foundational infrastructure that makes these software optimizations shine. When using the Ray Operator add-on for GKE, you get turnkey deployment across Google Cloud's AI accelerators, including automated horizontal scaling, monitoring, multi-cluster scaling, and built-in fault tolerance. GKE abstracts the complex parts of orchestrating distributed physical hardware, so your team can focus on refining your models and application logic with Ray.
We encourage developers to try out these enhancements in the latest Ray release (2.56 and later) and experience the future of high-performance LLM serving on GKE.
For more details, check out the following resources:
New from Anyscale: High Performance Distributed Inference with Ray Serve LLM
Enable High Throughput on Ray Serve with KubeRay
Serve an LLM with multi-cluster Ray Serve and GKE Inference Gateway
Serve Gemma open models on GKE with Ray